サービス開発部の外村 (@hokaccha)です。
クックパッドのアプリには「料理きろく」という機能があります。 モバイル端末から料理画像のみを抽出して記録することで食べたものが自動的に記録されていくという機能です。

今回はこの料理きろくで画像判定をおこなっているバックエンドのアーキテクチャについて紹介します。なお、実際に判定をおこなう機械学習のモデルのはなしは以下の記事に書かれているのでそちらを参照してください。
料理きろくにおける料理/非料理判別モデルの詳細 - クックパッド開発者ブログ
また、以下のスライドでも料理きろくのバックエンドについて紹介されているのでこちらも参照してみてください。
処理の概要
ざっくりとした画像判定のフローとしては、次のようになります。
- クライアントアプリは端末内の画像を判定用に縮小してサーバーにアップロードする
- サーバーはアップロードされた画像を機械学習を用いて料理画像かどうかを判定する
- クライアントアプリは判定結果を受け取る
クライアントアプリが結果を受け取った後にオリジナルの画像をアップロードしたり、RDBMSにデータを保存するといった処理もありますが、今回は判定処理をクライアントアプリが受け取るまでの流れに絞って解説します。
初期のアーキテクチャ
プロトタイプの段階ではこの処理を単純に料理画像判定用のHTTPのAPIエンドポイントを用意し、そこに画像をアップロードして判定処理を行い、結果をレスポンスで返すという構成で実現していました。
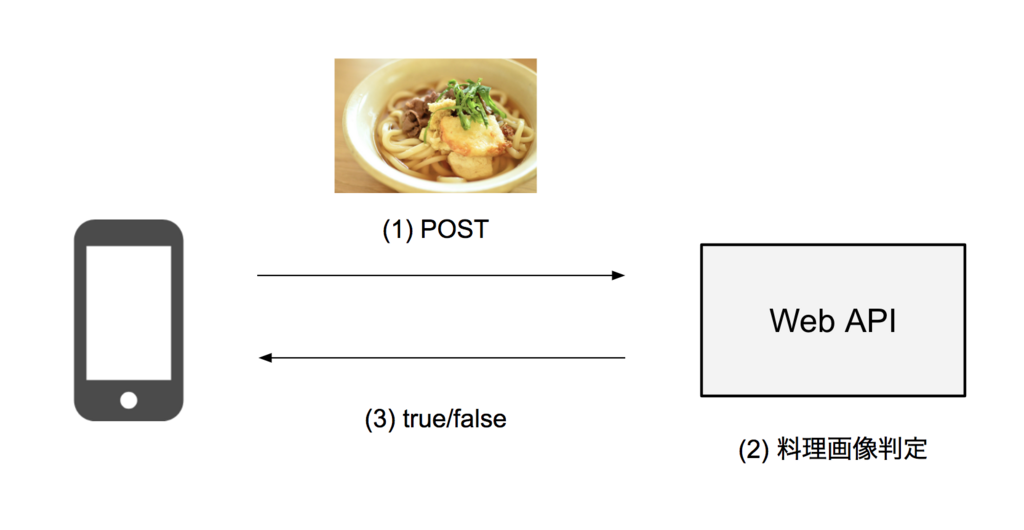
Web APIはRailsとUnicornで動いているサーバーで、その後ろに実際に判定をおこなうPythonのサーバーがたっていてRailsのアプリケーションはそこと通信しています。
この処理は画像アップロードに加えて、料理画像判定の処理にディープラーニングを用いているのでそれなりに重たい処理になります。APIサーバーで利用しているUnicornは仕組み上プロセスがリクエストを処理している間他のリクエストをブロックするため、大量のアクセスがきた場合にI/O待ちによりworkerを使い切ってしまいます*1。
機能の性質上、端末にある画像をすべてアップロードする*2ので利用者が増えると判定の処理が大量にくる可能性は高かったため、アーキテクチャを変更する必要がありました。
現状のアーキテクチャ
そこでシステムの安定性を高めるため、以下のような方法を取ることにしました。
- 画像はAPIサーバーにアップロードせず、S3に直接アップロードする
- サーバー側は料理画像の判定処理をバックグラウンドワーカーで非同期に行う
APIサーバーで重い処理を受けないようにすることでアクセスが集中してもAPIサーバーが詰まらないようにし、バックグラウンドワーカーをスケールアウトさせればサービスがスケール可能になるアーキテクチャを目指しました。
他にもI/O多重化ができるサーバーを導入するであったり、コストを覚悟でUnicornのサーバーをスケールアウトするという方法も考えられますが、今回は社内のノウハウなども加味して一番安定して稼働できそうという判断のもと、このアーキテクチャを採用しました。
最終的な構成としては次のようになります。
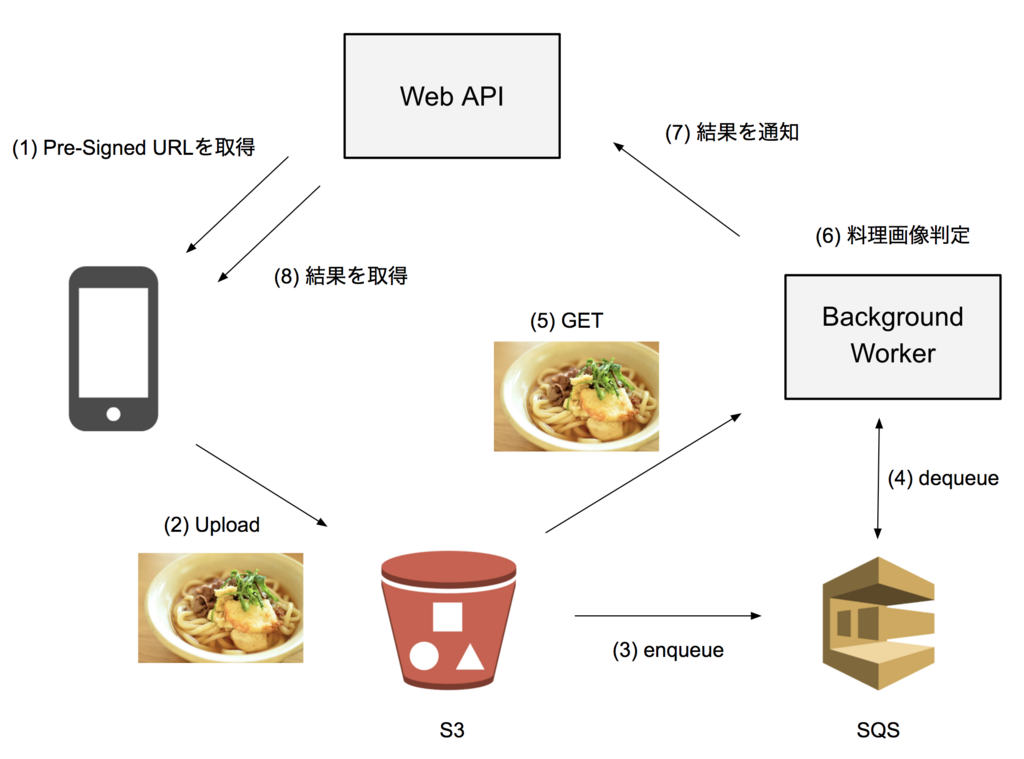
順に説明していきます。
S3に直接画像をアップロードする
まず、画像アップロードの負荷を軽減するため、S3に直接アップロードすることにしました。そのためにS3のPre-Signed URLを利用しています。
Uploading Objects Using Pre-Signed URLs - Amazon Simple Storage Service
クライアントがアップロード処理を開始するときにAPIサーバーにリクエストし(1)、アップロード可能なS3のURLを取得します。このときAPIサーバーはRDBMSにレコードを作成し、アップロードの状態管理を開始します。クライアントアプリは返ってきたURLに対して画像をアップロードすることでS3に画像がアップロードされます(2)。
S3のイベント通知でSQSにエンキューする
S3にはEvent Notificationsという機能があります。
Configuring Amazon S3 Event Notifications - Amazon Simple Storage Service
この機能を使うと、S3にファイルアップロードされたり、変更されるといったイベントが発生されときに、特定のサービスに通知を送ることができます。これを利用し、S3にファイルがアップロードされたときにSQSにエンキューが行われるようにします(3)。
バックグラウンドワーカーの処理
バックグラウンドワーカーはSQSのキューをポーリングしていて、エンキューされたメッセージはバックグラウンドワーカーがデキューすることで処理を行います(4)。
メッセージのペイロードにはS3にアップロードされたオブジェクトのキーなどの情報が入っているので、その情報を元にバックグラウンドワーカーはS3からアップロードされた画像を取得し(5)、機械学習による判定を行い(6)、結果をAPIサーバーにHTTPで送信し(7)、メッセージの処理を完了させます。
このワーカーはPythonで書かれていて、hakoを利用しECS上で動いており、オートスケールの設定もhakoでおこなっています。
結果の取得
最後にクライアントアプリは結果をAPIサーバーから取得(8)してフローは終了です。
ただ、処理を非同期にした場合に難しいのがこの結果の取得です。同期的に判定ができるのであれば、クライアントアプリは判定結果が返ってくるのを待ってから次の処理に進めばいいのですが、非同期の場合はいつ処理が終わるかクライアントアプリにはわかりません。
今回はクライアントアプリが定期的に結果取得のAPIエンドポイントにリクエストすることで結果を取得するようにしています。料理きろくという機能はユーザーが写真を撮って、後で見た時に自動で写真が記録されている、という機能なのでそのケースではリアルタイム性が求められないので数十分に一回程度のリクエストで後から結果が取得できれば問題ありません*3。
ただ、クライアントアプリでそういった処理を定期実行するのは簡単ではなく、様々な苦労がありました。詳しくは料理きろくのAndroidの実装を行った吉田の以下の資料にまとまっています。
まとめ
料理きろくの料理画像判定部分のアーキテクチャについて解説しました。現時点で一日あたり約50万枚以上の画像を判定していますが、大きな問題はなく安定して稼働しています。基本的にはよくあるジョブキューを利用した非同期処理のアーキテクチャですが、S3やSQSはこういったシステムを組むのにとても便利です。
また、最近ではモバイル端末でも機械学習のモデルが動くようになってきています。まだ実用段階まではいっていませんが、それが実現すればこのようなシステムは一切いらなくなり、クライアントの実装も非常にシンプルになるので、できるだけ早く実現してこのシステムがいらなくなる日がくればよいと思っています。





