こんにちは。技術部クックパッドサービス基盤グループの青沼です。当グループではクックパッドのレシピサービスを支える web アプリケーションの改善を進めています。今回はフロントエンドの改善の一環として、 Babel と Rollup を Rails のアセットパイプラインに組み込み、レガシーな CoffeeScript ファイルを ES2015+ の JavaScript に移行した話をします。
レシピサービスと CoffeeScript の歴史
クックパッドは10年以上の歴史を持つサービスです。中でもレシピサービスの web アプリケーションは初期に作られた Rails 2 アプリケーションがアップグレードを重ねながら今も動いています。2018年には Rails 3 から4へ、つい最近では4から5へのアップグレードを完了しました。 Ruby のコードはそれに伴って新しい書き方へと徐々に移行されてきましたが、「壊れていないものは直すな」という言葉もあるように昔から姿を変えていないコードもあります。その一角がビューで使われる CoffeeScript のコードです。
CoffeeScript はいわゆる AltJS (JavaScript に変換される言語)のはしりで、2012年ごろに流行しました。当時の JavaScript は今のように毎年仕様改訂されることがなく、進化が止まったように見えていました。その停滞した空気に新鮮な風を吹き込んだのが CoffeeScript です。Ruby や Python や Haskell から影響を受けた簡潔な記法を取り入れ、リスト内包表記などの新しい言語機能を実装しました。今では JavaScript に取り入れられているスプレッド構文 [1, 2, ...rest] やアロー関数 () => {} は CoffeeScript が実装した機能から影響を受けています。Rails はバージョン3.1から CoffeeScript をフレームワークに統合し、新しい JavaScript コードは CoffeScript で書くように推奨していました。レシピサービスでも CoffeeScript のコードが多く書かれました。
いっときブームを起こした CoffeeScript でしたが、 JavaScript 自体がそれなりに書きやすく進化し、 TypeScript など有力な AltJS が台頭してきた現在では、積極的に採用する理由はほとんどなくなってしまいました。むしろ「JavaScript や AltJS の進歩から取り残されている」「既存のコードを変更するために CoffeeScript を覚える・覚え直すのが面倒」「Rails 自体がもはや CoffeeScript に力を入れていない」などのデメリットが目立つようになっています。
さらば CoffeeScript
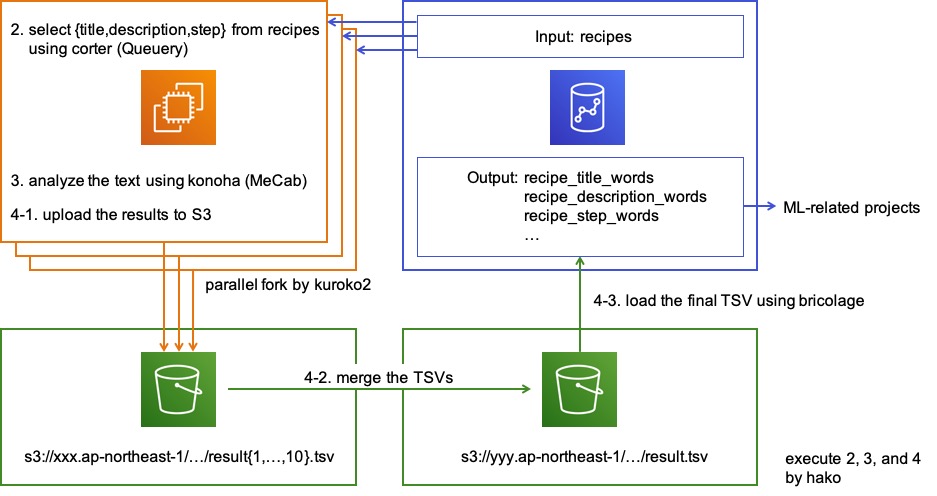
そこで、2019年12月、レシピサービスに残る CoffeeScript をすべて JavaScript に変換することを決めました。元々 JavaScript に変換することが前提の言語ですから、変換自体は特に難しいものではありません。ただし純正のコンパイラの出力はコメント行が残っていなかったりと読みやすさを優先したものではないので、素直で読みやすい JavaScript を生成する別のコンパイラ、 decaffeinate を使うことにしました。(脱 CoffeeScript を支援するツールにデカフェと名付けるセンスがいいですね。)実際にはファイルひとつひとつを手作業で変換していくのではなく、一括変換を実行してくれるサポートツール bulk-decaffeinate を使います。 bulk-decaffeinate は以下の順番で変換対象に指定したファイル群を処理します。
ファイルをエラーなく変換できるかをまずチェック。エラーがあれば中断
ファイルをコピーしてバックアップを作成
拡張子を .coffee から .js に変更して Git にコミット
ファイルを decaffeinate で JavaScript に変換し、上書き保存して Git にコミット
変換後のファイルに ESLint を適用して整形し、上書き保存して Git にコミット
拡張子の変更だけを先に行ってコミットするのは地味ですが重要なポイントです。内容の変更とファイル名の変更を1つのコミットに混ぜてしまうと、 Git は変更前後のファイルの関係を推測できず、変更前のファイルが削除されて新しいファイルが追加されたものとみなします。これではファイルの履歴が途切れたように見えてしまいます。内容の変更とファイル名の変更を別のコミットに分ければ Git はファイルの履歴を正しく推測してくれます。(Git がコミットとして記録するのはファイルツリーのスナップショットだけです。ファイル名が変更されたことを表すデータは存在しません。2つのコミットのスナップショットを比較して、同じかほとんど違いがない別名のファイルがあれば、ファイル名が変更されたとみなして表示します。)
サポートブラウザの問題
2020年1月から、 bulk-decaffeinate を使ってページや機能ごとの単位で徐々に変換を進めていきました。変換後の JavaScript をそのまま使えるなら楽なのですが、残念ながら一筋縄ではいかないことが分かりました。変換作業を行った当時のレシピサービスは InternetExploler 9 をサポートしていたからです。(今では IE 11 までのサポートになりましたが、これでもまだレガシーですね。) decaffeinate が書き出す JavaScriptは IE 9 で動かない ES2015 以降の新しい構文を含みます:
function foo() {
const x = 1;
var y;
for (y of [ 1, 2, 3] ) { ... }
sendAPIRequest('/example' , (result) => {
if ([ 4, 5, 6] .includes(result.items)) { ... }
} );
}
これらを手作業で書き換えることもできますが、人間が新しい構文を見分けるのはミスを起こしがちですし、遠からずサポート対象外になる IE 9 のためだけに古い構文に書き直すのはもったいないものです。なんとか自動的に JavaScript を IE 9 に対応させられないだろうかと考えました。さて、 JavaScript を昔のブラウザに対応するよう変換するといえば Babel の出番です。 Babel を使えば新しい構文をターゲットのブラウザに対応した構文に変換することができます。
ところで、 JavaScript は仕様が改訂を重ねると構文の追加だけでなく新しいクラスやメソッドが追加されることもあります。それらはソースコードの変換で昔のブラウザに対応した形に書き換えることはできません。クラスやメソッドは動的に扱われる(たとえば実行時に組み立てた文字列を名前としてメソッドを呼び出すことができる)ので、ソースコードを静的に解析しただけでは網羅できないからです。昔のブラウザで動かそうとすれば、新しいクラスを再現する polyfill と呼ばれる一群のコードを追加で導入する必要があります。しかしながら、 IE 6 までサポートする巨大な polyfill を丸ごと入れてしまうと web ページのサイズとロード時間に影響してきます。かといって不要なパーツを除外していくのも手間がかかります。
幸いなことに、 decaffeinate が生成したコードで polyfill が必要になるのは Array.includes() ほか少しだけで、1万行のうち数十行程度でした。今回はそこだけ polyfill がいらない形に手作業で書き換えることで対処しました。
Babel をアセットパイプラインに組み込む
話を Babel に戻すと、 JavaScript をいつ Babel で変換するかという問題が出てきます。 Rails は Rails で JavaScript のアセットを変換するアセットパイプラインを持っています。 Rails アプリケーションをデプロイするときにアセットをコンパイルするタスクを実行すると、アセットパイプラインによって入力ディレクトリ以下の JavaScript ファイルが読み込まれ (CoffeeScript ファイルなら読み込んだ後に JavaScript に変換するプリプロセスが行われ)、 JavaScript 同士が結合され、最後に圧縮されて出力ディレクトリに書き出されます。また開発モードで Rails サーバを起動しているときは、入力ディレクトリ以下のファイルが監視され、編集されたアセットは自動的に再コンパイルされます。
この一連の処理に Babel を付け加えるなら、入力ディレクトリ内のファイルを先に書き換えるか、出力ディレクトリ内のファイルを後で書き換えるかです。どちらにせよ開発モードで自動再コンパイルのタイミングと干渉しないようにする必要があり、ちょっと面倒な予感がします。
ここでアセットパイプラインの処理をもう一度よく見てみると、「CoffeeScript ファイルなら読み込んだ後に JavaScript に変換するプリプロセス」が目にとまります。アセットパイプラインにはソースコードを別のソースコードへと変換する処理がすでに組み込まれているのです。この仕組みに乗せてしまえば、ビルドツールを用意しなくても CoffeScript が使えていたのと同様に、 Babel が裏で動いていることを意識しなくてよくなるはずです。
アセットパイプラインに新しい変換処理を組み込むには、 call(input) クラスメソッドを持つクラスを書いて Sprockets.register_postprocessor で登録するだけと、拍子抜けするほど簡単です。実際に書いたのがこのコードです:
module BabelProcessor
BABEL_PATH = Shellwords .escape(Rails .root.join(" node_modules/.bin/babel " ).to_s)
class Error < StandardError ; end
def self .call (input)
data = input[:data ]
if has_babel_pragma?(input)
stdout, stderr, status = Open3 .capture3("#{ BABEL_PATH } --no-babelrc --no-highlight-code " , stdin_data : data)
raise Error , " in #{ input[:filename ]} : #{ stderr}" unless status == 0
data = stdout
end
{ data : data }
end
def self .has_babel_pragma? (data)
%r{\A \s* / [ /* ] \s* @babel \b}x .match?(data)
end
end
Sprockets .register_postprocessor ' application/javascript ' , ::BabelProcessor
BabelProcessor はひとつの変換処理を担当するアセットプロセッサとして振る舞うクラスです。 call(input) メソッドはファイルから読み込まれた JavaScript のファイル名とソースコード文字列を受け取ります。その文字列を babel コマンドの標準入力に渡し、変換後の文字列を標準出力から得て返すだけです。これをアセットパイプラインのポストプロセッサとして登録します。なお、アセットパイプラインのメイン処理で結合された後の JavaScript を扱うため、プリプロセッサではなくポストプロセッサにしています。また変換されることで壊れるコードがないとも限らないので、選ばれたファイルだけを変換するため、先頭に // @babel と書かれたファイルだけを変換するようにしています。
この仕組みはうまく動き、移行作業はスムーズに進みました。 bulk-decaffeinate によって出力された ES2015+ の JavaScript はほとんど修正の必要がなく、1ヶ月程度で合計1万行程度の CoffeeScript をすべて JavaScript に変換することができたのです。
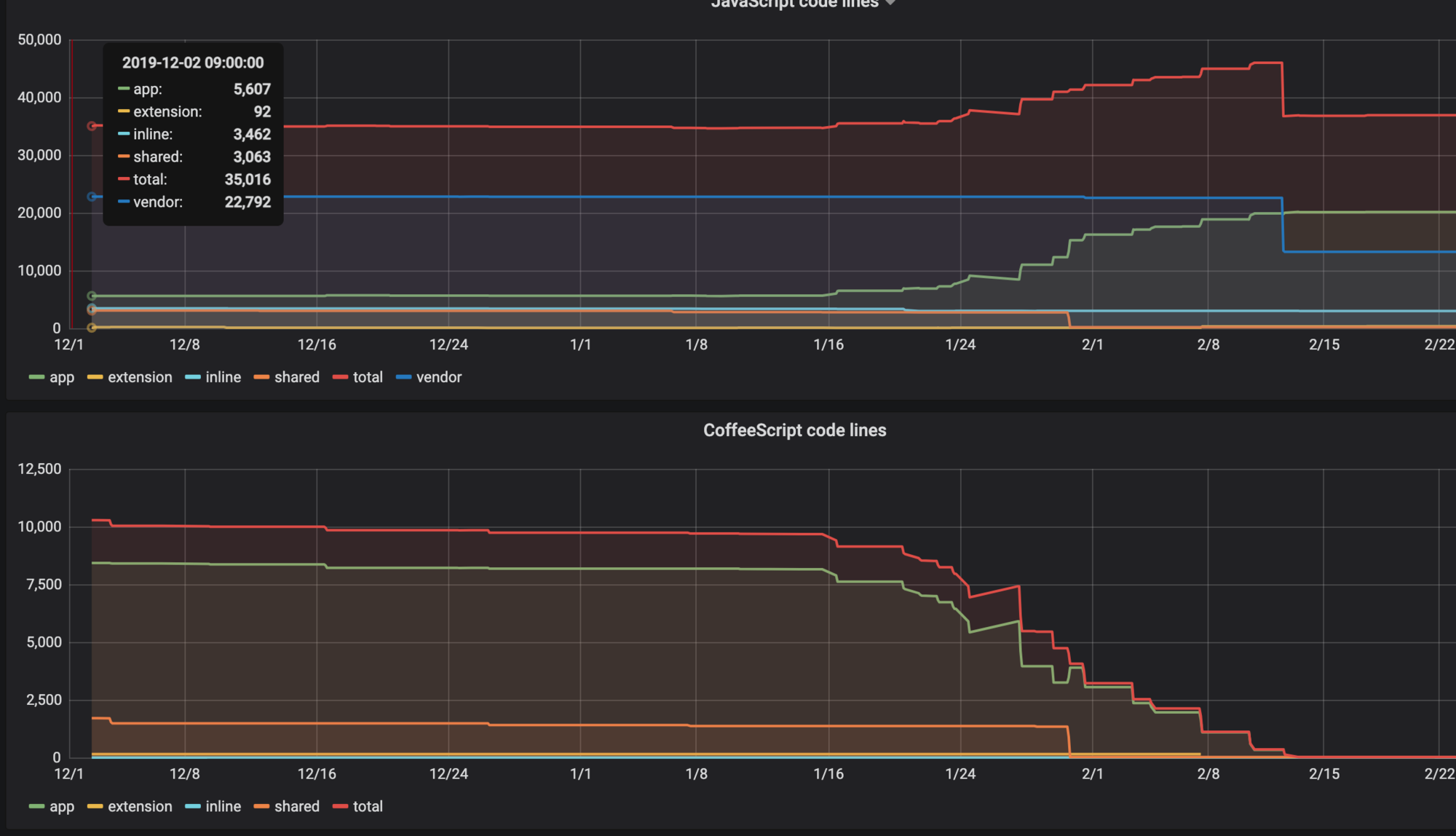
JavaScript と CoffeeScript の行数の変化
CoffeeScript の行数が減るにつれて JavaScript の行数が増えています。(並行して不要な JavaScript を削除する作業も進めていたので2月13日あたりで行数が急激に減っていますが、無関係です。)
Babel から Rollup へ
CoffeeScript と jQuery で書かれていたコードが ES2015 になるともっと欲が出てきます。 Rails 独自の //= require foo.js ディレクティブで文字列的にファイルを結合するのをやめて import 'foo' か require('foo') を使いたいし、 npm でインストールしたモジュールも使いたいし React と JSX でビューを書きたいし、そうなったら TypeScript も使いたい。
Rails 6 に統合された webpack を使えば実現できるのですが、あいにく Rails 4 では動きません。それにレシピサービスはページごとに異なる小さな JavaScript ファイルをいくつも読み込んでいて、コードをひとまとめにバンドルするのが基本の webpack とは相性が悪いのです。たとえば、ビューの部分テンプレートの中で特定の条件のときだけ <script> タグを差し込む以下のような処理が存在します:
. footer
% p ページのフッターです
- if some_condition?
% p 条件に一致したときだけ表示される追加のフッターです
= javascript_include_tag ' optional_footer.js '
この optional_footer.js をバンドルにまとめるとすると、条件に一致するときだけ処理を実行するようにロジックを変える必要があります。ひとつならともかく何十箇所もこんなコードがあるので修正の手間も馬鹿になりません。
なんとかならないかと思っていたら、モジュールバンドラの Rollup がコマンドラインで単一のファイルを変換できることに気づきました。 webpack よりは若干マイナーな存在ですが、つくりがシンプルなぶん設定が簡単で、コマンドとして実行しても動作が速いです。上記の BabelProcessor をベースに、 babel コマンドを呼ぶ箇所を rollup にし、いくつかの処理を加えました。またその処理に対応する Rollup の設定を rollup.config.js に書きました。
require " tempfile "
module RollupProcessor
ROLLUP_PATH = Shellwords .escape(Rails .root.join(" node_modules/.bin/rollup " ).to_s)
ROLLUP_CONFIG_PATH = Shellwords .escape(Rails .root.join(" rollup.config.js " ).to_s)
class Error < StandardError ; end
def self .call (input)
data = input[:data ]
if has_rollup_pragma?(data)
self .build(input[:data ], input[:filename ])
else
{ data : data }
end
end
def self .build (data, filename)
dirname = File .dirname(filename)
Tempfile .create(" cookpad_all_rollup_processor " ) do |temp |
stdout, stderr, status = Open3 .capture3(
{ " COLLECT_MODULE_PATHS " => temp.path },
"#{ ROLLUP_PATH } --config #{ ROLLUP_CONFIG_PATH } - " ,
stdin_data : data,
chdir : dirname,
)
raise Error , " in #{ filename} : #{ stderr}" unless status == 0
module_paths = JSON .parse(temp.read)
dependencies = self .dependencies_from_paths(module_paths, dirname)
{ data : stdout, dependencies : dependencies }
end
end
def self .dependencies_from_paths (paths, base_dir)
node_modules_path = Rails .root.join(" node_modules " ).to_s + " / "
paths.reject do |path |
path == " - " || path.start_with?("\0" ) || path.start_with?(node_modules_path)
end .map do |path |
realpath = File .realpath(path, base_dir)
" file-digest:// #{ realpath}"
end
end
def self .has_rollup_pragma? (data)
%r{\A \s* / [ /* ] \s* @rollup-entry-point \b}x .match?(data)
end
end
Sprockets .register_postprocessor ' application/javascript ' , ::RollupProcessor
import babel from '@rollup/plugin-babel' ;
import commonjs from '@rollup/plugin-commonjs' ;
import resolve from '@rollup/plugin-node-resolve' ;
import fs from 'fs' ;
import path from 'path' ;
const collectModulePaths = {
buildEnd() {
if (process.env.COLLECT_MODULE_PATHS) {
const modulePaths = Array .from(this .getModuleIds());
fs.writeFileSync(
process.env.COLLECT_MODULE_PATHS,
JSON.stringify(modulePaths)
);
}
} ,
} ;
export default {
output: { format: 'iife' } ,
plugins: [
commonjs(),
resolve({
browser: true ,
extensions: [ '.js' , '.jsx' , '.mjs' , '.ts' , '.tsx' ] ,
} ),
babel({
configFile: path.resolve(__dirname, 'babel.config.js' ),
babelHelpers: 'bundled' ,
extensions: [ '.js' , '.jsx' , '.mjs' , '.ts' , '.tsx' ] ,
} ),
collectModulePaths,
] ,
} ;
追加した処理はアセット間の依存関係に関するものです。 Rails のアセットパイプラインでは、 JavaScript のファイルから別の JavaScript を読み込むディレクティブ //= require を書くことができます。たとえば a.js から b.js を読み込むには
console.log('This is a.js' );
console.log('This is b.js' );
と書き、生成される a.js の中身は
console.log('This is a.js' );
console.log('This is b.js' );
になります。このような //= require が書いてある参照元は参照先に(a.js は b.js に)依存することになります。依存関係があることで、開発モードで Rails サーバを起動しているとき、 b.js をエディタで編集すると、 b.js だけでなく参照元の a.js も自動的に再コンパイルされます。
しかし、 Rollup をアセットプロセッサとして使うと依存関係が失われてしまう場合があります。たとえば Rollup で処理される c.js から d.js を読み込むには
console.log('This is c.js' );
import './d' ;
console.log('This is d.js' );
と、 JavaScript の import 文を使うこともできます。アセットパイプラインの視点で見ると、 rollup コマンドに c.js の中身を流し込んだら
console.log('This is c.js' );
console.log('This is d.js' );
が得られたということになります。 Rollup によって d.js がインポートされたことは知る由もないので、 c.js が d.js に依存するという情報は失われます。
そこで依存関係を正しく認識させるために Rollup のプラグインを書きました。 rollup.config.js の collectModulePaths の部分です。 Rollup はプラグインで簡単に拡張でき、ビルドのさまざまなフェーズに独自の差し込むことができます。 collectModulePaths プラグインはビルド後のフェーズでビルド中にインポートされたパスを集めてファイルに書き出します。それをアセットプロセッサ側で読み込み、依存関係データを構築しています。
こうして Rails に Rollup を組み込んだ結果、アセットパイプラインを前提に書かれた既存の JavaScript コードにまったく手を加えることなく Rollup の恩恵を受けられるようになりました。 JavaScript の中で他のスクリプトやモジュールを import することができますし、そうしたければ //= require ディレクティブと混ぜて書くことさえできます。
import React from 'react' ;
import './f' ;
何やら禍々しい見た目ですが、段階的にコードを改善していくには便利な仕組みです。
おわりに
CoffeeScript とお別れした話と、アセットパイプラインの一工夫でフロントエンド開発がちょっとモダン化した話をしました。レガシーな JavaScript コードを抱えた Rails アプリケーションを運用している皆さんの参考になれば幸いです。
クックパッドでは仲間を募集しています!
さて、歴史ある web サービスの改善は地道なものですが、ときにはエキサイティングで急激な変化もあります。クックパッドサービス基盤グループでは、まずスマートフォンブラウザ向けのレシピページから、 Next.js と GraphQL バックエンドを使って一から書き直すプロジェクトを進めています。実はすでに一部のスマホ向けレシピページは Next.js で表示されています。今後もさらに多くのページを改善していきますので、最新の web 技術をバリバリ使ったサービス開発に興味がある方も、レガシーコードをバタバタやっつけたい方も、ぜひお気軽にご連絡ください。
info.cookpad.com