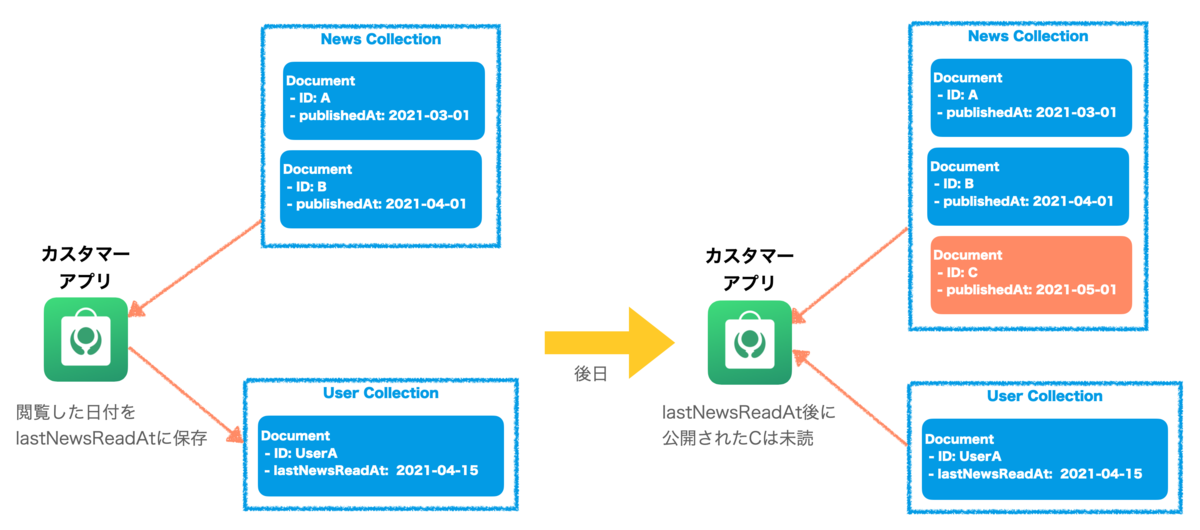
Komercoの高橋です。
昨日は前編でFirestoreの設計パターンについてお話しましたが、後編はFirebase運用の仕組化についてです。
前の記事でも述べたように、昨年はWeb版のリリースや送料無料イベントもあり、ユーザ数がさらに増加してきています。
サービス規模が大きくなるにつれて運用コストも大きくなり、その効率化も求められるようになってきました。
ここではKomercoで行っている、運用に関する仕組みについてご紹介します。
Komercoの構成
まず前提としてKomercoの構成について簡単にご紹介します。
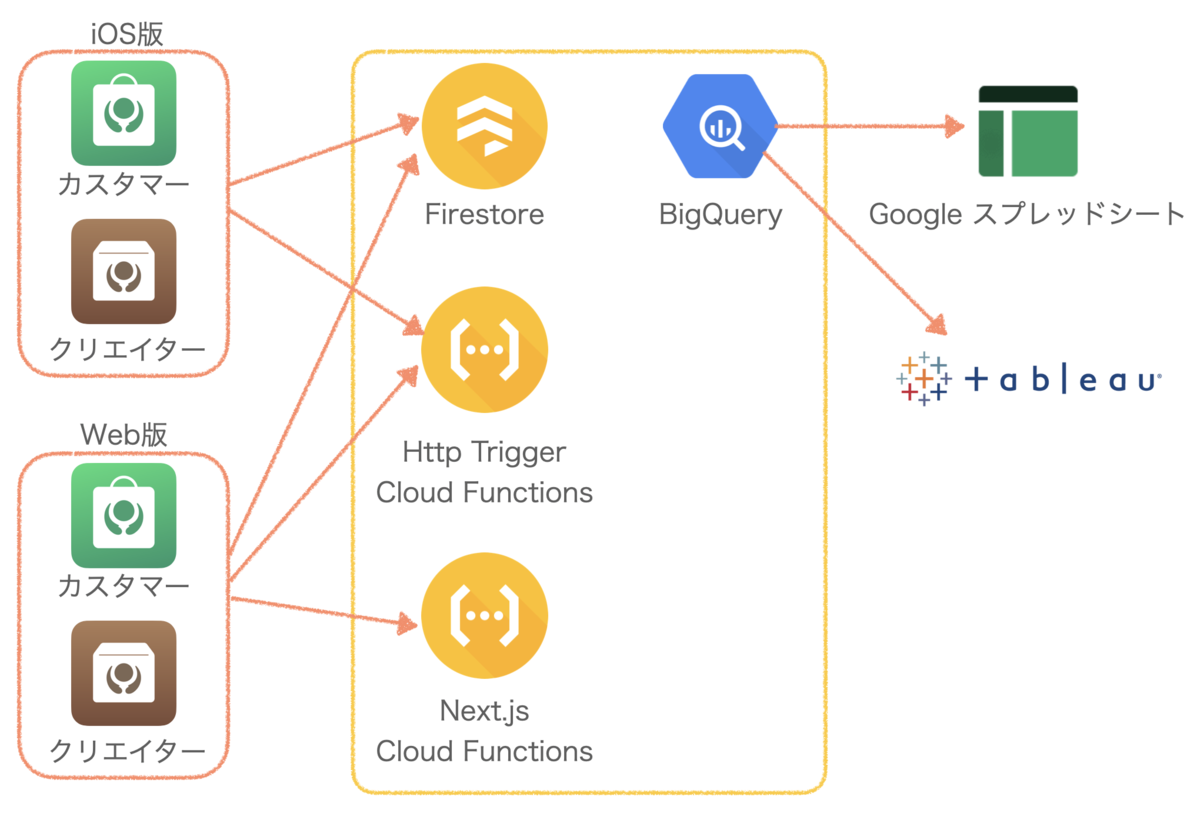
Komercoは器や料理道具、食材や調味料を扱うECサービスで、商品の販売者から直接購入ができるC2Cサービスとなっています。
商品を購入するユーザを「カスタマー」、販売するユーザを「クリエイター」と呼んでいます。
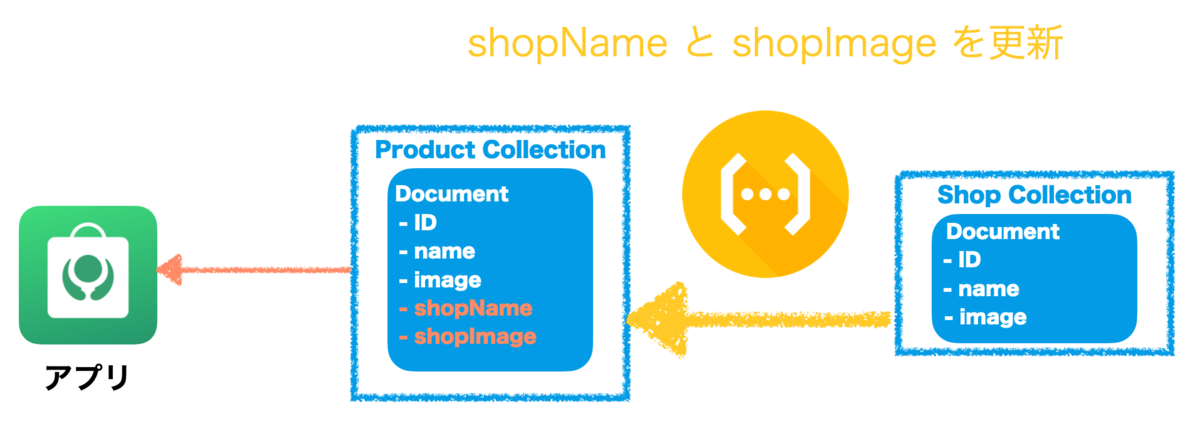
Komercoではこのカスタマー、クリエイターそれぞれに対してiOS版、Web版のアプリを提供しています。Web版についてはCloud FunctionsでNext.jsを動作させて実装しています。
各アプリはFirestoreやCloud Functionsにアクセスしてデータの取得や更新を行います。
Firestoreのデータやユーザの行動ログはBigQueryに貯まるようになっていて、Google スプレッドシートやTableauで分析しています。
もちろん他にもFirebaseの様々な機能を利用しています。
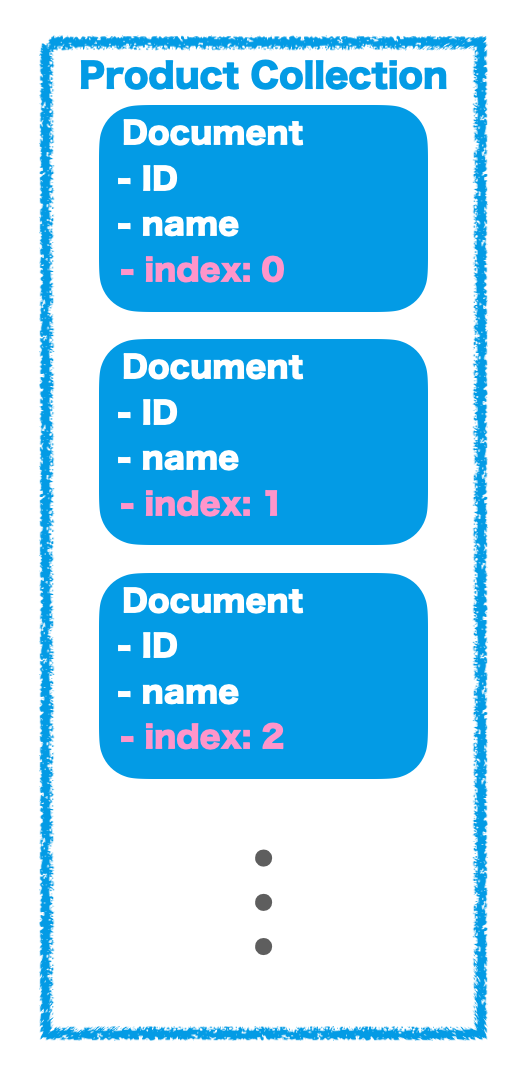
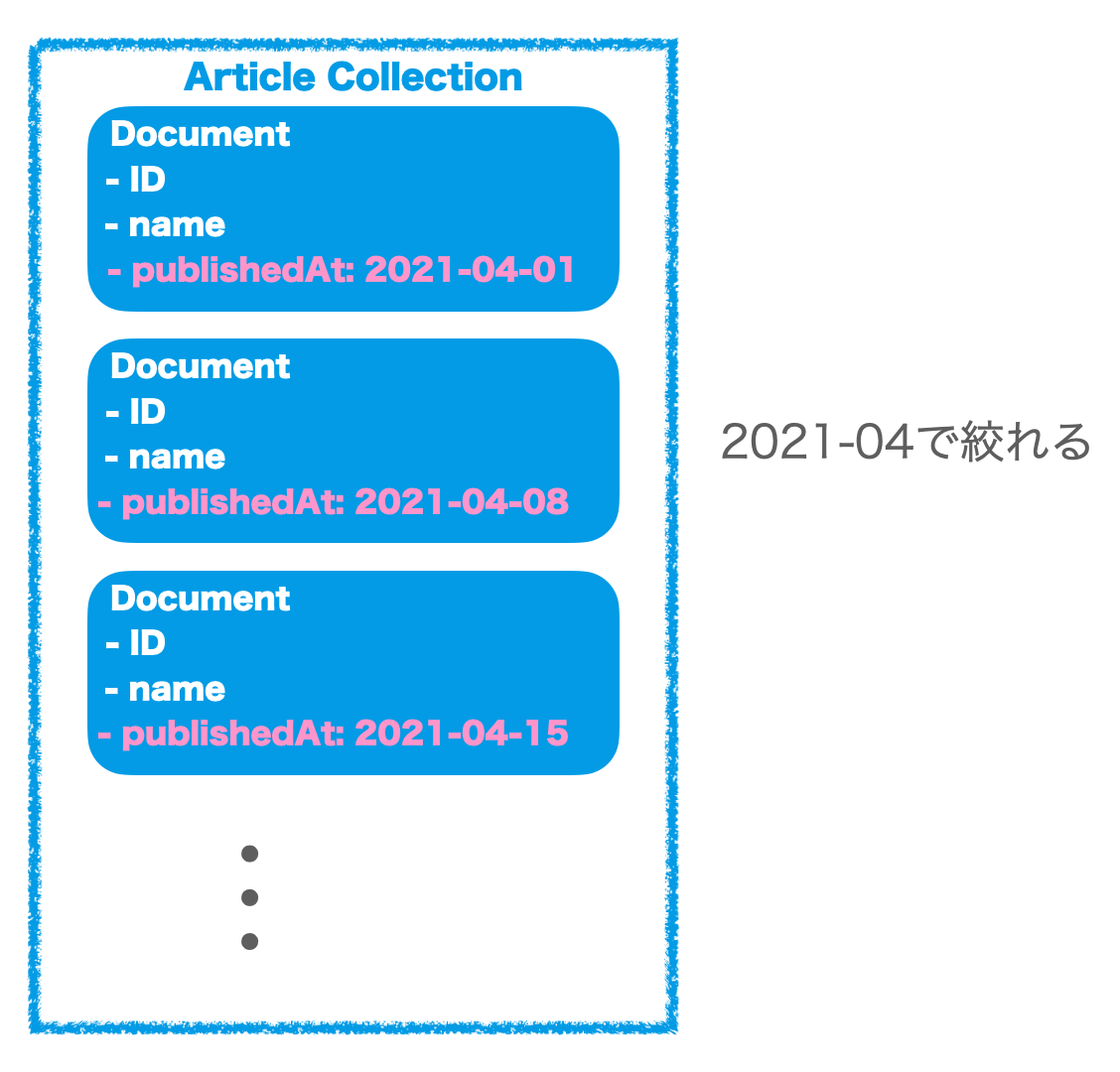
定期的にFirestoreのデータをBigQueryにエクスポート
Komercoでは毎日FirestoreのデータをBigQueryにエクスポートし、分析に使用しています。
Komerco発足時はエクスポートする手段がなかったので独自でツールを作っていましたが、今はgcloudを使ったエクスポート方式に移行しています。
やり方については次の通りです。
サービスアカウントの作成
ここを参考にロールを設定します。
バッチを動かす
バッチで叩くコマンドは次のようになります。
gcloud auth activate-service-account --key-file key.json
gcloud config set project my-firebase-project
gcloud firestore export gs://firestore-export-for-bq/2020-06-29T10:17:23.011+09:00 --collection-ids=user,shop,product
bq load --source_format=DATASTORE_BACKUP --replace=true --projection_fields=name firestore.user gs://firestore-export-for-bq/2020-06-29T10:17:23.011+09:00/all_namespaces/kind_user/all_namespaces_kind_user.export_metadata
bq load --source_format=DATASTORE_BACKUP --replace=true --projection_fields=name,owners firestore.shop gs://firestore-export-for-bq/2020-06-29T10:17:23.011+09:00/all_namespaces/kind_shop/all_namespaces_kind_shop.export_metadata
bq load --source_format=DATASTORE_BACKUP --replace=true --projection_fields=name,price firestore.product gs://firestore-export-for-bq/2020-06-29T10:17:23.011+09:00/all_namespaces/kind_product/all_namespaces_kind_product.export_metadata
projection_fields オプションがあるおかげで、個人情報など取り込みたくない情報はフィルタ可能です。
Dockerfileを使う場合は、gcloudを使うためのGoogle公式イメージがあるので、これを利用するのが便利です。
今からサービス公開するならFirebase Extension
もし今の時点でサービスが未公開の場合はFirebase Extensionを使う選択肢があるかもしれません。
firebase.google.com
こちらの場合、すでにFirestoreに入っているデータについてはエクスポートされないため、今回はgcloudの手法を選択しています。
AuthのデータをGoogle スプレッドシートにエクスポート
ユーザにメールを送りたいときなどに、Authからメールアドレスを抽出する必要があります。
個人の環境でデータを取得するのは情報の取り扱い上問題があるため、バッチでGoogle スプレッドシートに直接書き込むようにしています。
Google スプレッドシートに書き込むことのメリットとして、アクセス管理が簡単なことや、リストのフィルタなどがその場でできることが挙げられます。
サンプルはこちらで、このプロジェクトをバッチで実行します。
https://github.com/yosan/FirebaseAuth2Sheet
ロールバック
Cloud Functionsにはロールバックの仕組みがないため、デプロイ後に不具合が発覚した場合にはもう一度過去のバージョンをデプロイする必要があります。
Web版のKomercoもNext.jsをCloud Functionsで実行している関係上、Hostingのロールバックだけでは意味がありません。
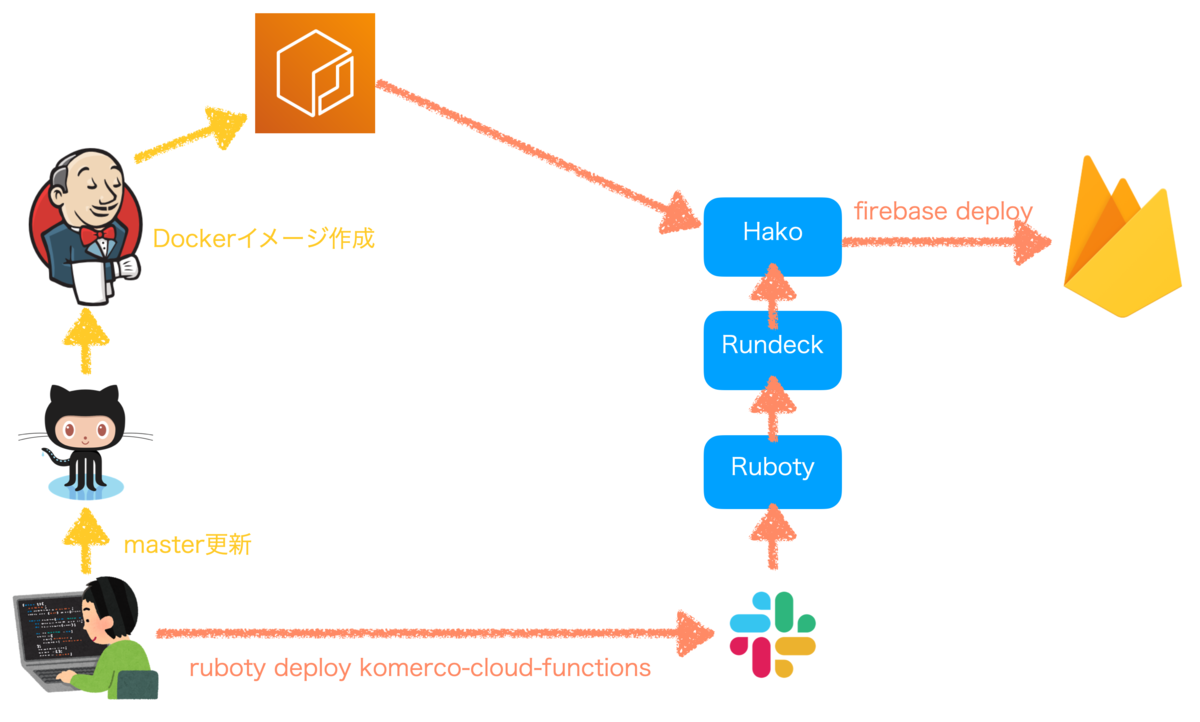
Komercoの本番環境にデプロイする際は、個人の環境からはできず、クックパッドで利用されているRundeck+hakoの仕組みを使ってデプロイしています。
masterブランチに変更が入ると、JenkinsでCloud FunctionsやWebアプリをビルドし、それが入ったDockerイメージをAmazon ECRにプッシュします。
デプロイ時はRundeckからhakoを使うことで、プッシュされたDockerイメージを取得して firebase deploy コマンドを実行します。
Rundeckは基本的にruboty経由で呼ぶため、Slackと上で ruboty deploy komerco-cloud-functions のように発言して指示します。
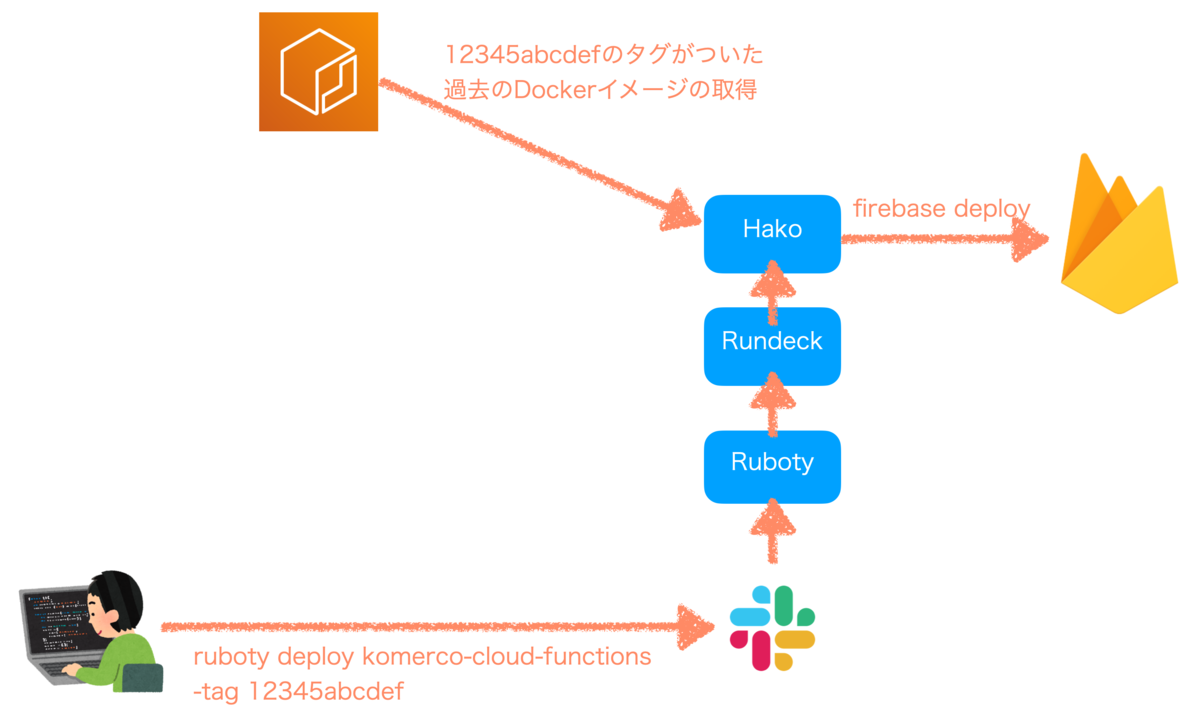
ECRにプッシュされたDockerイメージにはタグがついていて、hakoではこのタグをオプションで指定することで過去のビルド成果物を使ってデプロイができます。
ロールバック時は前回デプロイした際のDockerイメージのタグを特定して、再度デプロイします。
Cloud FunctionsのCI環境改善
サービスの機能が増えるに連れてCloud Functionsの数は増えていき、Komercoでは100を超えるCloud Functionが動いています。
Firebaseの機能拡張が進み、その運用コストも下がってきました。
オフラインテスト
Komercoリリース時点ではFirebaseに関するテスト環境はまだまだ充実していなかったため、CIは実際のFirestoreを使ってオンラインテストを行っていました。
しかしこれにはテスト用のプロジェクトが必要だったり、CIの度にデプロイが必要だったりといろいろ不便な点がありました。
現在ではCIのテストは全てオフラインに切り替わっており、CIにかかる時間は大幅に短縮されています。
テストを実行する際は、firebase emulators:exec コマンドから、FirestoreやCloud Functionsのエミュレータを起動させています。
起動中はAdmin SDKの書き込みは自動的にエミュレータのFirestoreの方を向くため、オンラインテストの実装をほぼそのままオフラインに移行できました。
https://firebase.google.com/docs/functions/local-emulator#interactions_with_other_services
Firebase Admin SDK を使用して Cloud Firestore に書き込む Cloud Functions がある場合、Cloud Firestore エミュレータが実行されていれば、この書き込みはエミュレータに送信されます。この書き込みによってさらに Cloud Functions がトリガーされると、それらは Cloud Functions エミュレータ内で実行されます。
ここで、もともとオンラインで行っていたテストには、
- 単体のCloud Functionsに対して行うテスト
- カスタマーが商品を購入するまでの一連のFirestoreへの操作を再現してテストするシナリオテスト
の2種類がありました。
Cloud FunctionsとFirestoreエミュレータが同時に起動している場合、Firestoreへの書き込み時にFirestore Event TriggerのCloud Functionsがエミュレータ上で発火するようになります。
シナリオテストはこのFirestore Event Triggerの動作も含めて、仕様通りに更新が行われるかをチェックします。
一方で単体のCloud FunctionsのテストにおいてはFirestore Event Triggerは不要で、発火してしまうとテストにかかる時間が伸びてしまいます。
そこで、シナリオテストのみ他のテストとフォルダ単位で分離してテストを別々に実行しています。
シナリオテストの場合のみCloud Functionsエミュレータを起動し、Firestore Event Triggerを発火させてテストします。
Cloud Functions名の定義ファイル
KomercoではCloud Function名やその実体のパス、グループなどが書かれた定義ファイルをfunctionDefinitions.ts として用意しています。
この理由は「Cloud Functions実行時のモジュールの動的ロード」と「同時デプロイ数を制限したフルデプロイ」において、このファイルをimportして使用するためです。
定義ファイルの例です。
type FunctionProperty = {
name: string
module: string
implementation: string
}
type FunctionDefinition =
| ({ type: 'single' } & FunctionProperty)
| { type: 'group'; groupName: string; functions: FunctionProperty[] }
export const functionDefinitions: FunctionDefinition[] = [
{
type: 'single',
name: 'createShop',
module: './shop',
implementation: 'onCreateShopCalled',
},
{
type: 'group',
groupName: 'product',
functions: [
{
name: 'create',
module: './product',
implementation: 'onProductCreated',
},
{
name: 'update',
module: './product',
implementation: 'onProductUpdated',
},
],
},
]
export default functionDefinitions
type はグルーピングされたCloud Functionsか単独かを表します。
name は関数名、 module と implementation が実装先を表します。
Cloud Functions実行時のモジュールの動的ロード
Cloud Functionsは実行時に必要なモジュールのみロードするようにしないと、初回のコールドスタート時の実行時間に影響が出ます。
そこでKomercoでは実行されたCloud Functionsによって、動的にロードするモジュールを切り替える仕組みを入れています。
定義ファイルからCloud Function名と実装先を読み取ってロードします。
import functionDefinitions from './functionDefinitions'
const shouldExport = (functionName: string): boolean => {
const currentFunctionName = process.env.K_SERVICE
return (
currentFunctionName === undefined || currentFunctionName === functionName
)
}
functionDefinitions.forEach((definition) => {
switch (definition.type) {
case 'single':
if (shouldExport(definition.name)) {
exports[definition.name] = require(definition.module)[
definition.implementation
]
}
break
case 'group': {
const groupedFuncs = definition.functions.reduce((previous, current) => {
const functionName = [definition.groupName, current.name].join('-')
return shouldExport(functionName)
? {
...previous,
[current.name]: require(current.module)[current.implementation],
}
: previous
}, {})
exports[definition.groupName] = groupedFuncs
break
}
}
})
フルデプロイ時の書き込み制限問題
サービスが拡充されるに連れてCloud Functionsの数は増え、現在では100ほどのCloud Functionsが作成されています。
Komercoでは本番にデプロイする際は、基本的にmasterブランチにあるFirebaseプロジェクトの内容をすべてデプロイします。
ここで、Cloud Functionsが多くなるにつれて、デプロイの制限にひっかかって頻繁にデプロイエラーを起こしていました。
https://firebase.google.com/docs/functions/manage-functions
多くの関数をデプロイすると、標準の割り当てを超過し、HTTP 429 または 500 エラー メッセージが表示されることがあります。これを解決するには、10 個以下のグループで関数をデプロイします。
そこで定義ファイルから全関数のリストを取得し、最大10個ずつデプロイする仕組みを作っていました。
次のようなデプロイ用スクリプトをTypescriptで実装を作成し、 ts-node で実行してしました。
import { functions } from './src/functions'
const deploy = async (option: { only?: string; except?: string }) => {
let command: string | undefined
if (option.only) {
command = `yarn run firebase deploy --force --only ${option.only}`
} else if (option.except) {
command = `yarn run firebase deploy --force --except ${option.except}`
}
if (command) {
const stdout = execSync(command)
console.log(stdout.toString())
}
}
const main = async () => {
const chunkedFunctions = ...
await deploy({ except: 'functions' })
for (const funcs of chunkedFunctions) {
await deploy({ only: funcs.map(f => `functions:${f}`).join(',') })
}
}
main().catch(e => {
console.error(e)
process.exit(1)
})
Cloud Functionがグルーピングされているされている場合、そのグループのCloud Functionsは一度にデプロイするようにしています。
これは、デプロイにONLYオプションを使う場合に、グループ内で減ったCloud Functionがある場合に自動で削除が可能なためです。
グルーピングされていないものについては自動削除できなそうなので、これからCloud Functionが増えることを考えて初期の段階からグルーピングを使った方がいいかもしれません。
これによってデプロイエラーは無くなったのですが、デプロイに非常に時間がかかるようになってしまいました。
firebase-tools v9.9.0でデプロイのリトライが追加
実はこの記事を書いているうちfirebase-tools v9.9.0がリリースされ、先に述べたデプロイエラーが発生したときに自動的にリトライする仕組みが入りました。そのため現状は一度にデプロイする関数を10個以上に指定しています。
ただし今でも、全て一度にデプロイしようとするとエラーになることがあるようで、引き続きこの仕組が必要になりそうです。
まとめ
Komercoで導入しているFirebase運用の仕組みについてご紹介しました。
こういった仕組み化により、エンジニアは少ないながらも高速に開発ができています。
ご興味ある方は、ぜひ弊社に遊びに来てください。
info.cookpad.com
ここで告知
実は本日4/22(木)から5/5(水)まで春のオンライン陶器市を開催しています。
なんと期間中は送料無料です。
これに加えて、本日からお茶・紅茶・珈琲カテゴリが追加されました!
ぜひこの機会にお買い求めください。
komer.co