海外事業向けのiOSアプリケーション開発を担当している西山(@yuseinishiyama)です。クックパッドは現在、海外複数カ国に向けてサービスを展開しています。
主にObjective-Cで記述されたアプリケーションを全面的にSwiftに書き換える機会があったので、その際に得た知見や書き換えるに至った動機を共有します。
書き換えに至るまでの経緯
この項では、書き換えに至るまでの経緯について説明します。
Objective-C期
アプリケーションの開発は2014年7月頃にスタートしました。Swiftの発表直後でしたが、時期尚早ということもあり、Objective-Cで実装することになりました。
Objective-C、Swift混在期
2014年10月頃から、Swiftへの段階的な移行のために、新規のコードをSwiftで書くようになりました。Swiftの記述力や、ヘッダと実装を行き来しなくて良いことなどにメリットを感じたためです。ここから、Objective-CとSwiftが混在するようになります。
Swift期
Objective-CとSwiftが混在している状態では、後述するSwiftによるメリットを完全には受けることができないと考え、一部を除いてほぼ全てのコードをSwiftに書き換えました。
なぜ書き換えたか
書き換えには、エンバグやスケジュールの遅れなどのリスクが伴ないます。また、新規の言語に対する純粋な興味から、業務で使用する言語を選択することも当然すべきではありません。しかし、それでも尚、書き換えたほうが良いと思われる十分な理由がありました。この項では、その理由について説明します。
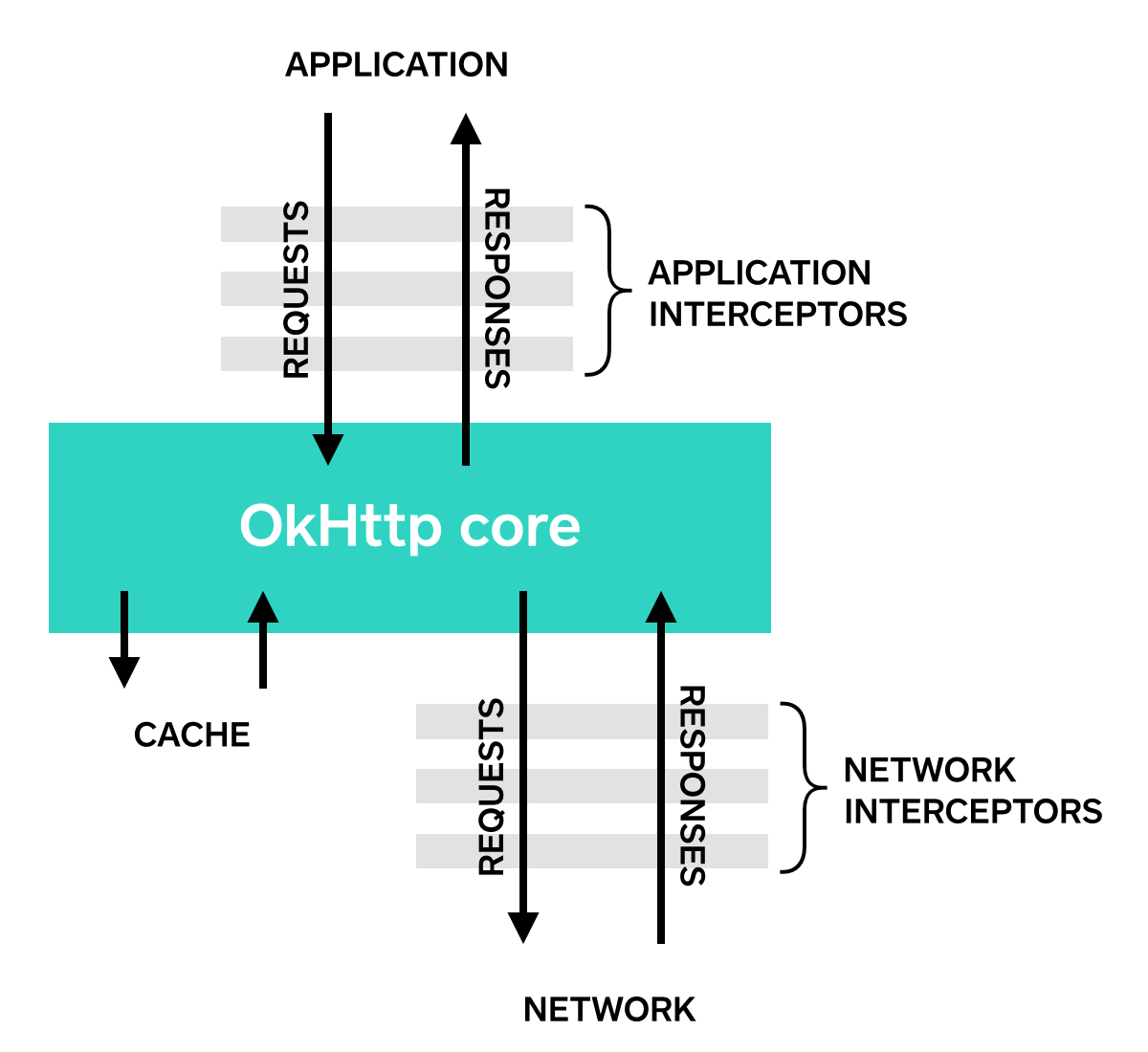
Objective-CとSwiftの混在によって生じる制約
AppleはSwiftとObjective-Cを相互に運用する方法について、詳細なドキュメントを提供しています。しかし、単に相互利用できるというだけで、実際には様々な制約があります。
Objective-CからSwiftを参照する場合、Swift側の一部のコードは参照することができません。Swiftでのenumやstructのような概念はObjective-Cには無いため、これらをObjective-Cから利用することはできません。また、Optional型の利用にも制限があります。例えば、下記のようなクラスとそのプロパティ群があった場合、プロパティaはObjective-Cから参照できますが、プロパティbはできません。
class SampleClass : NSObject {
var a = 0
var b: Int?
SwiftのInt型はObjective-CではNSIntegerとみなされます。SwiftのIntはstructとして宣言されている一方、NSIntegerの実態はプリミティブな型なのでnil値をとることができません。そのため、OptionalなInt型をObjective-Cで扱うことができないのです。このようなケースでnilを許容する数値を使用したい場合は、NSNumberとして宣言せざるを得ません。
以上のような事柄を含め、Objective-Cから利用される限り、Swiftの仕様をフルに生かすことはできず、また、Objective-Cからの利用を意識したコードを書き続ける必要があるということが分かります。
Objective-CからSwiftを参照しないようにする?
前項の問題はObjective-CからSwiftを参照するが故に、起こりうる問題です。極力、Objective-CからSwiftを呼び出さないようなポリシーで混在させるのはどうでしょうか?
確かに、SwiftからObjective-Cライブラリを参照する、SwiftからObjective-Cで記述されたモデルを参照する、などのSwiftからObjective-Cを参照するケースでは、これらの問題を気にする必要はありません。実際、当該プロジェクトでも、当初はビュー関連のコードだけSwiftで記述していたので、Objective-CからSwiftを参照するケースは殆どありませんでした。
Swiftのメリットを享受するには
ところで、Swift化によるメリットを最大限に受けることができるのは、モデルやAPIクライアントです。これらのレイヤーは、Objective-Cにおいては、その動的特性のために、バグの温床となっていました。JSONをオブジェクトにマッピングする際に、予期していた型と違う型が入っていたというようなことは、皆さんも度々経験されているのではないでしょうか。
一方、Swiftでは静的型付けやnullabilityのコントロールによって、これらのバグを解消することができます。長期的に運用されるであろうアプリケーションにおいて、こうした機能を活用してその安定性を高めることには多大なメリットがあります。
しかし、モデルやAPIクライアントをSwiftに置き換えると、それらを呼び出していた既存のObjective-Cコード(主にViewControllerなど)がSwiftを参照することになります。モデルやAPIクライアントをSwiftの機能をフルに利用して実装すると、結局、アプリケーション全体をSwift化する必要がでてくるのです。
Swift化のメリット
前項で、静的型付けやnullabilityのコントロールといった、Swiftのメリットについて簡単に触れました。ここでは、そうしたメリットについて、実際のコードを参照しながら、具体的に述べます。
ジェネリクスの活用
ジェネリクスを活用することで、より安全で表現力の高いコードを記述することができます。ジェネリクスを利用することが好ましい典型的なケースについて説明します。
モデルとAPIクライアントの表現
ジェネリクスを用いて、レスポンスの型を静的に決めることができます。これによって、前述した、予期しない型が代入されることによって生じるバグを防ぐことができます。
まず、単一のAPIを表すためのプロトコルを以下のように宣言しました。ちなみに、現在のプロトコルの仕様ではデフォルトの実装を定義することができないので、プロトコルではなくクラスを採用するという考えも十分に有り得ます。
protocol API {
typealias ResponseType
typealias ResultType = Result<Response<ResponseType>, Response<CommonError>>
typealias ResponseParserType: ResponseParser
var method: Method { get }
var pathString: String { get }
var parameters: [String : AnyObject]? { get }
var parameterEncoding: ParameterEncoding { get }
var responseParser: ResponseParserType { get }
}
そして、準拠しているAPIの実態は以下のようになります。
extension APIs {
class Recipes {
class Get: API {
typealias ResponseType = Recipe
let id: Int
init(id: Int) { self.id = id }
var method: Method = .GET
var pathString: String { return "/recipes/\(id)" }
var parameters: [String : AnyObject]? = nil
var parameterEncoding: ParameterEncoding = .Default
var responseParser = DefaultResponseParser<ResponseType>()
}
class Post : API {
typealias ResponseType = Recipe
let recipe: Recipe
init(recipe: Recipe) { self.recipe = recipe }
(以下省略)
このように記述することで、それぞれのAPIの仕様が一眼で分かります。また、クラスのネストを利用して、APIの階層構造も表現することができます。
次に、APIクライアントのインターフェースです。
protocol APIClient {
(省略)
func sendRequest<T: API where T.ResultType == T.ResponseParserType.ResponseType>(API: T, handler: T.ResultType -> ())
}
ジェネリクスを活用することで、T.ResultTypeとしてレスポンスの型がAPIから一意に決まります。実際にこれらを使用するコードは下記のようになります。
let api = APIs.Recipes.Get(id: 42)
SharedAPIClient.sendRequest(api) {
println("the title is \($0.value?.bodyObject.title)")
}
GET /recipes/:idのレスポンスの型がRecipeであるということが静的に決まります。そして、そのプロパティにtitleがあることもコンパイラは知ることができるのです。
ちなみに、これらの実装に当たっては、MoyaやAPIKitが大変に参考になりました。
Eitherによるエラーハンドリング
Objective-Cにおいて、APIコール時のコールバック関数の型は下記のようなものが一般的でした。
typedef void (^CompletionBlock)(id result, NSError *error);
errorがnilかどうかをチェックし、nilでなければresultを参照して結果を受け取るというパターンです。しかし、resultもerrorもnilになり得る訳で、厳密には下記4パターンが存在します。
|
result == nil |
result != nil |
| error == nil |
? |
成功 |
| error != nil |
失敗 |
? |
この場合、「?」にあたる箇所では、果たしてそのリクエストが成功したのか、失敗したのか分かりません。もちろん、そうならないように実装するわけですが、厳密に起こり得ないことを強制する術はありません。
一方でジェネリクスを使用して、Eitherと呼ばれる2つの可能性を表現する型を実装すれば、より明確に成功と失敗のコンテキストを表現することができます。Eitherの実装に関しては、こちらの実装が参考になります。
public enum Result<T,E> {
case Success(Box<T>)
case Failure(Box<E>)
(BoxはSwiftの値型の制限を回避するために存在しています。詳細については、Boxを参照してください。)
これを利用すると、エラーハンドリングは下記のように記述することができます。
let api = APIs.Recipes.Get(id: 42)
SharedAPIClient.sendRequest(api) {
switch $0 {
case .Success(let box):
case .Failure(let box):
}
}
このようにジェネリクスを活用することで、より厳密なエラーハンドリングを行うことができます。
Enumの活用
SwiftのEnumには計算型プロパティや関数を定義することができます。そのため、Enumの値によって振る舞いを変える場合、その振る舞い自体をEnum側に実装することができます。
enum MyTableViewSection: Int {
case A = 0, B, C, D
var heightForCell: CGFloat {
switch self {
case A:
return 30
case B:
return 44
case C:
return 80
case D:
return 44
}
}
}
func tableView(tableView: UITableView, heightForRowAtIndexPath indexPath: NSIndexPath) -> CGFloat {
return MyTableViewSection(rawValue: indexPath.section)!.heightForCell
}
Objective-Cではswitch文の中が煩雑になりがちでしたが、SwiftのEnumを活用することで、より可読性の高いコードを書くことができます。
Swiftは実用段階か
この項では、新規のプロジェクトをSwiftで始めるべきか、また、既存のプロジェクトをSwift化するべきなのか、ということについての私見を述べます。
Swift1.2の登場
先日、Xcode6.3が正式にリリースされ、このアップデートにはSwift1.2も含まれています。正直なところ、Swift1.2がでるまでは、IDEの安定性、コンパイル時間などに大変な不満があり、Swiftへと移行したことを後悔することもありました。コードを記述すればするほど、ジェネリクスを多用すればするほど、それらの問題が顕著になってきます。しかし、Swift1.2から、これらの問題は大きく解消されています。これらを踏まえると、Swift1.2からはまともに使えるようになった、と言ってもよいでしょう。
Swiftのエコシステム
Swiftのエコシステムには、既に素晴らしいライブラリが存在します。例えば、awesome-swiftのリストが参考になります。
当該プロジェクトでも、すでに下記のSwift製ライブラリを使用しています。
このようにSwiftには既に実用的なライブラリが多く存在し、効率よく開発を進めることができます。
ちなみに、SwiftではStatic Libaryを生成することができず、また、Dynamic FrameworkはiOS8以降でのみのサポートとなっています。当該プロジェクトではiOS7もサポートする必要があったので、Swift製のライブラリはGitのサブモジュールとして管理し、プロジェクトファイル内にソースを直接追加してコンパイルしています。
Swiftに移行するべきか
Swiftに移行することで、以前より、表現力が高く、堅牢なコードが書けるようになりました。アプリケーションが堅牢であることは、他のプラットフォームに比べてリリースサイクルが長くなってしまいがちなiOSアプリケーションにおいて、非常に重要です。
実行時のクラッシュは!を使用して、強制的にアンラップした箇所や、unownedでキャプチャした箇所などに限局されていき、それ以外のクラッシュを招くようなコードは実行前に検出し易くなりました。
このようなメリットを踏まえると、「新規のプロジェクト」や「まだ規模が小さく、長期的に運用されそうなプロジェクト」に関してはSwiftを積極的に選択するべきです。
一方で、「大規模なプロジェクト」をSwift化するのは難しいと感じました。段階的移行といっても、前述のように、モデルやAPIクライアントのレイヤーを書き換えるとなると非現実的な作業量に成り兼ねません。また、新規のコードだけがSwift、というのも悪いとまではいきませんが、Swiftの利点がフルに活用できない点、言語切り替えのスイッチングコストが発生する点などを考慮すると、それほどメリットが無いのではないでしょうか。
おわりに
Swiftはまだまだ発展途上な言語ではあるものの、既に十分な機能を備え、また、そのエコシステムも充実してきています。Swiftの機能を十分に活用すれば、Objective-Cに比べて、保守性が高く、安全なアプリケーションを実装することができるでしょう。この記事が、皆様の新規プロジェクトへのSwiftの採用、またObjective-CからSwiftへの移行の後押しに少しでもなれば幸いです。