研究開発部の菊田(@yohei_kikuta)です。機械学習を活用した新規サービスの研究開発(主として画像分析系)に取り組んでいます。 最近は、社内の業務サポートを目的として、レシピを機械学習モデルで分類して Redshift に書き込む日次バッチを開発・デプロイしたりしてました。
ここ数ヶ月で読んだ論文で面白かったものを3つ挙げろと言われたら以下を挙げます。
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Focal Loss for Dense Object Detection
- Exponential expressivity in deep neural networks through transient chaos
本記事では、BERT というモデルをクックパッドのレシピから得られる日本語テキストで pre-train して、それを fine-tune して特定のタスクを解いた、という話を紹介します。 高いテンションで書いていたらなかなかの感動巨編になってしまいましたが、ぜひご一読ください。
まとめ
- BERT の multilingual モデルは日本語の扱いには適さないので SentencePiece を使った tokenization に置き換えて学習
- pre-training にはクックパッドの調理手順のテキスト(約1600万文)を使用
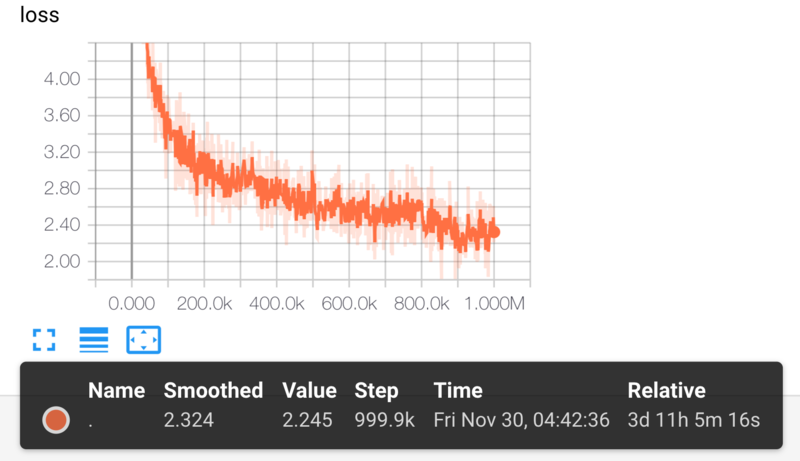
- 学習は p3.2xlarge インスタンスで 3.5 日程度学習を回し、loss は以下の図のように推移(バッチサイズ32)
- 学習済みの pre-trained モデルを基に、手順のテキストが料理の手順であるか否かを予測する問題を解き、以下の表のように良い結果
- (ある程度ドメインを限定すれば)現実的なコストで有用な pre-trained モデルが作れる
pre-training における loss の推移は以下の図の通りです。
classification の結果の表は以下の通りです。
baseline は TF-IDF を特徴量として学習した Logistic Regression と、word2vec による embedding を用いた LSTM です。
multilingual は提供されている学習済みの多言語 BERT を基に fine-tune したモデルです。
our model はクックパッドのデータで学習した日本語用の BERT を基に fine-tune した我々のモデルです。
学習データサイズを変えながら、5477 件の検証データに対する正答率を記しています。
比較は色々と手を抜いていますが、自分たちで学習した BERT が有用であることがひと目で理解できます。
特に、fine-tuning なので少量のデータで良い結果を出せるところが強力で、解きたいタスクがあれば数百件から千件程度 annotation すればよいというのは応用上かなり有用です。
| 学習データサイズ | baseline (LR) | baseline (LSTM) | multilingual | our model |
|---|---|---|---|---|
| 1000 | 87.4% | 90.4% | 88.6% | 93.6% |
| 5000 | 88.9% | 92.2% | 91.6% | 94.1% |
| 13000 | 89.5% | 92.5% | 92.6% | 94.1% |
以降の節では、この結果に辿り着くまでの要素を詳しく解説していきます。
BERT に関する基本的な説明が結構長いので、BERT を理解している人は SentencePiece による tokenization の置き換え の節まで飛ばしてください。
BERT とはどのようなモデルか
まず、BERT とはどのようなモデルかを簡単に説明します。 本記事で注目するモチベーションは、汎用的な pre-trained モデルを提供し、それに基づいて fine-tune したモデルで各種タスクを解いて良い結果を得るというものです。
モデルそのものは Transformer です。 本来は機械翻訳のモデルとして提案されていますが、BERT においては Encoder 部分のみが重要なので、そこのポイントだけを記して詳細は省きます(やや不適切ですが呼称としては Transformer をそのまま用います)。
- sequential な構造を使わずに入力 token 列を一度に処理する(GPU とも相性が良い)
- self-attention によって特徴量を学習する
- 位置情報が落ちる分は position embedding という token 列の位置に応じて与えられる embedding を token embedding に足すことでカバーする
モデルの肝となる self-attention と positon encoding ですが、ウェブ上でも解説が色々落ちてるので説明は割愛します。 実装まで含めて理解したい方は tensor2tensor の実装 よりも harvardnlp が提供している実装 がオススメです。 notebook で提供されていてところどころに可視化も入っているので、具体的に何をしているかを理解するには良いと思います。 ただし、ここで表示されている position encoding の図は dim をいくつか fix して横軸を position にしてますが、embedding の気持ちを考えるなら position をいくつか fix して横軸を dim にした方が良いと思います(ここでやってるみたいに)。
Transformer の話はこれくらいにしておいて、これに基づいて pre-trained モデルを構築した OpenAI GPT の話に移ります。
この pre-training には教師なしで学習できる言語モデル、一言で言うと位置 t-1 までの token が与えられた状況で位置 t の token が正しく予測するように最尤法で学習、を用いています。
イメージ図は以下で、 が各 token の embedding、
が特徴量になっていて、特徴量はさらに一層 dense を重ねてその後 softmax につないで token を予測するようになっています。
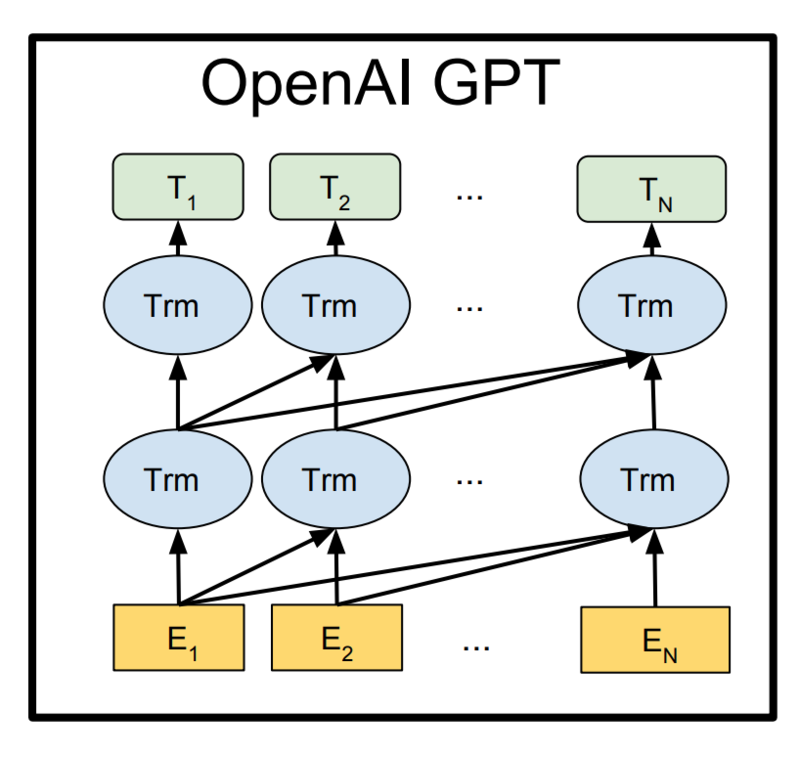
注意すべきは各 layer による connection は前の位置から後ろの位置の方向にしか伸びていない点です。 上述の言語モデルの構造を考えれば、ある位置での token を予測するときにはそれ以前の位置の情報しか使えないので、後ろから前への connection は mask して落とすようにしています。
このモデルは良い結果を残しましたが、明白な改善点として、対象となる token の位置より後ろの位置にある情報も使いたいということが考えられます。
例として 今日は新しく買った〇〇〇でコーヒーを淹れます の ◯◯◯ を予測をすることを考えてみましょう。
これは前の情報だけでは無理がありますが、後ろの情報があればコーヒー豆やコーヒードリッパーなどの可能性が高いことが予想できます。
この点を考慮してモデリングをしたものが ELMo です。
left-to-right と right-to-left を別々に LSTM で学習して得られる特徴量をタスク特有のネットワークの単語 embedding に concat するという使い方をします。
ここで「別々に」というのがポイントで、上述の言語モデルは明らかに一方向でなければ学習が意味を成さないため、別々に学習する必要があります。 しかし、理想を言えば同じモデルの中で双方向の情報を同時に扱いたいです。 同じコンテキストにおいて、前の情報と後ろの情報をその関係性を考慮した上で合わせて使うことができるからです。
これを実現するための言語モデルとして Masked Language Model (MLM) を提案したというのが BERT の貢献です。 話としてはとてもシンプルで、入力 token 列の 15% を mask して、言語モデルは mask されたものを正しく予測するように学習するというものです。 本当はもう少し細かいことをしていますが、難しい話ではなく学習のためのテクニック的な要素でもあるのでここでは割愛します。 具体的な構造はここまでの話が分かっていれば簡単で、下図のように、後ろから前への connection を mask せずに使った Transformer が BERT になります。

これまでは入力部分を何となく token の embedding として扱ってきましたが、BERT の入力の形は少し特殊なのでそれを詳しく見てみます。
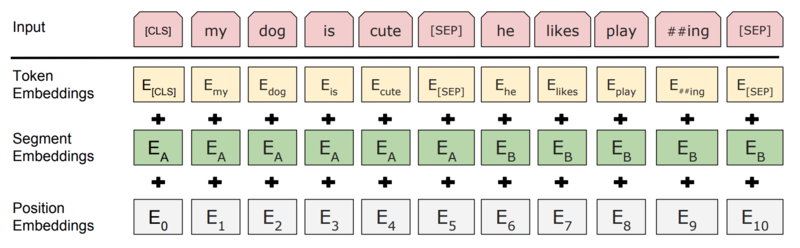
まず、Input から。 最初の token は [CLS] という token ですが、これは MLM においては重要ではないので後で詳しく見ることにして一旦スキップします。 入力の文章は一般に二つ入り得て、間と最後に区切りを明示するためのの [SEP] という特別な token が入ります。 ここで文章と呼んでいるものは一つ一つが一般に複数の文から構成されるもので、例えば質問応答では一つの文章が passage(これは一般に複数の文から成る)でもう一つの文章が question になります。 また、recurrent 構造を持たないので入力 token 列の長さは fix する必要があり、512 token となっています。 入力が長すぎる場合は二つの文章が同じ長さになるように token を後ろから削っていって、余る場合は 0 padding します。
次に Token Embeddings ですが、これは入力 token 毎の embedding です。 embedding は lookup テーブルで実装されるので、入力 token は辞書に基づいてマッピングされた id になります。 pre-training によってこの embedding が学習されることになります。
次に Segment Embeddings ですが、これは token が文章1から来ているのか2から来ているかを区別するために必要なものです。 self-attention は前の layer の出力特徴量を同時に扱うので、位置情報などは知りえません。 位置情報は Position Embeddings で付与していますが、どの token が文章1でどの token が文章2かはまだ区別できていません。 そこで文章1と2を区別する embedding を追加しています。 これは次の Position Embeddings と同様に、文章の内容には依らずに純粋に1つ目の文章か2つ目の文章かだけで定まる embedding です。
Positon Embeddings は元の Transformer と同じ用途ですが、BERT では pre-training で学習するものとして提供しています。 具体的には この辺のコード を参照してください。
ここまでを理解すれば MLM がどうやって実現されるかがかなり具体的にイメージできるようになると思います。 Input の token をランダムに [MASK] という token に置き換え、この [MASK] token に対応する出力特徴量を dense と softmax につないで置き換え前の token の id を当てるように学習します。 これによって文章中のどの位置にどのような token が現れるかを学習できます。
BERT ではさらに文章1と2が意味的に連続している文章かどうかを分類する IsNext prediction によって、文章間の関係性も考慮できるようにします。 これもシンプルで、ある document から連続している2つの文章を抜き出した場合は IsNext で、文章2としてランダムに持ってきた文章の場合は NotNext として、分類問題を解きます。 この分類問題を解く際に、先程登場した文頭の [CLS] token の出力特徴量を dense と softmax につないで解くことになります。
MLM と IsNext prediction によって pre-traned モデルが得られれば、あとはそれを基に fine-tuning によって様々なタスクを解くことができます。 例えば、single sentence classification では、入力を一つの文章として、[CLS] token の出力特徴量に層を追加して分類問題を解くことになります。 その他にも質問応答など色々なタスクを解くことができますが、本記事で扱う fine-tuning タスクはこの single sentence classification のみです。 BERT 論文ではこの fine-tuning で GLUE の各種タスクを解いて軒並み優秀な結果を叩き出しています。
モデルの具体的なパラメタや学習の非効率性の議論を除けば、本質的なポイントはこのくらいです。 これで 3.3 billion word corpus のデータで 256 TPU chip days(ちなみに GCP の cloud TPU では一つのデバイスで 4 chips なのでそれだと 64 日)で学習したものが公開されている pre-trained となっています。
Google Research から 公式実装 が公開されています。 このレポジトリから学習済みモデルもダウンロードできます。 英語、中国語、multilingual のモデルが公開されています。 英語に関してはモデルパラメタ数が三倍程度の Large モデルも提供されていますが、これは試してないので、本記事で BERT と言えば Base の方を想定しています。 以降ではこのレポジトリの内容に基づいて、特に tokenization の手法と日本語で扱うために変更した点に注目して解説します。
BERT の tokenization はどうなっているか
具体的にどのような単位を token とするのか、という話をしていませんでしたが、ここまで述べてきた token は公式実装における sub-token に対応しています。 実装との比較をするため、この節に限り、token と sub-token という言葉を公式実装における変数名に合わせることにします。 繰り返しになりますが、この節以外で使っている token はこの節で言うところの sub-token に対応していることに注意してください。
sub-token とは sub-word のことですが、sub-word と言ってもどのように区切るかは様々な方法があります。 ということで BERT における tokenization を詳しく見てみましょう。
まず、実際に処理をしている部分のコードは tokenization.py で定義されている FullTokenizer クラスの tokenize メソッドです。
class FullTokenizer(object): """Runs end-to-end tokenziation.""" def __init__(self, vocab_file, do_lower_case=True): self.vocab = load_vocab(vocab_file) self.inv_vocab = {v: k for k, v in self.vocab.items()} self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case) self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab) def tokenize(self, text): split_tokens = [] for token in self.basic_tokenizer.tokenize(text): for sub_token in self.wordpiece_tokenizer.tokenize(token): split_tokens.append(sub_token) return split_tokens ...
BasicTokenizer で token に分けてから各 token を WordpieceTokenizer で sub-token に分けていることが分かります。
BasicTokenizer の tokenize は以下のように実装されています。
def tokenize(self, text): """Tokenizes a piece of text.""" text = convert_to_unicode(text) text = self._clean_text(text) # This was added on November 1st, 2018 for the multilingual and Chinese # models. This is also applied to the English models now, but it doesn't # matter since the English models were not trained on any Chinese data # and generally don't have any Chinese data in them (there are Chinese # characters in the vocabulary because Wikipedia does have some Chinese # words in the English Wikipedia.). text = self._tokenize_chinese_chars(text) orig_tokens = whitespace_tokenize(text) split_tokens = [] for token in orig_tokens: if self.do_lower_case: token = token.lower() token = self._run_strip_accents(token) split_tokens.extend(self._run_split_on_punc(token)) output_tokens = whitespace_tokenize(" ".join(split_tokens)) return output_tokens
各々の処理の実装の詳細までは立ち入りませんが、ざっくりと以下のような処理をしています。
- 入力テキストは utf-8 で取り扱う
- unicode category の control のものは除くなどの処理
ord()で各ユニコード文字を int に変換し、範囲指定で漢字を見つけて前後にスペースを入れる- スペース区切りで tokenize して list を返す
このようにして tokenize された token に対して、更に WordpieceTokenizer で sub-token に tokenize します。
抜粋して実際に処理をしている箇所を載せてみます。
output_tokens = []
for token in whitespace_tokenize(text):
chars = list(token)
if len(chars) > self.max_input_chars_per_word:
output_tokens.append(self.unk_token)
continue
is_bad = False
start = 0
sub_tokens = []
while start < len(chars):
end = len(chars)
cur_substr = None
while start < end:
substr = "".join(chars[start:end])
if start > 0:
substr = "##" + substr
if substr in self.vocab:
cur_substr = substr
break
end -= 1
if cur_substr is None:
is_bad = True
break
sub_tokens.append(cur_substr)
start = end
if is_bad:
output_tokens.append(self.unk_token)
else:
output_tokens.extend(sub_tokens)
何をやっているか理解できるでしょうか?
ここで最初の方で渡している text は BasicTokenizer で作られた token になります。
例外処理的な部分を除けば、本質的には以下のような処理をしています。
- まずは与えられた token をそのまま扱う
- token が辞書に存在すればそれを sub-token として登録
- token が辞書になければ最後の一文字を削って sub-token を作って辞書マッチングをする、を繰り返す
- sub-token がマッチしたら、残りの文字に
##ingのように##をつけて同じ処理を繰り返していく
ここの処理は機械的な処理であるため、sub-token の粒度を司るのは辞書となります。
公式レポジトリからダウンロードできる BERT-Base, Uncased の中の vocab.txt を眺めてみると、organizational のような長めの単語が入っていたり、##able のような典型的な接尾辞が入っていたりします。
また、英語以外にも様々な文字が入っていることも確認できます。
30000 程度辞書に登録されているのでかなりの数になっていて、##a なども登録されているので、英語を処理する場合に [UNK] に遭遇することはほぼないでしょう。
例えば The Higgs boson is an elementary particle in the Standard Model of particle physics. という文章を tokenize すると以下の結果が得られます。
['the', 'hi', '##ggs', 'bo', '##son', 'is', 'an', 'elementary', 'particle', 'in', 'the', 'standard', 'model', 'of', 'particle', 'physics', '.']
BERT の multilingual モデルによる日本語の取り扱い
BERT では multilingual のモデルも公開されているので、これを使えば日本語もバッチリ!と期待したいところですが残念ながらそうはいきません。 具体的に tokenization の方法を見てきたので何が起きそうかはある程度想像できると思います。
例えば、鶏肉は包丁を入れて均等に開き、両面にフォークで穴を開け塩コショウする。 を tokenize すれば結果はどうなるでしょうか?
正解は以下のようになります。
['鶏', '肉', 'は', '包', '丁', 'を', '入', 'れて', '均', '等', 'に', '開', 'き', '、', '両', '面', 'に', '##フ', '##ォ', '##ーク', '##で', '穴', 'を', '開', 'け', '塩', 'コ', '##シ', '##ョ', '##ウ', '##する', '。']
ほとんど文字ベースみたいなものですね...
漢字もしくはスペースによってある程度の単位に区切られること前提としているので、日本語は相性が悪いです。
これは漢字がところどころに含まれているのでまだマシですが、例えば にフォークで の部分はこれがまとめて WordpieceTokenizer で処理されるのでこのようになってしまいます。
さらに vocab.txt を見てもまともな日本語の単語が登録されていないことが分かります。
使う気になれば文字ベースのモデルとして使えますが、あ と ##あ を区別しているなどなかなか厳しいものになっています。
SentencePiece による tokenization の置き換え
日本語にマッチした BERT モデルを作るには、tokenization を日本語にマッチしたものに変える必要があります。 英語版と同じように sub-word 単位で取り扱いをすることを考え、今回は SentencePiece を使用することにしました。
SentencePiece は教師なしで学習可能で、そして学習が速いです。ほんと速い。 SentencePiece が提供する言語モデルベースの分割や detokenization などの詳細はここでは触れないので、本家のレポジトリや 論文 をご覧ください。
ここでは tokenizer の置き換え部分を軽く紹介します。
まず、BERT の元のコードの FullTokenizer クラスを次のように変更します。
class FullTokenizer(object): """Runs end-to-end tokenziation.""" def __init__(self, model_file, vocab_file, do_lower_case=True): self.tokenizer = SentencePieceTokenizer(model_file) self.vocab = load_vocab(vocab_file) self.inv_vocab = {v: k for k, v in self.vocab.items()} def tokenize(self, text): split_tokens = self.tokenizer.tokenize(text) return split_tokens ...
これは単純に tokenize メソッドを SentencePieceTokenizer での処理に変更しているだけですね。
SentencePieceTokenizer クラスは次のように定義します。
class SentencePieceTokenizer(object): """Runs SentencePiece tokenization (from raw text to tokens list)""" def __init__(self, model_file = None, do_lower_case=True): """Constructs a SentencePieceTokenizer.""" self.tokenizer = spm.SentencePieceProcessor() if self.tokenizer.Load(model_file): print("Loaded a trained SentencePiece model.") else: print("You have to set the path to a trained SentencePiece model.") sys.exit(1) self.do_lower_case = do_lower_case def tokenize(self, text): """Tokenizes a piece of text.""" text = convert_to_unicode(text) output_tokens = self.tokenizer.EncodeAsPieces(text) return output_tokens
これも難しいことは何もなくて SentencePiece の SentencePieceProcessor クラスの EncodeAsPieces メソッドを使っているのみです。
学習済みモデルさえ別途準備できれば、この程度の変更で置き換えが可能です。
ここまでで必要な道具が出揃ったので、あとはデータを準備して実際に学習をしていきます。
使用するデータ
クックパッドには 300 万品を超すレシピが投稿されています。 レシピには調理手順毎に説明の文章が付与されているので、今回はこの手順のテキストを学習データにします。 手順のテキストは十分なデータ量があること、手順のテキストには材料や調理器具や調理法などレシピの分析に必要な要素が含まれていること、などが理由です。
一つの手順のテキストを一行に格納したデータを作成した結果、約 1600 万行のテキストデータとなりました。
まず、SentencePiece の学習データですが、これは扱いが簡単で、学習時に作成したテキストデータの path を与えるだけです。
この規模のデータでも MacBook Pro で一時間程度で学習が終わるので、かなり使いやすいです。
今回は unigram モデルを使い、vocab_size は 32000 としました。
vocab_size がかなり大きめですが、これは後の BERT の学習を考慮し、BERT の英語モデルにおける辞書の要素数と同じくらいにするという意図で設定しました*1。
学習したモデルで先ほどと同じ例を tokenize してみると、以下の結果が得られます。
vocab_size が大きいので token も大きめになっていますが、クックパッドっぽい token に分かれてますね〜。
['▁鶏肉は', '包丁を入れて', '均等に', '開き', '、', '両面に', 'フォークで穴を開け', '塩コショウする', '。']
次いで、BERT の pre-training の学習データです。
create_pretraining_data.py によって、テキストデータに [MASK] や IsNext の情報などが付与された後に .tf_record 形式に変換されます。
テキストデータは IsNext 情報の作成のために、一行一文でかつ document 間には空白行を挿入することが推奨されています。
先ほど使ったテキストデータを、一つのレシピが一つの document になるようにして間に空白行を挿入し、一行には一手順のテキストを入れるように作りました。
後はこのスクリプトを学習した SentencePiece の tokenization に基づいて実施すれば必要な学習データが作成できます。
ただし、このスクリプトは全データをメモリに読み込む仕様になっているので、大量のデータではメモリ不足になってしまいます。
後の pre-training では複数のファイルを学習データとできるので、ここでは 1/10 ずつ .tf_record を作りました(一つのファイルが約 2 [GB])。
どれくらいデータを複製するかなどの各種パラメタは、公式レポジトリのものと揃えています。
ここで vocab.txt は少し注意が必要です。
SentencePiece が出力する .vocab ファイルには存在しない [PAD], [CLS], [SEP], [MASK] などを編集して追加し、それに合わせて vocabulary を扱う関数を少し変更する必要があります。
こうすると SentencePiece のモデル内部が有する token:id のマッピングとズレが生じるので少しイケてないですが、モデルは純粋に tokenize をするためだけに使われるので問題は生じません*2。
最後に、fine-tuning タスク用のデータも準備しておきます。 今回は手順のテキストが料理に関するものか否かを二値分類するタスクを扱います。 手順のテキストには「つくれぽありがとうございます」というような、料理に関するものでないテキストが含まれる場合があります。 例えば音声による手順の読み上げを考えた場合、このような料理に関するものでないテキストまで読み上げられるのは望ましくないため、自動で分類することは価値があります。 過去に annotation された 18477 件のデータがあったため、13000 件を学習データ、残りの 5477 件を検証データとして使用します。
BERT の pre-training
学習は AWS EC2 p3.2xlarge に nvidia-docker 環境を構築して実施しています。
nvidia/cuda:9.0-cudnn7-devel-ubuntu16.04 と tensorflow-gpu==1.12.0 を使っています。
この環境では計算機パワー不足では?と思われるかもしれませんが、料理というドメインに限定したデータを対象としており、予備実験をして様子を見てもいけそうだったので、これで学習を回しました。
モデルのパラメタは BERT の英語モデルのものと基本的に同じで、vocab_size を合わせて、learning_rate=5e-5、train_batch_size=32、max_seq_length=128 で回しました。
以降の結果はステップ数が 1,000,000 回における結果です。
学習経過の確認として、loss の振る舞いを見る以外にも、適当なタイミングで学習を止めて fine-tuning タスクを解いてその性能が向上していることなども確認していました。
loss の推移は下図の通りです。
pre-train したモデルの性能は以下のようになりました。
INFO:tensorflow:***** Eval results ***** INFO:tensorflow: global_step = 1000000 INFO:tensorflow: loss = 2.1979418 INFO:tensorflow: masked_lm_accuracy = 0.5468771 INFO:tensorflow: masked_lm_loss = 2.1357276 INFO:tensorflow: next_sentence_accuracy = 0.9775 INFO:tensorflow: next_sentence_loss = 0.061067227
公式実装の pre-trained モデルと比べると masked_lm_accuracy の値が低くなっています(これは多クラス分類なので 54.7 % は全然当てられてないわけではないです)。
手順のテキストには記号も結構な割合で含まれていて、これは当てるのが困難というのも影響していると思います。
とはいえ masked_lm_loss がまだまだ下がりそうなのと token 列が長い場合の positon encoding の学習もしてないので、引き続き学習を継続して様子を見ていきたいと思います*3。
次節の二値分類タスクは、この pre-trained モデルを基に fine-tune した結果となります。
二値分類タスクによるモデルの比較
準備した fine-tuning 用のデータを用いて、各種モデルを比較してみました。 使用したモデルは以下のものです。
- baseline (LR): TF-IDF を入力とする Logistic Regression を fine-tuning 用の学習データのみで学習したもの
- baseline (LSTM): word2vec の embedding を入力とする LSTM を fine-tuning 用の学習データのみで学習したもの
- multilingual: 公式レポジトリで提供されている multilingual モデルを fine-tune したもの
- our model: 今回作った pre-trained モデルを fine-tune したもの
fine-tuning の有用性を確認する上でも、学習データサイズを変えながら試した結果が以下の表です。
| 学習データサイズ | baseline (LR) | baseline (LSTM) | multilingual | our model |
|---|---|---|---|---|
| 1000 | 87.4% | 90.4% | 88.6% | 93.6% |
| 5000 | 88.9% | 92.2% | 91.6% | 94.1% |
| 13000 | 89.5% | 92.5% | 92.6% | 94.1% |
有用性を確認するためだけの比較実験なので、色々と雑にやっていますが、自分たちで学習したモデルが良い結果を返していることが分かります。 特に、学習データサイズが小さくてもかなり良い結果を返していることが分かります。 それほど難しくないタスクなので baseline も悪くない結果を出していますが、学習データサイズが小さい方が差が大きくなっています。 これはドメインを限定したクックパッド用の pre-traiend モデルを使っているので期待通りの振る舞いですが、この事実は社内における機械学習を用いたサービス開発に有用です。 試したいタスクがあれば千件程度の annotation されたデータがあれば十分であることを示唆しているので、社内の annotator の方々に依頼すれば数日で結果を出すところまで確認できます。 ちなみに fine-tuning に要する時間は数分とかその程度です。 pre-trained モデルと SentencePiece のモデルが準備できた現状ならば、色々なタスクにすぐに試すことができるので、trial and error を高速に回せるので嬉しいですね!
CPU では学習は厳しいですが、予測に関しては数千件であればバッチ処理で使うのも可能な程度の処理速度なので、その用途なら他の機械学習モデルと同様の運用コストで使っていけます。 処理件数が多かったりスピードが要求される場合はやはり GPU(もしくは TPU)が必要になります。
今後は、引き続き pre-training を回して性能をチェックしつつ、BERT の特性を活かして様々なタスクに適用していきたいと考えています。
本節における baseline の結果を出すのには @studio_graph3 にも手伝ってもらいました。スペシャルサンクス。
再びまとめ
だいぶ長くなりましたが、BERT with SentencePiece で日本語専用のモデルを作って、そこから fine-tune してタスクを解く話をしました。 ドメインが限定されれば single GPU でも十分に有用なモデルが構築できるのではないかと思います。 pre-trained モデルが得られれば、少量の annotation さえあれば高い性能を発揮するので、サービスに導入するために様々な trial and error を実施しやすいというのは大きな利点です。
また、本記事では紹介しませんでしたが、Google Colaboratory を使えば無料で TPU を使って BERT を試すこともできます(結果ファイル出力に GCS が必要ですが)。
いかがでしたでしょうか。 このように弊社では機械学習の新しい発展を活用してサービスの研究開発がしたい、という方を募集しています。 興味がある方は @yohei_kikuta までご連絡ください、クックパッドで美味しいご飯でも食べながら議論しましょう。 もしくは 応募フォーム から直接ご応募ください。