研究開発部の原島です。今日は表題の渋いバッチをつくった話をします。
あっちでも形態素解析、こっちでも形態素解析
みなさん、形態素解析してますか?してますよね?クックパッドでもさまざまなプロジェクトで形態素解析をしています。
いや、むしろ、しすぎです。プロジェクト A でレシピを解析し、プロジェクト B でもレシピを解析し、プロジェクト C でもレシピを解析し、... といった具合です。ちなみに、形態素解析(の結果)が必要なプロジェクトとしてはレシピの分類やレコメンド、各種分散表現(e.g., word2vec)や BERT の学習などがあります。
もちろん、最終的に得たい解析結果が違うのであれば問題ありません。しかし、私が見たかぎり、ほとんどの場合は同じ(もしくは、同じにできそう)でした。であれば、
- 解析器をインストール(→ Dockerfile を試行錯誤)
- 解析対象を取得(→ SQL を試行錯誤)
- 解析器を実行(→ クックパッドの場合は ECS や IAM の設定を試行錯誤)
- 解析結果を保存(→ 同様に S3 や RDS の設定を試行錯誤)
という一連の処理を各開発者が個別に行うのは非効率です。同じ解析器を使い、同じ解析対象(基本的には解析時の全レシピ)を集め、定期的に解析を行い、解析結果を簡単に使い回せるようにしたい。形態素解析が必要なプロジェクトが増えるにつれ、そういう想いが募っていました。
共通化は面倒だけど、難しい話ではない
こうした背景で、重すぎる腰を上げて、共通化を行うことにしました。こういう作業ってどうしても後回しになりがちですよね。各開発者は各プロジェクトを進めたいのであって、他のプロジェクトのことまでケアして共通化を行うのはなかなか面倒です。
一方、この話は技術的には大したものではありません。単に、「形態素解析を行うだけのバッチをつくる」というだけの話です。上の処理 1 から 4 を丁寧に行ない、各プロジェクトが使いやすい形で最終的な解析結果を残せば任務完了です。難しい話ではありません。
形態素解析を行うだけのバッチ
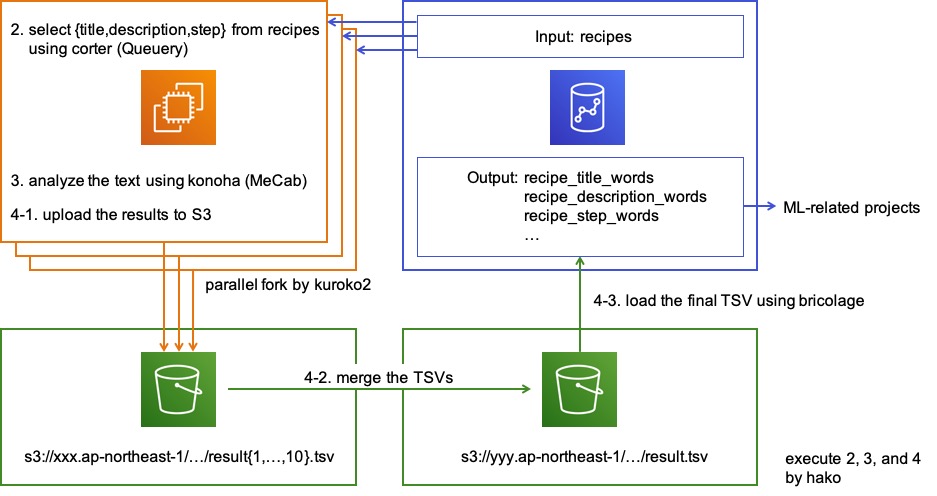
というわけで、そういったバッチをつくってみました。バッチの概観は下図のとおりです。以下では、バッチの各処理について、その詳細をお話しします。
1. 解析器をインストール
していません。同僚の @himkt がつくった konoha を使いました。konoha はさまざまな形態素解析器(e.g., MeCab、Sudachi、KyTea)のラッパーです。konoha で解析を行なう社内サーバがあったので、解析器のインストールや設定はこのサーバに委ねることにしました(なので、上図にも処理 1 は含まれていません)。なお、クックパッドで使っている解析器は MeCab です。
2. 解析対象を取得
解析対象はレシピ(のタイトルや紹介文、手順など)です。これは Redshift から取得しました。クックパッドではほとんどのデータが Redshift に集約されています。また、Queuery(きゅーり)という社内向けのシステムがあり、UNLOAD を使うことで Redshift に負荷をかけずに SELECT が実行できるようになっています。
今回は、Queuery をさらにラップした corter(かーたー)という社内向けの Python パッケージをつくりました。corter は COllect Recipe-related TExts from Redshift の略で、その名のとおり、レシピに関するテキストを Redshift から収集するためのものです。
以下は、corter でクックパッドの全レシピのタイトルを取得するコードです(レシピ ID はダミーです)。
from corter.agent import RecipeTitleAgent agent = RecipeTitleAgent() recipe_ids, titles = agent.collect() print(recipe_ids[0], titles[0]) # => 12345, 'ナスの肉味噌炒め'
corter の内部には、クックパッドの機械学習エンジニアであれば誰もが試行錯誤したであろう SQL が押し込められています。公開済みのレシピを絞り込む WHERE の条件とか毎回忘れちゃうんですよね。
ちなみに、このような Python パッケージをつくったのにはもう一つ理由があります。生文(形態素解析されていない文)を使うプロジェクトでもこのパッケージを使いたかったからです。このようなプロジェクトとしては、たとえば、SentencePiece の学習などがあります。
3. 解析器を実行
これは簡単です。2 で集めたレシピを 1 で触れた解析サーバに投げているだけです。ただし、現在、クックパッドには全部で約 350 万品のレシピがあります。いくら MeCab が高速でも、全レシピを 1 並列で解析するのは時間がかかります。
そこで、ジョブ管理システム kuroko2 の paralle_fork を使い、10 並列で解析を行うようにしています(正確には、処理 2 の段階で解析対象を 10 分割で取得しています)。これで、350 万品を解析対象としても、タイトルのような短いテキストであれば 5 分程度で、手順のような長いテキストでも 1 時間程度で解析が行えるようになりました。
4. 解析結果の保存
解析結果は Redshift に保存するようにしました。S3 や RDS などの選択肢もありましたが、2 でも触れたように、クックパッドではほとんどのデータが Redshift に集約されています。解析結果も Redshift に保存することで、他のデータと一緒に使いやすいようにしました。
解析結果を Redshift に保存するには、まず、3 の結果を S3 にアップロードします(上図 4-1)。次に、アップロードされた 10 個の解析結果をマージして、1 個の TSV をつくります(4-2)。そして、SQL バッチフレームワーク bricolage を使い、TSV の中身を Redshift に COPY します(4-3)。これで、数億行のロードでも 10 分弱で終わります。
最終的に、下表のようなテーブルに解析結果が保存されます。これはタイトルの解析結果を保存したテーブル(上図では recipe_title_words)です。一行が一単語です。主なカラムは position(単語の出現位置)と surface(表層形)、pos(品詞)、base(原形)です。analyzed_at は、その名のとおり、解析時刻です。
| recipe_id | position | surface | pos | base | analyzed_at |
|---|---|---|---|---|---|
| 12345 | 0 | ナス | 名詞 | ナス | 2021-03-08 00:00:00 |
| 12345 | 1 | の | 助詞 | の | 2021-03-08 00:00:00 |
| 12345 | 2 | 肉 | 名詞 | 肉 | 2021-03-08 00:00:00 |
| 12345 | 3 | 味噌 | 名詞 | 味噌 | 2021-03-08 00:00:00 |
| 12345 | 4 | 炒め | 動詞 | 炒める | 2021-03-08 00:00:00 |
2 から 4 を日次で実行
以上の処理 2 から 4(今回、1 はなにもしていません)を、デプロイツール hako を使い、日次で実行しています。具体的には、ECS でコンテナを起動し、そこで処理 2 から 4 を実行しています。これにより、毎日、その日の時点で公開済みのすべてのレシピの解析結果が Redshift に保存されている状態にしています。
余談として、差分更新も考えました。つまり、前日に投稿(正確には公開)されたレシピの解析結果は追加し、修正されたレシピの解析結果は修正し、削除(正確には非公開)されたレシピの解析結果は削除することもできます。しかし、すべてのレシピを解析したところで大して時間がかからず、むしろ差分更新によって複雑性が増すデメリットの方が大きかったので、差分更新はやめました。
こうやって文書にすると、各処理は大変に見えるかもしれません。しかし、実際のところは既存の便利ツール(konoha、Queuery、kuroko2、bricolage、hako)を組み合わせただけで、そんなに大変ではありません。私が頑張ったことと言えば、corter をつくったことくらいでしょうか。これも Queuery のおかげでだいぶ楽をさせてもらいました。
解析結果を各プロジェクトで使う
さて、解析結果はさまざまなプロジェクトで使えなければ意味がありません。そこで、生文だけでなく解析結果も corter で取得できるようにしました。生文を取得するときと同様、裏では Queuery を使っており、UNLOAD でラップした SELECT 文を Redshift で実行しています。
以下は、クックパッドの全レシピのタイトルの解析結果を取得するコードです。解析結果はスペース区切りで返ってきます。オプションを変えることで、品詞で絞り込んだり、ストップワードを弾くこともできます。
from corter.agent import SegmentedRecipeTitleAgent agent = SegmentedRecipeTitleAgent() recipe_ids, segmented_titles = agent.collect() print(recipe_ids[0], segmented_titles[0]) # => 12345, 'ナス の 肉 味噌 炒め'
解析結果が必要なプロジェクトは基本的に Python がベースです。上のコードのあとで schikt-learn なり gensim なり transformers なりを使えば、レシピの分類やレコメンド、各種分散表現や BERT の学習などがすぐに始められます。
こうして、当初の目的どおり、さまざまなプロジェクトで各開発者が個別に形態素解析を行うという事態が避けられるようになりました。
次は?
本エントリの最後に、次に取り組みたいことを三つほど挙げておきます。
一つ目は、今回 Redshift に保存した解析結果をまだ使えていないプロジェクトが残っているので、これらをなくすことです。基本的には、既存のコードを corter に置き換えていくだけです。一方、それだけでは済まないプロジェクトがあります。レシピ検索のインデキシングです。まさに形態素解析が重要なプロジェクトですが、レシピ検索周りはレガシーの巣窟なので、これを置き換えるには相当の時間と覚悟が必要です。
二つ目は、再学習した解析器を使うことです。クックパッドでは、昨年、500 品からなるレシピの解析済みコーパスをつくりました。このコーパスには形態素解析(と固有表現認識、構文解析)の正解データが含まれています。このコーパスで解析器を改善し、解析誤りを減らすことで、形態素解析が必要なすべてのプロジェクトを底上げしたいと考えています。解析済みコーパスと再学習については来週の言語処理学会の @himkt の発表もご覧ください。
三つ目は、Redshift ML を使うことです。Redshift ML、突然現れましたね。上でも述べたように、解析結果は Redshift に保存してあります。これらを特徴量としてモデルを学習し、Redshift 内で推論するというフローをつくれば、レシピの分類などのプロジェクトは大部分を Redshift に任せられるかも?と考えています。Redshift ML についてはまだ勉強不足なので、まずは勉強します。
さて、これらに取り組むだけでも大変ですが、クックパッドには他にも取り組みたいことがたくさんあります。「おもしろそう!」とか「やってみたい!」と思ってくださった方は、ぜひ、採用ページをご覧ください。ご応募をお待ちしております。