パートナーアライアンス部 森田です。有料会員の獲得施策や、それに関わるサービス内動線の最適化を担当しています。
記事の対象
- 仮説検証を通じて何かを改善をしたいと思っている人
- 仮説検証の際に「どれくらいのデータを集めたら良いか」分からない人
はじめに
仮説検証とは「仮説を立て、それを証明するためのデータを集め、真偽を確かめること」です。今回は仮説検証を行う際の手順と、その検証に必要なサンプルサイズの考え方を説明します。サンプルサイズの話のみ関心があるかたは、前半を飛ばし「サンプルサイズの決め方」を読んでください。
目次
仮説検証のつくりかた
1. 仮説をたてる
仮説をたてます。知りたいことを言い切る形にすれば仮説になります。
例えば「クックパッドの利用者が有料会員になるきっかけは文字ではなく美味しそうな料理の写真である」や「クックパッド利用者は自分の閲覧したレシピを後から見返したい」などです。ただし、後者は仮説検証のための仮説としては少し不十分です。その理由は次に説明します。
2. 施策/KPIを考える
仮説は根拠の程度はあれど真偽は不明です。その真偽を確かめるために何のデータを集める必要があるか考えます。ここが一番の難所です。
「ユーザは自分の閲覧したレシピを後から見返したい」という仮説の真偽はどのようにすれば分かるのでしょうか。施策としては単純に閲覧履歴の提供が思いつきます。しかしKPIの設定で詰まります。
このようなときは「知りたいことを」をもう少し具体的にします。たとえば割合を決めたり、何かと比較したりします。例えば「全ユーザの5%がレシピを後から見直したいと思っている」や「閲覧履歴を利用したユーザは利用しないユーザに比べて利用時間が20%伸びる」などです。悩んだ場合は次に述べる「仮説検証後のアクションを決める」と合わせて考えることをおすすめします。
3. 仮説検証後のアクションを決める
実際にデータを集める「前」に、データを集めた後のアクションを決めます。このステップにより先の「施策/KPI」が必要十分か判断できます。「こういう結果ならばこうする」というのが決められないようであれば、「施策/KPI」は不十分なのでやり直します。
サービスの改善のように、指標となるKPIの意味に主観が含まれる場合はとくに意識します。事後の解釈ではサンクコストによるバイアスがかかり、冷静な判断が難しくなります。たとえば「閲覧履歴の利用者は全体の5%」という結果がどのような意味を持つか、検証後に考えるようではいけません。
4. 対象を決める
施策もKPIも決まりました。次にその対象者を決めます。
最終的なサービスへの全体影響を知りたい場合は細かいことを考えず全体を分割してABテストなどでデータを集めます。
一方で、何かしらの価値の有無を確認したい場合、まずは「このユーザの行動が変わらないのであれば、価値自体が無いのだろう」と考える理想的なユーザを施策の対象とすることをおすすめします。なぜならば全体で価値の有無を検証をしてしまうと影響が希釈されて計測が難しくなることが多いためです。
先の「2. 施策/KPIを考える」と、この「4.対象を決める」では、相関関係と因果関係の問題に十分注意してください。たとえば先の「閲覧履歴を利用したユーザは利用しないユーザに比べて利用時間が20%伸びる」という仮説の検証は実はなかなか難しく、もしそのようなデータが取れたとしても「利用したユーザはもともと利用時間が長いユーザ」である可能性は非常に高いです。この問題に関しては今回の説明の範疇外のためこれ以上触れませんが、自明な答えがないためサンプルサイズを計算するよりも厄介です。
5. サンプルサイズを計算する
施策もKPIも対象も決まりました。あとは必要なサンプルサイズを計算するだけです。タイムイズマネー、時間は有限で貴重です。PDCAを回すためにも行き当たりばったりの計測ではいけません。
サンプルサイズの決め方
ここからはサンプルサイズの決め方を説明します。
私が業務で行う仮説検証はほぼ全て、ABテストとこの先で述べる仮説検定*1という考えのもとで行っています*2。そして、その際のKPIとしては「入会する/しない」や「利用する/しない」のような、単純な1,0を好みます。そのためここからは
- A「入会率10%の現ランディングページ」
- B「入会率(以下CVR)15%を期待する新ランディングページ(以下LP)」
という2つのページを「BはAよりもCVRが5%高いだろう*3」という仮説のもとABテストし、その結果を判断するのに必要なサンプルサイズnを、信頼区間の考えをもとに説明したいと思います。
検証としてABテストをするつもりがない場合でも、この先の説明を理解することで適切なサンプルサイズを決める事ができるようになると思います。
答えを先に
ここから先の説明は少し長くなります。少しでも理解しやすいよう、これから求めようとするサンプルサイズnとは何かを、さきに文章で表現します。注意すべき点として、求めるサンプルサイズnは「差があること」を確認するためのサンプルサイズであり、「Xの差があること」を確認するためのサンプルサイズではありません*4。
確率p1と確率p2にX以上の差があるならばn個のサンプルサイズで明確な差がでるだろう。もし差が出ないのであればX以上の差は無いのだろう*5。
サンプルサイズを決める二つの要素
今回のABテストに必要なサンプルサイズは「二つの平均値*6」と「必要な確度」できまります。そのためまずは「二つの平均値」と「必要な確度」がそれぞれ何を意味するかを説明します。続いて予備知識として「二項分布」の概念を説明をした後、「必要な確度」を分解して現れる「αとβ」を説明し、最後にサンプルサイズを計算します。
「二つの平均値」とは何か
今回で言えば10%と15%です。サンプルサイズの計算にはこの二つの値が必要です。理由については少し先の「β」で説明します。
「必要な確度」とは何か
確度とは下記の二つの確からしさです。
(1) AとBに差がない
(2) AとBに差がある
その上で、(1)であるにもかかわらず「差がある」とすることを「第1種の誤り」といい、その確率を「α」といいます*7。
そして(2)であるにもかかわらず「差がない」とすることを「第2種の誤り」といい、その確率を「β」といいます。言い換えるとαは偽陽性の確率であり、βは偽陰性の確率です。
つまりサンプルサイズを決める要素の一つの「確度」とはαとβの二つであり、「必要な確度」とはαとβをそれぞれどの程度まで許容するかを意味します。
「AとBに差がない」とは何か
実のところ「AとBに差がない」とは「BはAで無いとは言えない」を意味します。消極的かつ回りくどい表現ですが、これには意味があります。実際のところいくらデータを集めても「完全に差がない」と言い切れません。そのため何かの差を判断する際にはまず、「BはAと等しいだろう」という前提に立ち、データを集め、「Bのデータを見る限り、確率的にAと等しい可能性が十分にある」状態ならば、それをもって「差がない」と結論します。いいかえると「Bの結果がAであるにしては逸脱している」かどうかで差の有無を結論するわけです。そして「Bのデータを見る限り、確率的にAと等しい可能性が少ない」場合には「差がある」と結論します。何を持って「逸脱」とするかはこのあとの「α」で説明します。
このような手法を「仮説検定」と言います。ここより先に続く説明は、この「仮説検定」という考えに基づき差の有無を結論します。より詳しく知りたい方は「仮説検定 - Wikipedia」を読んでください。
二項分布
この後に続く「αとβ」の説明のために、予備知識として二項分布という概念を説明をします。
堅苦しい説明をすると、二項分布とは
確率pで成功する行為をn回施行した場合の成功数の確率分布
です。
たとえば、裏表がともに50%の確率で出るコインを100回投げた場合、表が出る数はぴったり50になるとは限りません。むしろ出るほうが稀です。では何回が何%の確率で出現するのでしょうか。それを表したものが下の図であり、二項分布です。
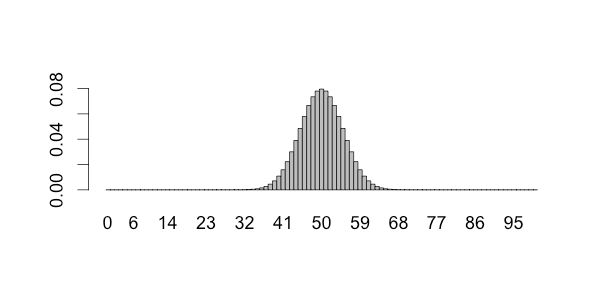
縦軸が確率、横軸が表の数になり、面積を合計すると1(=100%)になります。これをみると平均を50として、だいたいが40−60の範囲に収まることがわかります。
同じ考えで、「入会する/しない」 をそれぞれ1と0で表し、入会する確率をpとした場合も、二項分布で表すことができます。下の図は200人(n)がCVR10%(p)のLPに接触したさいに、最終的な入会数がどのようにばらつくかを示しています。実装の都合上曲線になっていますが、実際は上の図のように階段状に分布しています。また、スライドを移動することでnを変更できます。nと分布の関係を確認してみてください。なお、赤く塗りつぶされた部分の説明は後ほどするため、気にする必要はありません。
αとβ
予備知識の勉強を終え、ここからはαとβについて説明します。復習として、ぞれぞれの意味はこのようなものでした。
- αとは「真実として差がないにも関わらず、差があると結論する」偽陽性の確率
- βとは「真実として差があるにも関わらず、差がないと結論する」偽陰性の確率
α(偽陽性の確率)
αを入会数に当てはめて考えます。
200人がCVR10%の現LPに接触した場合の入会数は20人を中心にばらつきます。そして面積の(だいたい)95%が12人から28人の間におさまることが二項分布により示されています。この12−28の領域を「95%信頼区間」と呼びます。これは二つ目の図の赤で塗りつぶされていない部分に相当します。それはつまり赤い部分の面積は5%ということになります。
Bの入会数を計測し、その結果がこの赤い部分に該当する場合は「差がある」と結論すると決めたならば、それは「αを5%に設定した」事を意味します。
もしもBの真実のCVRが期待してたような15%でなくAと同様の10%である場合、Bの計測後の入会数は5%の確率で赤い部分になるため、その時は「真実として差がないにも関わらず、差があると結論する」ことになり、偽陽性の確率=α=5%となります。
なお、決めたと表現したように、αを何%するかは恣意的です。赤い面積が小さくなるようにαを設定すれば偽陽性の確率は減りますが、その分、本当に差がある場合も「差がない」と結論しやすくなります。一般的にはαを1%、5%、10%とすることが多いです。
β(偽陰性の確率)
続いてβの説明をします
αは一つの分布で完結する話でした。というのはαは比較して考える問題ではないからです。それに対してβは本当は存在する差を見逃してしまう確率であり、二つの分布が必要です。今回でいえばCVR10%(A)とCVR15%(B)の二つです。
まず先程の図に、CVR15%の分布をオレンジの線で加えます。また、入会数を入会率に置き換えた分布も合わせて示します*8。灰色の部分についてはすぐに説明するので気にしないでください。とはいえ察しの良い方のために言いますと、この灰色の部分がβです。
復習になりますがβとは「真実として差があるにもかかわらず、差がないと結論する」偽陰性の確率です。今回の例にあてはめると「Bの真実のCVRは15%にも関わらず、n人が接触した結果の入会数をみて、Aと差がないと誤って結論する」確率です。この時に、何をもって「Aと差がない」とするかは先に述べたαで決まります。つまりβはαによって変わります*9。
入会件数分布の灰色の部分は「CVR10%時に95%の確率で発生しうる人数の、CVR15%時の発生割合」を示しています。その割合(=確率)は右の山全体を100%とした時に39%となり、この39%がβです。βが39%とはつまり「Bの真実のCVRが15%の場合、200人のサンプルサイズでは39%の確率で『BはA(10%)と差がない』と結論する」事を意味します*10。
しかしながら本当に差があるにも関わらず、39%の確率で差がないとしてしまうのであれば「(2) AとBに差がある」を十分な確度で結論出来ているとは言えません。ではこのβを5%にまで減らすにはどのようにしたらいいでしょうか。もしまだ試していなければ最後の図のスライドを動かしてn(サンプルサイズ)の値を増やしてみてください。するとnの増加に伴い、入会確率分布の山が鋭角になり、結果として灰色の面積が減っていくことがわかります。これはつまりβを小さくするにはnを増やせば良いということです*11。
また、図を見るとわかるように、βは二つの分布の山の距離(平均値の差)により変化します。もしもB(オレンジの線)が15%でなく30%であれば山の距離はもっと離れ、それにともないβの値も変化します。このことから「適切なサンプルサイズ」を求めるには「二つの平均値」を事前に決める必要があることがわかります。
ここまでの話を整理するとこのようになります。
- α = 恣意的な確率
- β = f(α, 二つの平均値, サンプルサイズ)
このことからも、適切なβにするには、サンプルサイズを変化させれば良いことがわかります。
サンプルサイズの計算
今までの話を元に、αとβがともに5%となるようなnを計算します。考え方としては、Aの右側2.5%とBの左側5%の数値が一致するようなnを求めます。そうすればBの効果が15%(以上)である場合に十分な確率で差を検知できるだけのサンプルサイズを求めることができます*12。
計算には二項分布の正規分布への近似を利用しています*13。計算のためのPythonコードは以下のようになります。
import sympy as sp
p = 0.1
diff = 0.5
n_s, p_s, diff_s = sp.symbols("n_s p_s diff_s")
a_mean = n_s * p_s
a_var = (a_mean * (1 - p_s))
a_sd = sp.sqrt(a_var)
b_p = p_ + p_s * diff
b_mean = n_s * b_p
b_var = (b_mean*(1 - b_p))
b_sd = sp.sqrt(b_var)
a_right = (a_mean + 1.96 * a_sd)
b_left = (b_mean - 1.65 * b_sd)
param = [(p_s, p), (diff_s, diff)]
print(sp.solve((sp.Eq(a_right.subs(param), b_left.subs(param))), n_s)[1])
=> 554.289654454896
これにより、555人という結果が得られました。この人数を先程の図に設定し、いい塩梅であることを確認してみてください。
まとめ
前半は仮説検証のつくりかたを、後半はその際に必要なサンプルサイズの考えかたを説明しました。「何のために何を計測するか」は最も大切な、かつ難しい問題です。しかし、もしそれを決めることが出来たならば、その時は十分なサンプルサイズを伴い正しく判断しなければいけません。また途中で述べたとおり、相関関係と因果関係にも十分注意してください。
サンプルサイズの話に関しては出来る限り誤った事を書かないように注意したつもりですが、私自身の統計や検定に対する理解不足から、説明や表現に間違いがあるかもしれません。その際は指摘していただけると助かります。
参考書籍
私が仮説検証に取り組み始めた当初、確率と統計に関して全くの無知でした。数学の知識も乏しく、参考書を読んでもなかなか理解できません。そんな時に出会った「入門統計学」と「伝えるための心理統計」の二冊は、混乱しがちな所を一から丁寧に書かれており、非常に助かりました。もし統計を一から学ぼうという方におすすめします。また、今回の説明にない「平均値の検定」などを行う際のサンプルサイズに関しては、永田靖さんの「サンプルサイズの決め方」で学ぶ事ができます。
入門 統計学 −検定から多変量解析・実験計画法まで− - 栗原 伸一
https://www.amazon.co.jp/dp/4274068552/
伝えるための心理統計: 効果量・信頼区間・検定力 - 大久保街亜, 岡田謙介
https://www.amazon.co.jp/dp/4326250720/
サンプルサイズの決め方 - 永田 靖
https://www.amazon.co.jp/dp/4254126654/
便利サイト
Optimizely社がサンプルサイズを計算するページを無償で提供しています*14。
www.optimizely.com
追記
hoxo_mさんが本記事に不足している点を記事にしてくださいました。ありがとうございます。
ご指摘のとおり、目新しいものの数値は短期的に良くなる傾向にあります。実務では落ち着くまでのデータを切り捨てたうえで判断しています。
d.hatena.ne.jp




{kind=link}