こんにちは。レシピ事業部の新井(@SpicyCoffee)です。
クックパッドではこれまで、レシピを投稿してから検索結果に反映されるまで最長で 24 時間程度の時間がかかっていました。今回、この時間を 5 分程度、最長でも 10 分程度に短縮することに成功しました。本記事では、プロジェクトオーナーの立場で関わった私が代表してその開発について紹介します。
プロジェクトの目的と数値目標
本プロジェクトでは上記の「レシピを投稿してから検索結果に反映されるまでの時間短縮」が目的とされました。しかし、時間短縮といっても現状 24 時間であるものを "1 時間" にするのか、"1 分" にするのか、"1 秒" にするのかでは話が全然違います。この数値目標は設計を始めとした後の意思決定に大きく影響を与えるため、しっかりとした意図を持った状態で明確に定めておく必要がありました。
そこで、私とプロダクトオーナー*1が議論を重ね、まずは ”今回のプロジェクトで実現したいユーザー体験" を定めました。その体験から必要となる検索結果の反映頻度を逆算し、最終的な数値目標を「中央値 5 分程度、最大でも 10 分以内の検索結果への反映」であると定めることとなりました。同時に定めたプロジェクトのスケジュールは 6 週間であり、見積もりの第一印象としてはかなりギリギリの設定でした。
この記事では、今後本プロジェクトで実現された「検索結果が反映されるまでの時間の短縮」を “short-period indexing” と呼称することにします。
旧システムの概要
プロジェクト発足時点での検索周りのシステム(以下旧システム)を以下に示します。

旧システムの肝は以下の2点です。
検索インデックスを生成する日次バッチ
旧システムでは、検索結果の更新を 24 時間に一度でいいと割り切り、日次バッチでインデックスの更新を行っていました。レシピに関する各種メタデータを集め、必要に応じて加工することでドキュメントを生成し、そのドキュメントを Solr に送信することでインデックスを生成します。生成されたインデックスは後ほど説明する ECS を利用したデプロイメントのために S3 に配置されます。
日次更新でよいという割り切りの元に、およそ 100 を超える field の情報を数百万レシピについて毎日生成しており、中には機械学習を用いてレシピにスコアを付与するような処理も含まれていたため、その実行時間は 90 分程度になっていました。
ちなみに、このバッチ自体も 5 年ほど前に旧システムから分離・リプレイスされたものになります。当時の様子は以下の記事に記載してあるため、よろしければあわせてご覧ください。
ECS を利用したデプロイメント
旧システムでは、ECS のタスクとして Solr を起動していました。一般に、検索エンジンのようなステートフルなミドルウェアと ECS は相性がよくないとされています。しかし、旧システムでは S3 にインデックスを配置してタスクの起動時にそれをダウンロードしてくることでステートをコンテナの外に出し、その相性の悪さを解消しています。
この設計は「ステート(= インデックス)の更新頻度が十分に低い」という前提に基づいているものであり、本プロジェクトの目的を達成するためにはリプレイスする必要性が出てくる可能性もある箇所でした。
この開発についての詳細は以下の記事で解説されていますので、よろしければこちらもご覧ください。
目標達成のための課題
旧システムを考察することで、目標を達成するためには以下のような課題があることがわかってきました。
short-period indexing に適した Solr の使い方を再考する
旧システムでは、常在的に起動している Solr は "参照系" のみであり、index の更新時には spot instance として "更新系" の Solr を立ち上げて index を生成していました。index の更新が日次であればこの方法でも問題ありませんが、これが数分以下のオーダーになるなら "更新系" の Solr も常に稼働し、かつ複数の "参照系" Solr に更新を同期する必要がありそうです。
更新の同期方法については、たとえば、Solr にはクラスタを組んで replication を実行するための機能があります。しかし、この機能が ECS に Solr を乗せている状態でも問題なく動作するかは自明ではありません。ECS を活用することによるデプロイやスケーリングの容易性といったメリットは可能な限り残したい*2ものの、そのためには新しい要件に合わせた調査や工夫が必要になりそうです。
そもそも S3 を介してインデックスを配布するやり方が適しているかも含め Solr 周りの構成・設計は大幅に考え直す必要がありそうでした。
インデックスする情報を選別する
前述したように、レシピのドキュメントは 100 前後の field を持っており、中には機械学習を用いて付与されたスコアのようなものも含まれます。これら全ての情報をインデックスしようとすると、そもそもその処理に時間がかかる可能性が高く、short-period indexing のタイムスパンでこれを実行することは困難だと考えられます。したがって、ユーザー体験に立ち返って short-period indexing のスコープに含める field を定義する必要がありました。
また、クックパッドのレシピはユーザー投稿物です。したがって、何のチェックもせずにレシピをインデックスしてしまうと、明らかに料理ではない写真を用いたレシピなどの、不適切な投稿の露出が増えてしまう可能性があります。このことを考えると、インデックスする情報に加えて「どのレシピをインデックスするか」という判定が必要になると予想されました*3。
日次バッチによる更新と short-period indexing による更新を同居させる
日次バッチによるインデックス更新は、更新頻度と引き換えではありましたが、緊急時にロールバックが容易になるといったメリットもありました。検索結果に不具合が生じた際、インデックスのバージョンを巻き戻すことで前日時点のインデックスを用いて検索機能を提供することが容易で、これは検索システムそのものの頑健性を支える一つの要素になっています。
この「セーブポイントをつくる」機能は有用なため可能であれば残したく、そうなると日次バッチによる更新と short-period indexing による更新が並列することになります。こうなるとインデックスの更新経路が複数になるため、その際にコンフリクトが起こらないようにシステムを設計する必要がありそうでした。
キャッシュが検索結果の更新を阻害しないようにする
前述した構成図では表現されていませんでしたが、検索システムの周辺には多種多様のキャッシュが存在しています。クライアントアプリからのリクエストを受け付ける API や、検索サーバーからのリクエストを受け付ける Solr と、複数箇所にキャッシュが存在しており、検索インデックスの更新時にはこれらを破棄しなければ検索結果が変化しません。
単純にキャッシュを剥がせば各サービスへの負荷増大は避けられず、まずは現状のヒット率等を調査して剥がせるなら少しずつ剥がす、難しそうならサーバーを増やすなどの対応が必要になりそうでした。
新システムの概要
以上に挙げた課題を解決するために、以下の図に示すような全体像のシステムを設計・開発しました。
開発の流れとしては、全体設計についてはプロジェクトメンバーの 4 名全員で議論しながら固め、必要な開発がある程度特定された後に、各位の専門領域に合わせて調査や実装を割り振る形にしました。

新システムの特徴を以下に示します。
1. User-Managed Index Replication を利用した Solr cluster の構築
新システムでは Solr が提供する User-Managed Index Replication の仕組みを利用して "更新系" と "参照系" を組み合わせた Solr cluster を構築しました。
このモードでは Solr インスタンスは update リクエストを受け付ける 1 台の leader と、検索リクエストを受け付ける複数台の follower に分かれます。follower は設定した時間ごとに leader に対してポーリングを行い、差分をダウンロードします*4。それぞれの Solr は旧システムと変わらず Hako を用いて ECS Task として起動しています。
細かな要件としては、更新がコンフリクトしないように同時に起動している leader は最大 1 task に抑える必要があり、これは ECS の minimumHealthyPercent や maximumPercent を設定することで保証しています。
また、follower は起動時に日次バッチで生成された index を S3 からダウンロードし、その後 leader が保持している更新分を replicate し終わったタイミングで自身の status を healthy としてサービスインします。こうすることで、ヘルスチェックを成功させるタイミングをコントロールし、起動後 replication 途中の follower にアクセスが集中すると、アクセス毎に検索結果が変わってしまうといった問題を防いでいます。
2. EFS を利用した index の永続化
新システムにおいては、leader Solr が再起動や deploy をした場合においても index の状態を保ち、update と replication が正しく動作する状態を保証する必要があります。
これを実現するために、AWS のネットワークストレージサービスである EFS が利用できます。EFS を ECS にアタッチすることで、永続的なストレージをマウントすることができます。しかし、EFS はネットワーク越しにアクセスするストレージであるため、レイテンシ等の性能は ECS のエフェメラルストレージに対して少し劣るものとなってしまいます。
そこで、update リクエストを受け付けて index を永続化する必要のある leader のストレージには EFS を使い、ユーザーからの検索リクエストを受け付けて素早く応答する必要がある follower のストレージには tmpfs を利用することとしています。
また、新システムにおいても、旧システムと同様に日次で計算・付与される field は存在するため、日次バッチで生成された index で EFS の中身を差し替える処理が実行されています。
このとき、index の差し替えや leader/follower の再起動順序によっては replication の整合性が取れなくなり様々な問題が発生することがわかったため、依存関係を丁寧に整理して各処理の実行順序を制御しています*5。
3. index update batch の定期実行
index の更新は 5 分ごとに定期実行するバッチで実現しています。その定期実行ごとに「直近 1 時間で更新があったレシピの情報」を取得し、その情報を元に必要な処理を施してドキュメントを生成し、leader に update のリクエストを投げるという流れです。

このとき「そのレシピが不適切な投稿である確率はどのくらいか」を ML によって判定する API へのリクエストを挟むことで、不適切投稿の露出が増えることを防いでいます*6。
定期実行バッチにするのではなく、レシピの投稿・更新にフックさせてイベントを発行・キューイングして都度処理する方針も考えましたが、
- イベントの発行数が多くなり既存の社内基盤を利用することができるかどうかが明らかでなかった
- リトライ処理の実装が複雑になる
- そこまでのリアルタイム性が求められていない
ことから採用を見送っています。
本番環境への展開
プロジェクトの完遂には、システムの構築とは別に展開に向けた各種作業も必要です。今回は SRE のメンバーの協力によって、以下に挙げるような作業を事前にキャッチアップ・進行してもらうことができ、非常にスムーズに展開を終えることができました。
キャッシュの整理
システムを構築しても、既存のキャッシュ構成は日次での検索結果更新を前提としていたため、TTL が数時間単位のものになっていました。このままでは、キャッシュの更新間隔が検索結果の更新間隔よりも長くなってしまいます。
検索結果の更新頻度に合わせてキャッシュの TTL を短縮したいですが、調査が不十分のまま進めるとキャッシュの裏側にあるサービスへの負荷が増大し、障害を引き起こしてしまう可能性があります。
そこでまずはキャッシュの設定変更が与えている影響を観測できるように、Prometheus + prometheus_exporter gem を用い、キャッシュのヒット率などを計測するようにしました*7。次にそれらの変化や各サービスの負荷を確認しながらキャッシュの TTL を徐々に短くする変更を行い、最終的に、サービス障害を起こすことなく TTL を 5 分にまで短縮できました。
負荷試験と段階ロールアウト
検索機能の変更はクックパッドのほぼ全ユーザーに影響を与える大規模なものになります。本番展開前の負荷試験は、展開後の障害発生率を抑えることができるのはもちろん、開発者が安心して展開を行えるようになります。
また、展開自体を一度に行うのではなく、徐々にユーザーリクエストを流すような段階ロールアウトの手順を踏むことで、大規模障害の発生率を抑えることができます。
今回は以下の手順で負荷試験と段階ロールアウトを行いました。
- 本番の Solr に届いているリクエストをミラーリングし、新 Solr cluster でもリクエストを問題なく捌けるかを確認する(負荷試験)

負荷試験の概要 - 実際に一部のレスポンスを新システムからのものに差し替え、徐々にその割合を大きくしていく(段階ロールアウト)
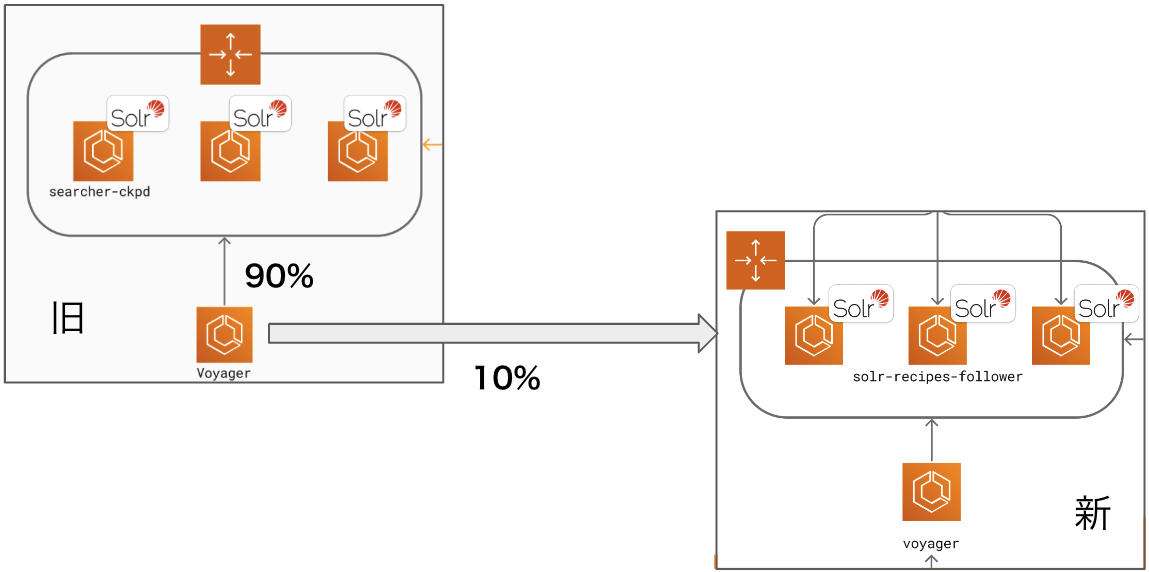
段階ロールアウトの概要 - 全てのレスポンスが新システムからのものになった後、short-period indexing を有効にする
このうち、1 の負荷試験は Envoy のRequestMirrorPolicyを、 2 の段階ロールアウトは Envoy のWeightedClusterを使って実現しています。
まとめと振り返り
本プロジェクトでは、従来の検索システムではレシピ投稿から結果への表示までに最長 24 時間かかっていたものを、5 分程度にまで短縮することに成功しました。課題の特定から解決までを 6 週間でおこなうというタイトなスケジュールではありましたが、事業要件に過不足のない開発を事故なく完遂することができたのではないかと思います。
振り返ってみると成功の要因としては
- プロジェクト冒頭にプロダクトの実現すべき体験からブレークダウンする形で要件をしっかりと定義した
- 後の意思決定に軸が通り、手戻りも少なくなった
- プロダクトからインフラサイドまで、各領域について高い専門性を持つメンバーが集まった
- 全体の要件定義やざっくりとした設計は全員で行い、そこから先の詳細開発は各メンバーが担当した
- プロジェクトのため臨時に結成されたチームだったが、期間中は週2回の check-in MTG を設定してスムーズに同期と相談をおこなえるようにした
- スポットで機械学習エンジニアなど、他チームの助力も得ることができた
ことが大きかったのではないかと思います。
組織として達成したいミッションがあり、そのための事業・プロダクトがあり、それが実現したい体験を阻んでいる障壁があるところに技術をぶつけてそれを取り除くという仕事は、やはりとてもやりがいのあるものだと改めて実感しました。それぞれに高い専門性を持つメンバーから成るチームで仕事ができたことも含めて、個人的には入社以来もっともおもしろい仕事の一つであったように思います。
Acknowledgements
本プロジェクトは 4 名のメインメンバー+周辺部署のメンバーが関わり、それぞれ力を発揮したことで完遂することのできたプロジェクトです。私一人の力では到底実現できなかったであろう課題解決を共に推進してくれたことに改めて感謝します。
最後に、メインメンバーの 4 名について、各作業をどのように担当したかを明記します。
- @SpicyCoffee(筆者)
- 検索エンジニア
- 担当:プロジェクト全体の統括・最終意思決定 / indexing application の実装
- @osyoyu
- 検索エンジニア
- 担当:Solr Cluster と Persistent Storage 周りの設計・開発
- @s4ichi
- SRE
- 担当:Solr Cluster と Persistent Storage 周りの設計・開発 / 負荷試験とロールアウト
- @eagletmt
- SRE
- 担当:キャッシュの調査と最適化 / indexing application の実装
この記事が、日々技術を用いてユーザー課題を解決しているみなさまのお役に立てば幸いです。
*1:今回は CEO がその役割を担っていました。社長と直接仕事をする機会が降ってきてラッキー。
*2:当時の ECS & 社内基盤 Hako という構成は運用負荷が低い上に非常に安定しており、Solr が直接の理由となって障害が起きたのは年に 1 度もないように記憶しています。
*3:人手によるレシピの全件チェックは short-period indexing 以前も行われていたため、「オペレーションの見直しも含め、レシピチェック周りでもシステム変更が必要になると予想された」という表現の方が正確かもしれません。
*4:leader から follower に対して変更を通知しない点は MySQL の replication との違いかもしれません。
*5:現状の実装だと検索結果が数時間前の状態に一瞬だけ巻き戻ってしまったりするのですが、実装難易度を考えてこれを仕様側で許容するといった判断もおこなっています。
*6:この API の開発は、投稿物のチェックを行っているチームと機械学習チームの協力によって迅速に開発されました。
*7:クックパッドが採用している Unicorn はマルチプロセスで動いているため、prometheus_exporter の multi process modeを用いました。