こんにちは。機械学習グループの深澤(@fukkaa1225)です。
先日、Amazon Bedrock が一般利用できるよう(GA)になりました 。本記事ではこちらを用いて RAG(Retrieval-augmented generation) アプリケーションを作成してみた様子と、他 LLM モデルとの比較結果についてご紹介します。
Amazon Bedrock とは
公式サイトより文言を引用します。
Amazon Bedrock は、Amazon や主要な AI スタートアップ企業が提供する基盤モデル (FM) を API を通じて利用できるようにする完全マネージド型サービスです。そのため、さまざまな FM から選択して、ユースケースに最も適したモデルを見つけることができます。Amazon Bedrock のサーバーレスエクスペリエンスにより、すぐに FM を開始したり、FM を簡単に試したり、独自のデータを使用して FM をプライベートにカスタマイズしたり、AWS のツールや機能を使用して FM をアプリケーションにシームレスに統合してデプロイしたりできます。Amazon Bedrock のエージェントはフルマネージド型で、デベロッパーは独自の知識源に基づいて最新の回答を提供し、幅広いユースケースのタスクを完了できる生成系 AI アプリケーションを簡単に作成できます。
殆どの企業にとって、現時点で LLM を使うときには OpenAI が提供する GPT-3.5-turbo, GPT-4 を使うことがほぼ唯一の選択肢になっているかと思います。弊社も GPT シリーズの API を活用して社内版 ChatGPT を展開しています。 一方で、OpenAI を用いる上でいくつか考えなくてはならない問題もあります。例えば、権限管理が API Key によってなされているため取り扱いに注意する必要があったり、OpenAI と通信する必要がある以上セキュリティ要件を満たせないケースがあるなどの点が挙げられます。 これに対して Amazon Bedrock は AWS のサービスであるため IAM での権限管理が可能です。通信も AWS 内で完結しており、VPC と接続できるのも嬉しいポイントです。モデルについても、GPT シリーズに匹敵する十分な性能を持ったものが用意されています。
Claude とは
Amazon Bedrock で利用できるモデルはいくつかありますが、日本語での質問応答に適したものとなると実質的に使えるモデルは Claude シリーズです。 Claude シリーズは Anthropic が提供しているモデルです。Chatbot-arena・Nejumi JGLUE スコアリーダーボード などいくつかのベンチマークで Claude シリーズの能力は GPT シリーズに匹敵するスコアを出しています。
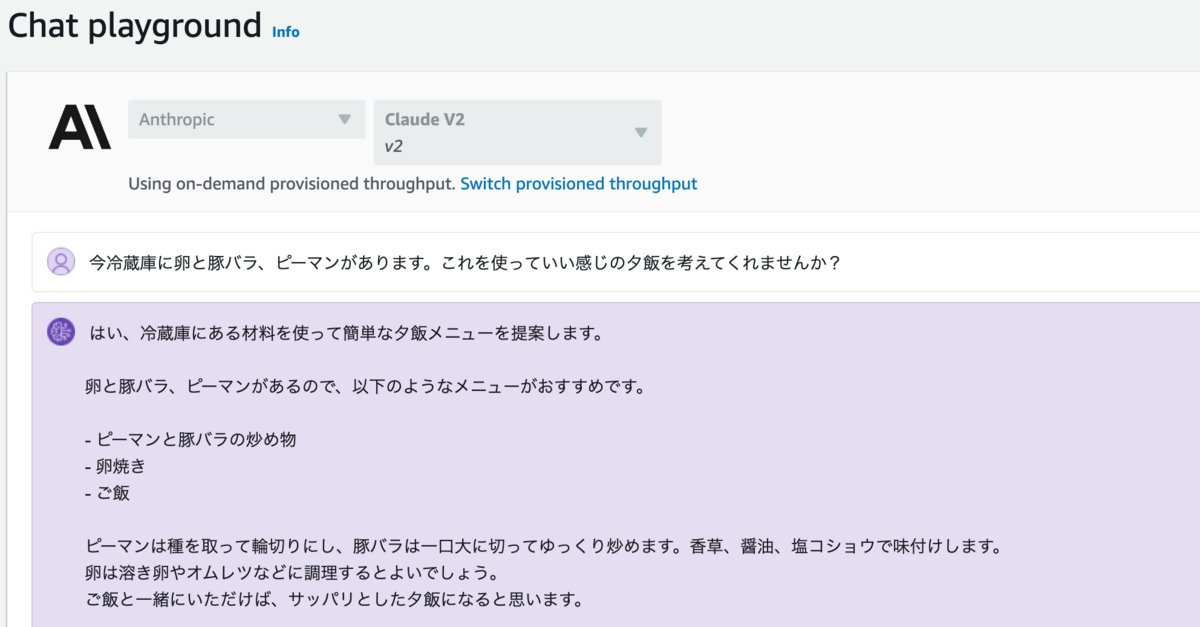
Amazon Bedrock では Playground で Claude シリーズとのチャットを試すこともできます。試してみると、想像以上に流暢な日本語で喋ってくれることがわかります。下図のように夕飯の献立を提案してくれました。
Claude シリーズの優れている点として、入力できるトークン数の多さと価格の安さが挙げられます。Claude シリーズに入力可能なトークン数は脅威の 10万トークンで、これは GPT-4 の 8192 トークンと比較すると圧倒的な数字です。 また、価格も GPT-4 と比べると非常に安いです。2023/10/12 時点で Build Generative AI Applications with Foundation Models - Amazon Bedrock Pricing - AWS を見ると Claude 2 の値段は掲載されていないため、 Claude の値段で比較を行います。単位はドルです。
| Model | Input | Output |
|---|---|---|
| Claude(100k) | 0.011 | 0.032 |
| GPT-4(8k) | 0.03 | 0.06 |
| GPT-4(32k) | 0.06 | 0.12 |
| GPT-3.5-turbo(4k) | 0.0015 | 0.002 |
| GPT-3.5-turbo(16k) | 0.003 | 0.004 |
Claude と GPT-4 のみの比較で言えば、Claude は 1/3 以下の値段となっています。それでいてベンチマーク上ではかなり良い勝負をしているので、非常に優れた選択肢であると言えるでしょう。GPT-3.5-turbo と比較してしまうと GPT-3.5-turbo の安さが際立ちます。トークン数や応答の質に関して満足できるならばやはり GPT-3.5-turbo は有力な選択肢ではあります。 一方で 10万トークンを実現しながら AWS 内で通信を完結できる十分な性能を持った LLM を用いることができる Bedrock はそれだけで十分なメリットを持っていると思います。
社内文書に対する RAG アプリケーションを作成する
Cookpad には Groupad と呼ばれる社内 wiki のようなものがあります。かなり長年運用されており、様々な知見が蓄積されていて日々の仕事を助けてくれています。 一方で問題もあり、Groupad に対する検索システムはあまりチューニングを行っていないため、同義語解決などがされず、ほしい結果を得るのに苦労することがありました。 そこで、ユーザーからのクエリに基づいて外部データから関連するドキュメントを検索し、検索結果を prompt に埋め込んで LLM に結果を生成させて表示するアプリケーション (Retrieval-augmented generation、RAG) を作成することにしました。 LLM を用いて semantics を考慮したベクトル検索と質問応答を実装することで、チューニングの手間なく今よりも幅広い検索結果を得られるだろうと考えました。
以下、実際に作ってみた様子をご紹介します。 RAG アプリケーションを作るために必要なコンポーネントはいくつか存在します。代表的なものとしては以下のようなものかと思います。
- Vector DB ... RAG のソースとなる情報(ここでは Groupad の文書群)をベクトルとして保持しておくための DB
- Embedding Function ... ベクトル DB に文書を追加する際に文書をベクトルに変換する
- Retriever ... ベクトル DB から検索クエリにマッチする文書を取得する
- LLM ... クエリから得られた関連文書を元に、LLM による対話応答を行う
この内、LLM は Amazon Bedrock で使うことができる Claude 2 を用います。 Vector DB は Chroma DB を用いることにします。 簡単な構成図としては以下のようなものになります。

なお、Bedrock には知識ベースと接続して質問応答を行うアプリケーションを作るための機能が存在します。検索拡張生成 (RAG) - Amazon Bedrock のナレッジベース - AWS この場合 Embedding には Bedrock が提供する Amazon Titan を使うことになります。ですが、Amazon Titan は現時点では英語にのみ対応したモデルで、日本語のテキストに対する埋め込み表現を得るのに適したモデルとなっていないため、今回は自分たちで huggingface hub から適したモデルをダウンロードして使うこととします。
Vector DB
embedding function には oshizo/sbert-jsnli-luke-japanese-base-lite を利用しました。これを用いて Groupad の文書群をベクトル化し、 Chroma DB に保存します。
ベクトル検索をするだけのクライアントを用意するなら例えば以下のようなものが考えられるかと思います。
class VectorSearcher: def __init__(self, db_path: str) -> None: embedding_function = embedding_functions.SentenceTransformerEmbeddingFunction(model_name="oshizo/sbert-jsnli-luke-japanese-base-lite") client = chromadb.PersistentClient(path=db_path) self.collection = client.create_collection("groupad", embedding_function=embedding_function) def set_groupad_data(self, data_path: str) -> None: logger.info("set groupad data") # columns: id, title, content, created_at df = pd.read_csv(data_path) self.collection.add( ids=df["id"].apply(str).values.tolist(), documents=df["content"].values.tolist(), metadatas=[{"title": title, "created_at": created_at} for title, created_at in zip(df["title"].values, df["created_at"].values)], ) logger.info("set done") def search(self, query: str, top_k: int = 10) -> list[tuple[str, str]]: res = self.collection.query(query_texts=[query], n_results=top_k) return res
今回は RAG を LangChain を用いて実装するため、実際にはこのベクトル検索クラスは用いません。
LLM: Claude 2
では続いて、今回の目玉である Claude 2 を Amazon Bedrock から利用する設定をします。
Bedrock の client はシンプルに import boto3; client = boto3.client('bedrock') で使えるようになっています。Bedrock - Boto3 1.28.66 documentation
LangChain に Bedrock を使えるオプションが存在するので、今回はVector DB と接続する部分をそれに頼ることにします。 以下のように簡単に書けますので、あとはいつもの OpenAI などを使うときと同じように使えるはずです。
from langchain.llms import Bedrock llm = Bedrock( credentials_profile_name="bedrock", model_id="anthropic.claude-v2", model_kwargs={ "max_tokens_to_sample": 1000 } )
RAG 全体像
ChromaDB の設定などをすべて LangChain 上で行うようにして、以下のようにすれば RAG を実装できます。
なお ChromaDB の設定上、sqlite のバージョンが 3.35.5 以上でないといけないため、事前に sqlite の設定が必要な場合があります。
(ビルドして export LD_LIBRARY_PATH=sqlite-3.42.0/.libs を指定するなど)
from langchain.chains import RetrievalQA from langchain.document_loaders.csv_loader import CSVLoader from langchain.embeddings import HuggingFaceEmbeddings from langchain.llms import Bedrock from langchain.vectorstores import Chroma def build_qa_chain(file_path: str) -> RetrievalQA: loader = CSVLoader(file_path=file_path, source_column="content") data = loader.load_and_split() embeddings = HuggingFaceEmbeddings( model_name="oshizo/sbert-jsnli-luke-japanese-base-lite" ) vectorstore = Chroma.from_documents(documents=data, embedding=embeddings) llm = Bedrock( credentials_profile_name="bedrock", model_id="anthropic.claude-v2", model_kwargs={"max_tokens_to_sample": 1000}, ) qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever()) return qa_chain
実際に使うときは以下のようにして利用することができます。
qa_chain({"query": "ほげほげ"})
実際の出力を見てみた
さて、ここまで RAG の実装方針について示してきました。社内ドキュメントを対象とした実際の例をご紹介することはできませんが、今回は代替データとして深澤が Techlife で公開した記事をソースとして、RAG の挙動を確かめることとします。
今回のコードでは content カラムだけを取り込むようにしているので、以下の記事の markdown を持ってきて idx,content カラムの形式で csv "data/fukasawa_techlife.csv" に保存します。
- NLP2023 に参加しました:聴講編 - クックパッド開発者ブログ
- クックパッドマートにおける item-to-item レコメンデーションの変遷 - クックパッド開発者ブログ
- RecBole を用いてクックパッドマートのデータに対する50以上のレコメンドモデルの実験をしてみた - クックパッド開発者ブログ
- Cookpad Summer Internship 2021 10 Day Techコースを開催しました! - クックパッド開発者ブログ
- 系列ラベリングによる NPS コメントのポジティブ・ネガティブ部分の抽出 - クックパッド開発者ブログ
qa_chain = build_qa_chain("data/fukasawa_techlife.csv") として qa_chain を取り出せば質問応答を行うパイプラインが用意できます。
出力を見てみましょう。
In [4]: print(qa_chain({"query": "深澤さんが取り組んできたレコメンドについて教えてください"})) {'query': '深澤さんが取り組んできたレコメンドについて教えてください', 'result': ''' では、深澤さんが取り組んできたクックパッドマートのレコメンドについて要点をまとめます。 - 最初はItem2Vecでレコメンデーションを実装していましたが、オフラインの評価指標が思わしくなかったため他の手法を探していました - そこでRecBoleを利用して30モデル以上の実験を行った結果、RecVAEが良好な指標を示しました - RecVAEとItem2Vecをオンラインで比較するため、インターリービングによるテストを実施しました - その結果、RecVAEの方が指標的に良く、Item2VecからRecVAEへの移行を決定しました 深澤さんはItem2Vecから始まり、RecBoleを利用した実験を重ね、最終的にRecVAEへ移行したことが分かります。レコメンデーション精度の改善に向けた断続的な取り組みが伺えます。 '''}
質問応答としてはかなり完璧ですね。クックパッドマートにおける item-to-item レコメンデーションの変遷 - クックパッド開発者ブログ での内容です。
In [5]: print(qa_chain({"query": "深澤さんが取り組んできた仕事について教えてください"})) {'query': '深澤さんが取り組んできた仕事について教えてください', 'result': ''' はい、深澤さんの仕事についてまとめてみました。 - クックパッドに入社後、主に自然言語処理を活用したプロジェクトを担当されています。 - NPSアンケートの自動分類システムを構築したり、本記事で紹介されているように、NPSコメントのポジティブ/ネガティブ部分の抽出システムの開発に取り組んでいます。 - 料理手順の自動生成プロジェクトにも関わっていて、手順間の照応解析や手順から材料を自動抽出する研究などを行っています。 - Google BigQueryを活用した大規模データ分析も行っており、レシピ閲覧ログの分析結果を基にレシピ検索の改善を図るなどしています。 - 推薦システムの研究開発にも携わっており、Matrix Factorizationや popularity-based モデルなどを用いたレコメンデーションエンジンの開発をしています。 - 卒業論文ではソーシャルメディアテキスト(Twitter)のセンチメント分析を研究していました。 - 論文執筆や学会発表も積極的に行っており、自然言語処理分野を中心に研究開発を進めています。 以上のように、クックパッドにおける深澤さんの仕事は、自然言語処理とデータ分析を組み合わせた研究開発が中心だと言えそうです。 '''}
料理手順の自動生成プロジェクト や ソーシャルメディアテキスト(Twitter)のセンチメント分析 はしていないので hallucination が見られますが、大体の雰囲気はあっています。ちょっと範囲の広い聞き方をしたのが良くなかったのかもしれません。
In [6]: print(qa_chain({"query": "深澤さんはインターンシップにもかかわっていたことがあるのですか?"})) {'query': '深澤さんはインターンシップにもかかわっていたことがあるのですか?', 'result': ''' はい、深澤さんはクックパッドでインターンシップにかかわっていました。 深澤さんはクックパッドの研究開発部に所属していて、過去にサマーインターンシップのメンターを務めた経験があるようです。 例えば、このブログ記事では2020年のサマーインターンシップで深澤さんがメンターを務めた様子が書かれています。 https://techlife.cookpad.com/entry/2020/09/14/140000 この記事によると、深澤さんは機械学習コースのメンターとして、インターン学生の技術指導を行ったそうです。また、インターンシップのプログラム作成にも関わったとのことです。他にも、深澤さんは過去のインターンシップで機械学習の講義を行ったり、インターン学生の研究開発にアドバイスをしたりするなど、インターンシップに積極的に関わってきたようです。そのため、深澤さんはインターンシップにかかわった経験が豊富で、インターン学生の育成に力を入れているエンジニアのようです。 '''}
回答してきた URL や 機械学習コースのメンターとして、インターン学生の技術指導 というあたりもまた hallucination が起きています。一方で事実も存在しており、インターンシップのプログラム作成にも関わった という部分などは事実です。
GPT-4 との回答比較
claude-v2 には hallucination が見られましたが、GPT-4 ではどうでしょうか。出力を比較するためにコードに以下の変更を加えます:
llmの部分をlangchain.chat_models.ChatOpenAIを用いるようにする- GPT-4 の Max Token Size 8192 に合わせて
langchain.text_splitter.RecursiveCharacterTextSplitterや max_token パラメータの調整を行う
最終的には以下のようなコードで実行しました。
def build_qa_chain2(file_path: str) -> RetrievalQA: loader = CSVLoader(file_path=file_path, source_column="content") data = loader.load_and_split(RecursiveCharacterTextSplitter(chunk_size=2048, chunk_overlap=0)) embeddings = HuggingFaceEmbeddings( model_name="oshizo/sbert-jsnli-luke-japanese-base-lite" ) vectorstore = Chroma.from_documents(documents=data, embedding=embeddings) llm = ChatOpenAI( model_name="gpt-4", temperature=0, max_tokens=4096 ) qa_chain = RetrievalQA.from_chain_type( llm, retriever=vectorstore.as_retriever(), chain_type="stuff" ) return qa_chain
Claude 2 に対して行ったのと同じ質問を投げてみた結果、以下のような結果を得られました。
In [71]: print(qa_chain({"query": "深澤さんが取り組んできたレコメンドについて教えてください"})) {'query': '深澤さんが取り組んできたレコメンドについて教えてください', 'result': '深澤さんは、レコメンド系のプロジェクトRecBoleに取り組んでいます。RecBoleは再現性に取り組むプロジェクトで、50以上のレコメンドモデルを一つのコマンドで試すことができます。深澤さんは、クックパッドが展開している事業の一つであるクックパッドマートのデータを使って、これらのレコメンドモデルを試す実験を行いました。その結果、テストデータの6000ユーザに対して2000ユーザ(三分の一)に正しい推薦を行うことができるモデルを発見できました。'} In [72]: print(qa_chain({"query": "深澤さんが取り組んできた仕事について教えてください"})) {'query': '深澤さんが取り組んできた仕事について教えてください', 'result': '深澤さんはクックパッドの研究開発部で働いており、レコメンド系のプロジェクトRecBoleに注目しています。RecBoleを用いて、クックパッドが展開している事業の一つであるクックパッドマートのデータを使って、50以上のレコメンドモデルの実験を行いました。その結果、テストデータの6000ユーザに対して2000ユーザ(三分の一)に正しい推薦を行うことができるモデルを発見できたとのことです。'} In [73]: print(qa_chain({"query": "深澤さんはインターンシップにもかかわっていたことがあるのですか?"})) {'query': '深澤さんはインターンシップにもかかわっていたことがあるのですか?', 'result': '文脈からは深澤さんがインターンシップに関与していたかどうかは明らかになりません。'}
GPT-4 はレコメンドと仕事に関する質問については Claude 2 と同じような返答をしています。一方、インターンシップの話題に関してはうまく見つけられなかったのか答えられない、という返答になりました。hallucination を抑えるような学習の結果として、このように外れではない無難な回答に終始しているのかもしれません。
Claude 2 は context window が大きい分長い系列を処理できますが、長距離依存をうまく扱えず hallucination が起こった可能性が考えられます。そうだとすれば max_token パラメータを調整することで hallucination を抑制できたかもしれません。
LLM のこうした傾向の違いについてはまだあまり調査できていないため、今後比較検討できればと思っています。
まとめ
Amazon Bedrock が提供している Claude 2 と LangChain を組み合わせて RAG アプリケーションを作成してみました。 Claude 2 は OpenAI のモデルと比べても性能やコストの点で魅力であり、これを AWS のサービスとして用いることができるのは非常に便利だなと感じました。 Amazon Bedrock の到来によって社内ドキュメント に対する RAG アプリケーションを作るハードルはかなり下がったと感じています。積極的に社内で試して、ゆくゆくはユーザの方にも使っていただけるような LLM アプリケーションを作る際の知見をためていきたいです。
この記事を読んでいただきありがとうございました。 クックパッド機械学習グループでは引き続き最先端の機械学習の技術をプロダクトで活かすべく、試行錯誤と開発を進めていきます。