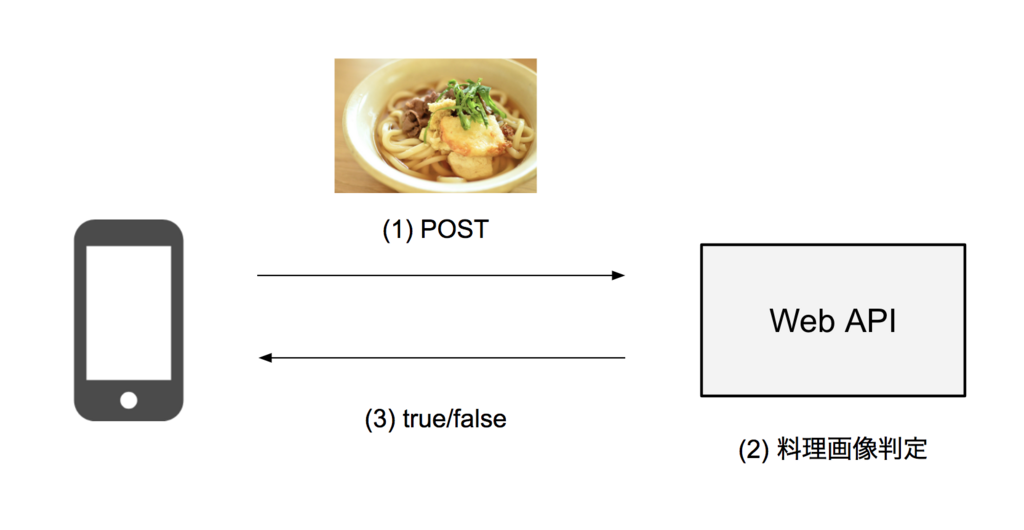
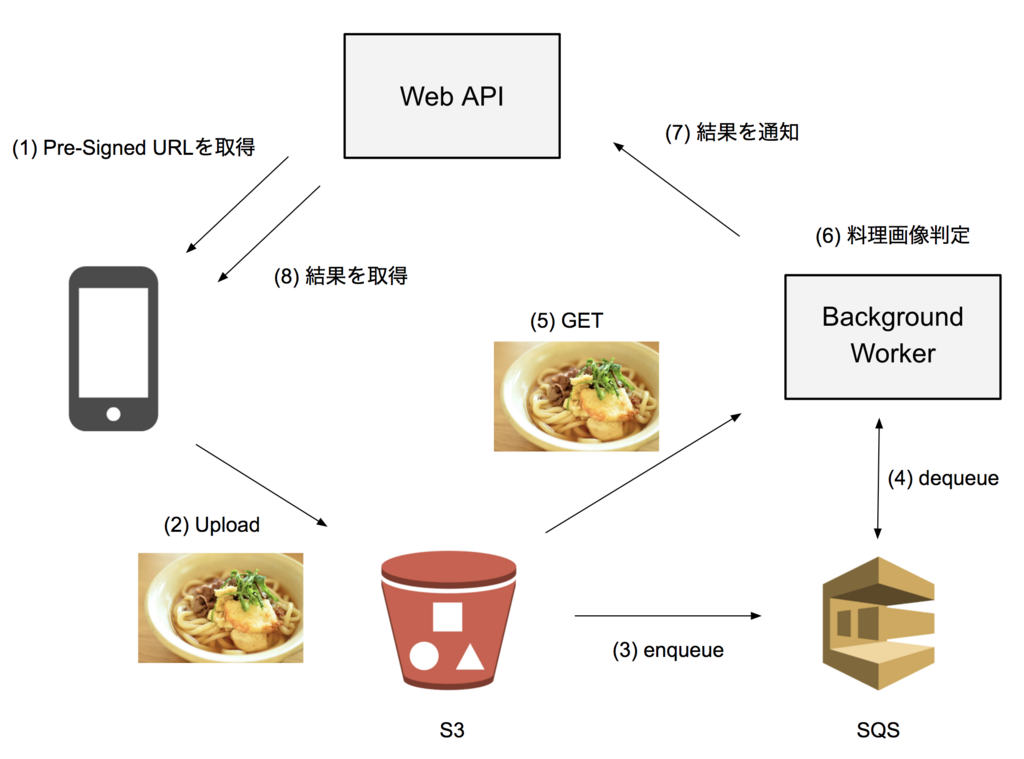
こんにちは!人事部の冨永です。
2017/09/28~29の二日間に渡って、技術系イベント「Cookpad Tech Kitchen」を開催しました。クックパッドの技術的な知見を定期的にアウトプットすることを目的とする本イベント。#11, 12の今回は株式会社はてなさん(京都)とGMOペパボ株式会社さん(福岡)のお力をお借りして、京都・福岡での出張開催を実現しました!
テーマは一夜限りのPremium Talkと題して「各社開発の裏側」を発表。本イベントで初めて公開する情報や、ここだけでしか聞けない裏話など、興味深い内容が盛り沢山なイベントとなりました。
発表資料を交えてイベントのレポートをお届けします。

9月28日【京都開催 feat.はてな】Cookpad Tech Kitchen #11

京都のはてなオフィスにお邪魔しての開催。実は登壇者同士が学生時代のインターンシップ同期で良き仲間でありライバル(!)だったこともあり、和気あいあいとしながらも白熱した登壇となりました。
 (大盛り上がりだったQAディスカッションの様子)
(大盛り上がりだったQAディスカッションの様子)
それでは登壇内容をご紹介します。
「ScalaとPerlでMicroservices in production」中澤 亮太/株式会社はてな
1人目の登壇者である中澤 亮太さん(@aereal)は、アプリケーションエンジニアとしてご活躍されています。静的解析や静的型付けがお好きで、はてなブログチームのテックリードをお務めになられています。この日は、ScalaとPerlを使ったマイクロサービス化について登壇をしてくださいました。
「イカリング2におけるシングルページアプリケーション」加藤 尋樹/株式会社はてな
2人目の登壇者である加藤 尋樹さん(@cockscomb)は、アプリケーションエンジニアとしてご活躍されています。モバイルアプリからWebサービスの開発まで積極的に取り組まれており、あの「イカリング2」の開発も担当されています。この日は、「イカリング2」の開発の裏側を教えて下さいました。
 (美味しくておしゃれなケータリングに大喜び!)
(美味しくておしゃれなケータリングに大喜び!)
はてなさんがいつもお世話になっているという京都のケータリングご飯を用意していただきました!発表を聞きながらでも楽しめるピンチョススタイルです。 イベントの後は、仕事終わりのはてなメンバーの方々と、行きつけだという居酒屋で打ち上げもしましたよ!はてなさん、ありがとうございました。
9月29日【福岡開催 feat.ペパボ】Cookpad Tech Kitchen #12

翌日は、福岡のGMOペパボオフィスにお邪魔して開催!弊社社員は福岡初上陸のメンバーが多く、みんなのテンションが高かったことをよく覚えています。笑
 (こちらでもQAセッションが大盛り上がりでした)
(こちらでもQAセッションが大盛り上がりでした)
それでは登壇内容をご紹介します。
「コンテナたちを計測すること - マネージドクラウドの今まさに開発中の裏側」近藤 うちお/GMOペパボ株式会社
3人目の登壇者である近藤 うちおさん(@udzura)は技術基盤チームに所属されています。mruby製のLinuxコンテナエンジン「Haconiwa」をリリースされたり、『パーフェクトRuby』『パーフェクトRuby on Rails』などを共著されたり広くご活躍されています。この日は、コンテナ計測について登壇してくださいました。
「ムームードメイン ショッピングカート機能を支える技術」中村 光佑/GMOペパボ株式会社
4人目の登壇者である中村 光佑さん(@litencatt)ホスティング事業部ムームードメイングループに配属。Webサービス開発においてPHPやRuby、サービス知識など福岡支社の凄腕エンジニアたちに囲まれて日々多くのことを学ばれながら、毎日を全力で楽しんでいるそうです。この日は、ムームードメインに新しく追加されたショッピングカート機能の裏側についてお話してくださいました。
 (ペパボさんのケータリングご飯もボリュームたっぷりで大満足!)
(ペパボさんのケータリングご飯もボリュームたっぷりで大満足!)
この日のご飯には、「minne」に出品されていたクラフトチーズも登場。お洒落で美味しくて感動の一言でした…。ペパボさん、ありがとうございました!
また今回、クックパッドからは2名が登壇しました。
「機械学習でサービスの常識を破壊する」杉本 風斗/クックパッド株式会社
サービス開発部エンジニアの杉本 風斗(@uiureo)。機械学習を使ったプロダクト開発に携わっています。入社当初はAndroid開発を担当するはずが、気づいたらPythonやRedshiftを使ったバックエンド開発が中心になっていたそうです。この日は機械学習を活用したクックパッドの新機能「料理きろく」について登壇しました。
「巨大アプリにおける新規開発とチームビルディング」勝間 亮/クックパッド株式会社
現在サービス開発部長を務める勝間 亮(@ryo_katsuma)は、これまで新規事業、検索、投稿、会員事業などの部門での開発およびエンジニアリーダーを担当してきました。著書に「Webサービス開発徹底攻略」「すべての人に知っておいてほしいJavaScriptの基本原則」などがあり、この日は大規模なチーム開発におけるチームビルディングの方法について登壇をしました。
 (楽しかった2日間の様子です♪)
(楽しかった2日間の様子です♪)
まとめ
いかがでしたか?とても実りが大きい出張イベントだったため、また開催したいと思っています。次はどこの会社にお邪魔させていただこうかと考え中です…!
クックパッドでは毎月テーマを変えて技術イベントを開催しておりますので、ご興味のある方はイベント Connpassページをご覧くださいね。
▼イベントページ
新しい仲間を募集中
クックパッドではレシピサービスの更なるパワーアップと、新規事業の開発に注力をしています!少しでも興味のある方は、まずお気軽にご連絡をお待ちしております!
■ Android アプリエンジニアの募集はこちら https://cookpad.wd3.myworkdayjobs.com/ja-JP/jobs/job/-/Android---_R-000145
■ iOS アプリエンジニアの募集はこちら https://cookpad.wd3.myworkdayjobs.com/ja-JP/jobs/job/-/iOS---_R-000162
■ Web アプリエンジニアの募集はこちら https://cookpad.wd3.myworkdayjobs.com/ja-JP/jobs/job/-/Web--_R-000095