クックパッドでデータにまつわるあれやこれやをずっとやってる佐藤です。分析・調査に仮説検証にデータパイプラインにと色々やってました。ちなみに先日はCyberpunk2077休暇をとるなどという呑気なことをしていたら、この記事でやりたかったことがほぼできそうなサービスがAWSから発表されて頭を抱えながら書いています。
そのログはどこまで信頼できるのか
クックパッドではサービス改善のためにWebサイトやアプリからログを収集して開発を行っています。これらのログは集計された後、ダッシュボードの形で可視化されてサービス開発者たちの意思決定を支えています。
クックパッドのログ基盤はログ送信側(クライアントサイド)もログ格納側(DWHサイド)も十分に整っており、いつでも必要であれば簡単にログを送信・集計するだけの仕組みができあがっています。

(注:例として上図を載せましたが当記事の内容はアプリに限りません)
しかし一方で、送り続けているログの管理・保守にはここ数年課題を感じています。例えば、iOSアプリのダッシュボードを見ていて、去年の6月に突然トップページのDAUだけが激増していることに気付いたとします。しかし、この原因を見付けることは非常に難しいのです。
クックパッドではWebもアプリも多くの人々が開発者として関わっています。このため、誰かがいつかどこかに加えた変化によってアプリのログへ気づかないうちに影響を及ぼしていたということが起こりえます。自分たちの担当する領域で普段は見ない数値を確認してみたら、実は半年前に大きく動いていた。だが特に何かをした記憶がない。こういったケースではどのように原因を特定すればよいでしょうか? KPIに直結しない数値・特定の条件に限定して算出した数値・実数ではなく比率に変換した数値などで、後になってから気づくことが多くありました。
より快適なサービス開発を行うためには、安心してサービスに関わる数値を確認できる状態でなければなりません。そのためにはこういったログに関する課題は解決する必要があります。そこでまず、ログの品質を保証するためにどんなことができるか考えた結果、ログデータの異常検知に取り組むこととなりました。
どうやって開発をすすめるのか
今回、異常検知をやるにあたっていくつか当初から決めていたことがありました。
- 作り込みすぎない、とりあえず使える状態を目指す
- 全体をパーツとして作ってできる限り交換可能にする
- 異常検知そのものだけではなく全体フローの最適化を重視する
これらは異常検知という仕組みが、あくまでもログの品質維持の取り組みのひとつに過ぎないことが理由となっています。もし試してみて全然だめそうだったり、より有望そうな他の手段が思いつけばいつでもピボットしたいと考えていました。
一方で既存の研究分野で培われた時系列モデルやアルゴリズムは、いつかどこかで試してみるタイミングがやってくるとも考えていました。そうなった時、いつでも任意のポイントに対する差し替えが可能となるよう、機能分割のタイミングを逃さないよう開発を進めることとしました。
こういった事情があり、最初から「scikit-leanで回帰モデルを試す」「Prophetを利用する」といった手法ありきの取り組みや「異常を検知したらそれで終わり」といった姿勢を取らないように注意していました。全体的な検知フローを重視していかにしてログの品質保証に繋がるかを考えての方針です。
この方針のもと、異常検知の仕組みは次の3つのステップの順で開発を行っています。
Step.1 MVPを作って自分で試す
まず本当に異常検知すると嬉しいのかどうかを半信半疑になって確認する必要があります。ログの異常検知をすると決まった時点で、DWHに蓄積された各種ログの集計内容を監視して上振れ・下振れなどの変化を監視することは決定していました。ただし、この時点では変化点検知(change point detect)か外れ値検知(outlier detect)かはまだ決まっていません。
最も手軽に異常検知をしようと思った時、DWHからデータを引っ張ってきて、既存の異常検知ライブラリを使って判定するのは時間がかかりすぎるように感じました。
そこでまずMVPとして、SQLのみで異常検知することにしました。最も基本的な時系列モデルはちょっとしたSQLで書くことができるため、ここをベースラインとしてまず仕組み全体を作り上げてしまうことを考えます。
ベースラインとして採用したのは過去n日間の平均・標準偏差を利用した予測です。

これは集計済みテーブルさえ用意されていればwindow関数で手軽に書くことができます。もし予測範囲に収まらなかった場合、(少々行儀が悪いですが)ゼロ割を使って無理やりSQLをエラーにします。
select data_date , uu -- uu range: μ ± 3 * σ , case when uu between week_avg - 3 * week_stdev and week_avg + 3 * week_stdev then 1 -- pass else uu/0 -- assert(ゼロ割) end alert from ( select data_date -- 対象テーブルにある日付カラム , uu -- 異常検知を行いたい対象となる数値のカラム(ここでは仮にuu) -- ↓平均と標準偏差の計算に当日は含まないため微妙にずれる , avg(uu) over (partition by uu order by data_date rows between 8 preceding and 1 preceding) as avg , stddev_pop(uu) over (partition by uu order by data_date rows between 8 preceding and 1 preceding) as stddev from $alert_target_table -- 異常検知をしかける対象のテーブル where data_date >= current_date - interval '8 days' ) where data_date = current_date
このSQLをバッチジョブとして毎朝実行させ1、ジョブがゼロ割エラーでコケたらSlackに通知を流すようにしました。

MVPだけあって当初は大量に誤報が鳴り、ほぼ毎回アラートがあがるのでこのままでは使い物にならないことがわかりました。ですが、このときアラートの精度に関しては一切考えず一旦ワークフローを固めることを考えました。仮にこの誤報が減り、今鳴っているアラートが正しい異常検知の結果であったとした場合、自分は次に何をしたくなるだろうかと考えます。
実際、自分がアラートを見た時には「これは誤報か?確報か?」と毎回調べていましたので次に何をするかは「アラートが何故なったのかを調べる」ということがわかっていました。異常検知アラートの作成者以外も「なぜ異常検知のアラートが鳴ったのか?」を容易に知ることができる状態にしておく必要があります。そこで異常検知している様子がわかりやすくなるように下記のようなグラフを作成し、自動更新がされるように準備しました。

同時にこのグラフを作ったことで何故こんなにも誤報が大量発生したのかも発覚しました。過去に収集していたが今はもう使わなくなったログ・送信条件が厳しく流量の少ないログなどが多く含まれていたため、異常検知に用いるには欠損点が多く不安定な時系列データとなっていたためでした。そこで品質を保証する意義のあるログは「多くのユーザーに」「ある一定期間は使われている」ログと見なして流量と取得日数をフィルターすることにしました。
Step1の始めに「外れ値検知か変化点検値か決めていない」と書きましたが、この時点で外れ値検知ではなく変化点検知を行うことに決定しました。この異常検知システムによって検知したいのは後から対処しようのないサービスの瞬間的な異常ではなく、ログに関する実装の修正を必要とするような開発時点でのエラー・修正ミス・抜け漏れなどを捉えたかったためです。
| \ | グラフ |
|---|---|
| 前 | 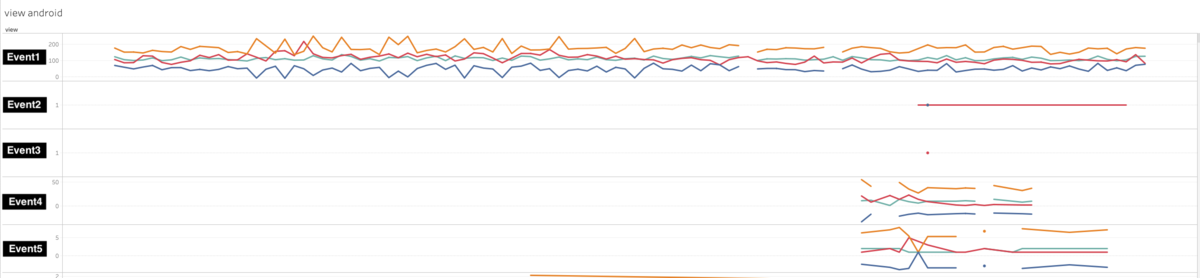 |
| 後 | 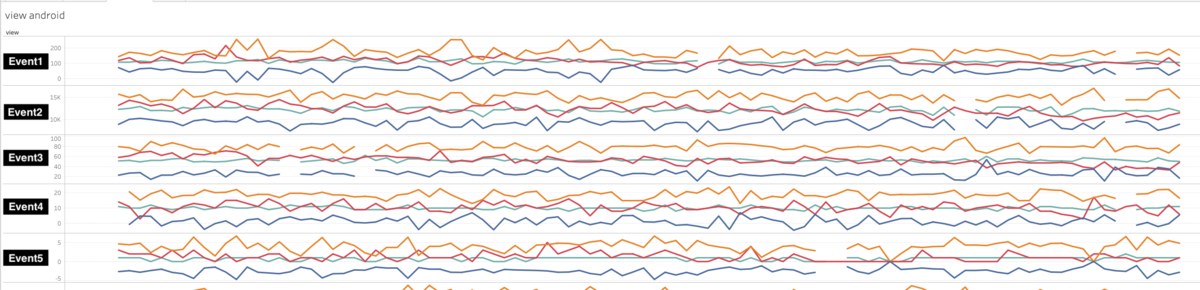 |
こういった工夫により、平均と標準偏差という最も素朴な基準でも誤報を減らすことができるようになりました。ハイパーパラメータはモデルではなくモデルに投入するデータのほうにもあったようです。ここでフィルターに用いる各種パラメータをSQLから分離させて対象とするテーブルごとに変更できるようにしておきます。
Step.2 他の人にも使ってもらえるように触りやすい仕組みを整える
Step1の状態では異常検知の仕組みを作った自分しか扱い方がわからず、アラートがきても何をどうしたら良いかわからない状態でした。この仕組みをサービスの開発にも活かすためには、多くの人に使ってもらえるようアラートが鳴ったらどうするかわかりやすいインターフェイスにする必要があります。
そこで、より異常検知した状況をつかみやすく、その後のリアクションをとりやすくするために通知内容を改善することにしました。
通知内容を改善するにあたって、これまでのただエラーを流していただけの状態を改修する必要がありました。そこでまず、バッチジョブの中身を修正し2つの処理に分割することにします。この分割で片方の処理の持つ責務を「異常を検知すること」、もう片方の処理の持つ責務を「検知した内容をどうにかして伝えること」にわけます。こうすることで仮にSlack以外のツールに通知を流す場合や、通知先はSlackのまま異常検知方法を切り替えるといった作業をしやすくなります。
そして、Slackへの通知を行う処理としてSlack WorkflowのWebhookを利用することにしました。このSlack WorkflowはSlack上でステップやタスクを実施してもらうことで定形的なプロセスを自動処理しやすくする仕組みです。また、外部アプリやサービスとの連携も豊富なため、Workflow内のステップで起こしたアクションを外部に渡すことができます。
通常のWebhookでは単純に情報をSlackへ流すだけとなってしまい、検知に対するアクションをとってもらいにくいと考えてWorkflowを採用しました。

上図のようにフローを組むことでSlackへ情報を流すとともにリアクションをとってもらえるようになります。今回このWorkflowで設定した異常検知に対するリアクションとは「対応の方針を決める」「なぜその方針に決定したのか理由を書く」の2つです。異常検知が正しく働いたとして、それでも何も対応する必要のないケースもあります。なので「このアラートは無視する、古いバージョンからのログなので放って置いても困らないため」「このアラートはきちんと調査をする、重要指標が減少していてもしも本当に落ち込んでいたら緊急事態のため」と書き込んでもらうことにしました。


この通知内容によって開発者にログの異常に関するリアクションをとってもらって、「このログ異常は何故起きたのだろう?」「このアラートは無視していいものだろうか」と考えてもらおうというのが狙いです。
このSlack Workflowへの通知切り替えを再度自分でも使ってみて、アラート量的にも対応負荷的にも問題なさそうと感じたあたりでStep3に移りました。
Step.3 他の人にも使ってもらう
いよいよ自分だけではなく誰か別の人にも使ってもらう段階です。手始めに社内用ブログに上記取り組みを投稿して軽く共有し、クックパッドアプリのiOSやAndroidエンジニアが集まるチャンネルで使ってもらうこととしました。
その週にはアラートが鳴り、何度かアラートの対応をしてもらうことができました。しかしすべてがスムーズに進んだというわけもなく、いくつかの改善点がSlackでの会話から浮かび上がりました。

Slack Workflowという多くの人の目に見える形でアラートをセットしたことで、このようなやりとりをSlack上でこなすことができるようになりました。
また、リアクションをしてもらった結果は自動でGoogleSpreadsheetに溜め込まれていきます。こちらのシートに溜まった知見を元に今後のアラートの改善にもつなげていこうと考えています。

これから
冒頭にも書きましたとおり今年の re:inventでAWSからAmazon Lookout for Metricsが発表されました。こちらはまだプレビュー版ですが、今回作った異常検知フローをそのまま置き換えることができるかもしれません。幸いにして今回のフローはアルゴリズムやチューニングに注力することなく、最小の労力をもって「ログの品質を保つためにはどんな仕組みが必要となるか?」の模索した解決案の一つに留まっていました。このため最終的な唯一の課題解決手法ではなく、むしろ課題を理解するためのプロトタイプに近く、実際に運用してみることで品質維持のために求められる多くの要素を知ることができました。
- 古いバージョンのログをどうするか
- 流量の多いログと少ないログの両方同時に監視すると発生する変化量の差をどうするか
- 既存の時系列解析や異常検知の研究手法で使われているアルゴリズムやモデルをいつ・どうやって・どう判断しながら組み込んでいくか
- そもそも「異常検知」では応急措置的な対応しかできないが、品質維持のために根本的対策や事前防止策をとることはできないか
- (他多数)
これらの要素を元に今回作成したシステムとAmazon Lookout for Metricsを比較することでより良い解決策と改善フローを実行できると考えています。
ログの異常というのは本来は起きてほしくない状況ではあります。知らず知らずの内にそのログ異常が起こっていて後から困るという自体を防ぐために、変化点検知作業を自動化する仕組みを整えることができました。まだまだ実用上では粗い点もありますが、漸進的開発をしやすい開発方針をとってきたのでこれからも徐々に改善していくことで「クックパッドではこうやってログの品質を保証しています」と言い切れるデータ基盤を目指していきます。