こんにちは、投稿開発部の佐野大河(@sn_taiga)です。 先日、クックパッドのiOSアプリでレシピのエディタ画面をリニューアルしました。今日はそのUIデザインの設計についてお話します。
方針は「簡素化」
エディタ画面は、レシピを考えて記録・投稿する人にとって重要な機能の一つです。レシピには材料や作り方、料理写真、タイトル、紹介文などさまざまな項目があり、頭の中にある料理をこれらの形に落とし込んでいくのはなかなか大変な作業でもあります。なので、レシピを書く際の手間を減らし、ユーザーがストレスなくレシピを書けることを目的に「簡素化」という方針を定め、改善に取り組みました。具体的に行ったことは大きく以下の二つです。
1.入力や編集のステップを少なくする
| 以前のエディタ | 新しいエディタ |
|---|---|
 |
 |
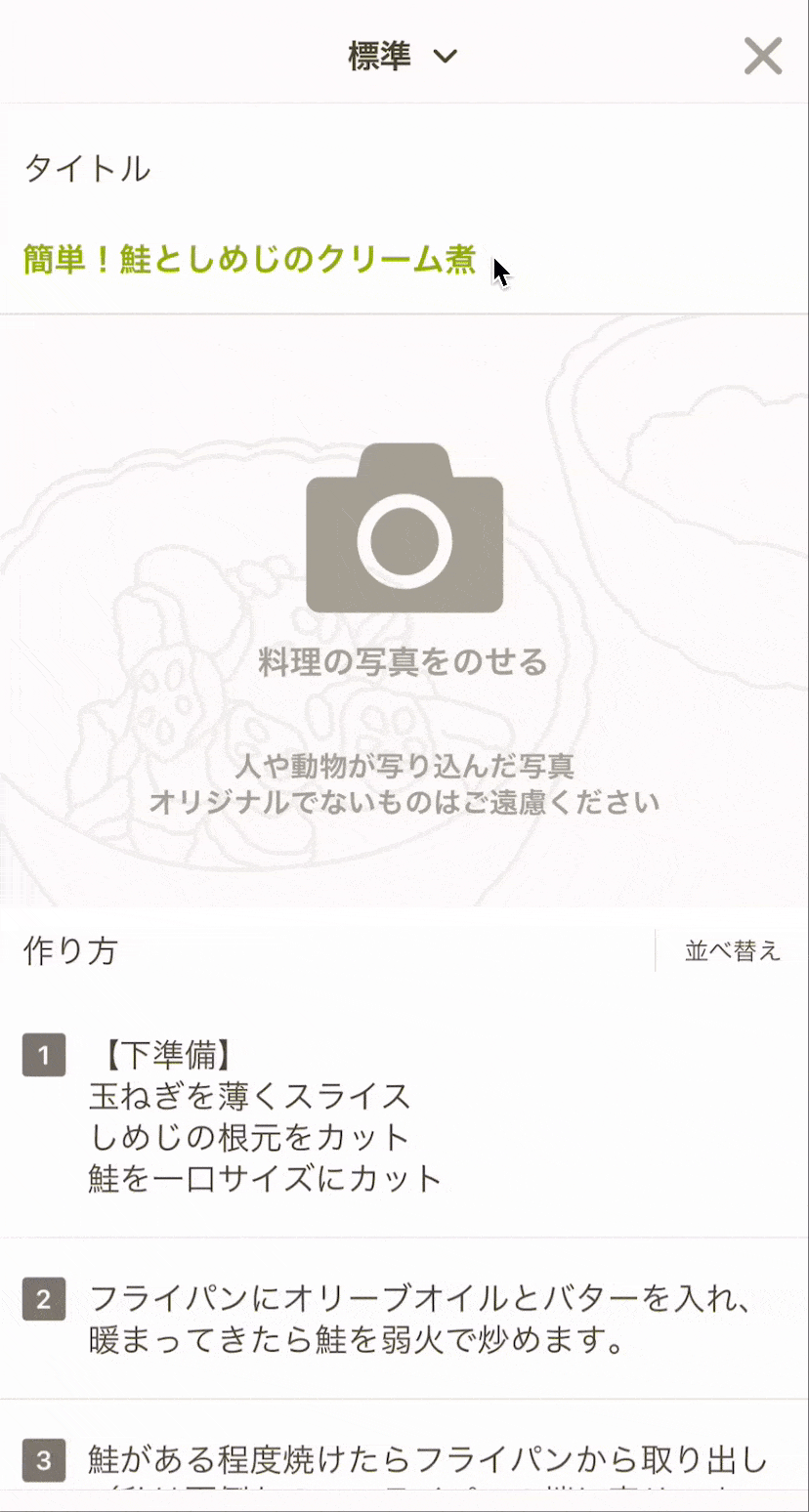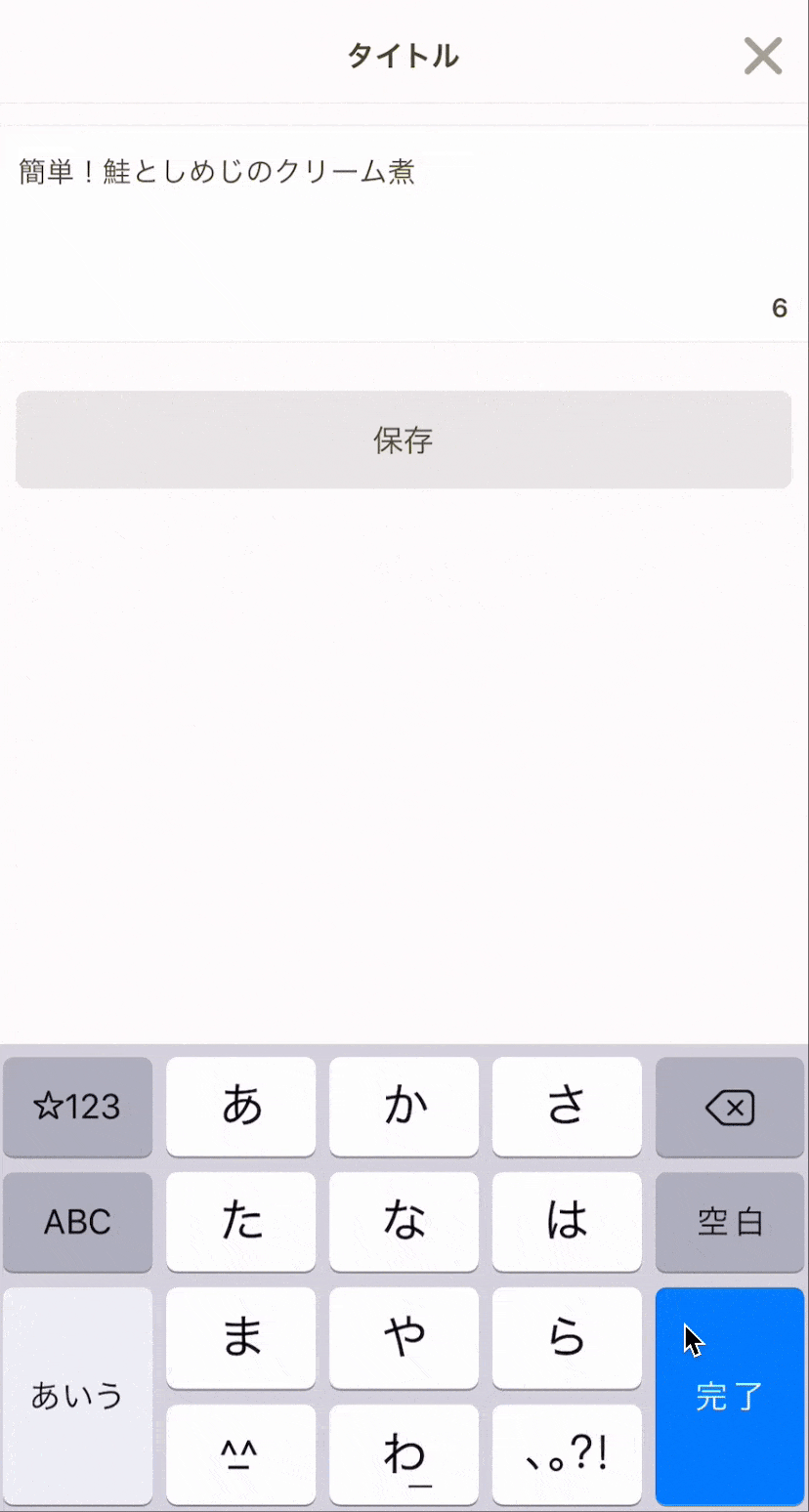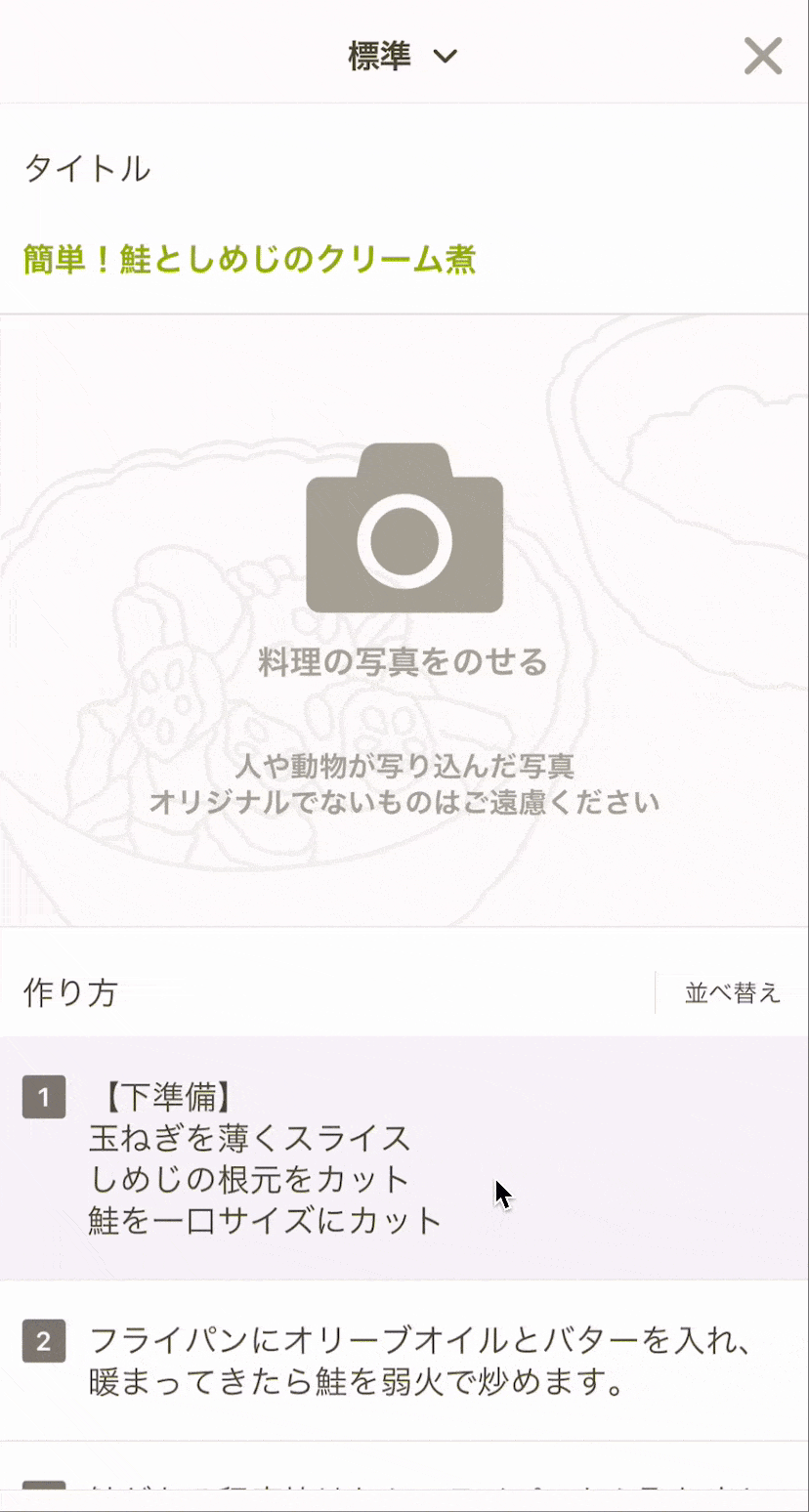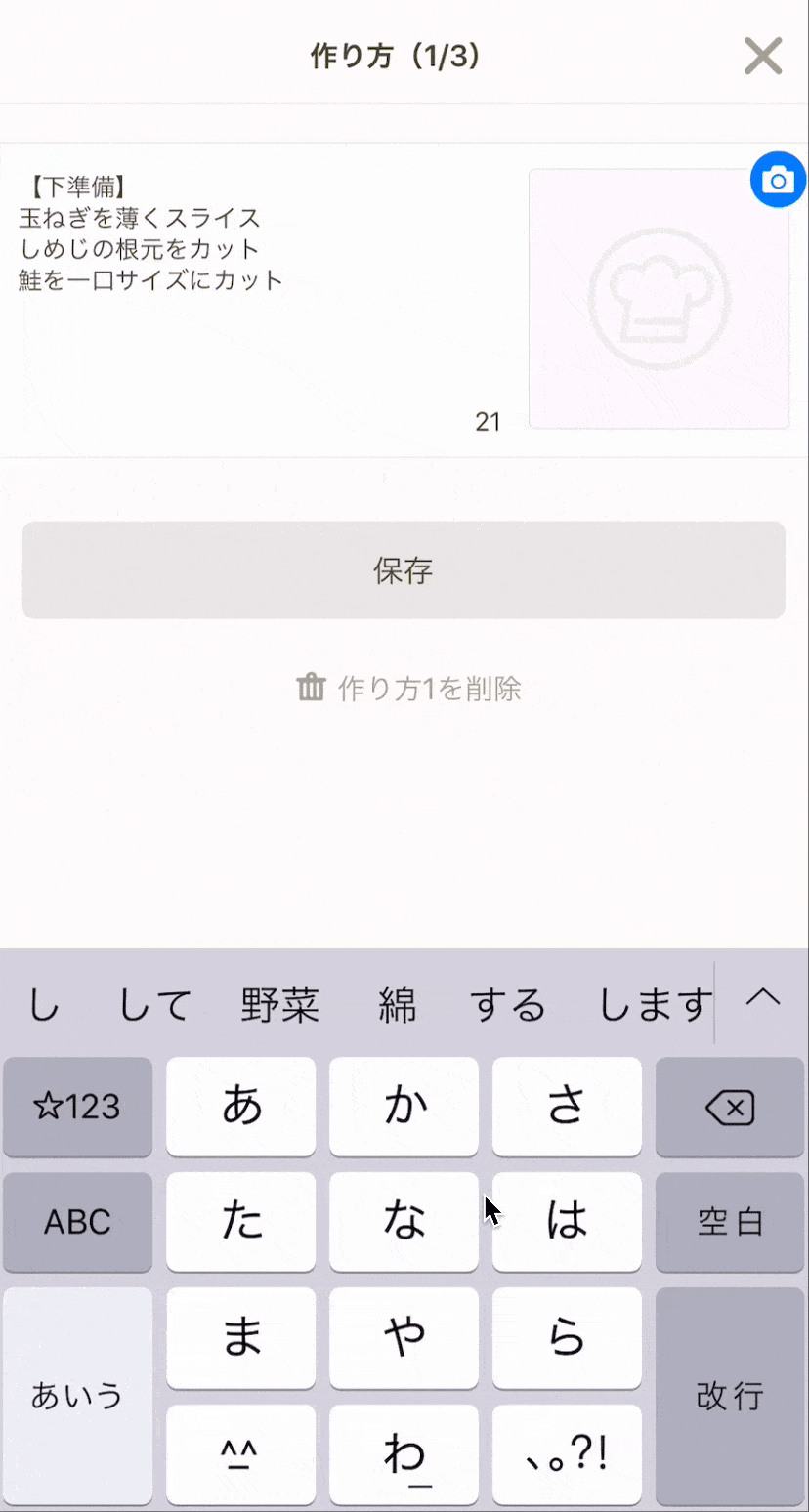
以前のレシピエディタはひとつの項目を選択するとモーダルが開き、入力を終えたら元の画面へ戻ってくるウィジェット型のUIでした。これはこれで、一つの項目に集中でき、シンプルな画面から徐々に要素を埋めていくため圧迫感が少ないというメリットがある一方、レシピを書き上げるまでのステップは多くなります。今回このウィジェット型から、一画面で入力・編集を完結できる「インライン型」のUIに変更し、各項目の入力の行き来をしやすくサクサク書き進められる構成に変更しました。
2.入力をアシストする
| (A)作り方から材料の自動入力 | (B)タイトルから材料のサジェスト | (C)分量の単位補完 |
|---|---|---|
 |
 |
 |
新しいエディタでは、レシピを書く人の入力をアシストする機能を充実させました。 料理の作り方を書いたら自動で材料欄が入力されます(A)。例えば「鮭を一口大にカットし、玉ねぎをスライスしておく」と書いたら材料欄に「鮭」と「玉ねぎ」が追加されます。 先にタイトルを入力すれば、その内容から材料を予測しサジェストもしてくれます(B)(こちらは研究開発部の機械学習の技術を用いて予測しています。予測のモデルについてはこちらの記事で紹介されていますので興味がある方はぜひ読んでみてください。) また、入力されている材料名から適切だと予測される単位を、分量の入力中にサジェストしてくれます(C) 。
このように「簡素化」という目的に対して「インライン型」「入力アシスト」という手段を用いた中、UIを設計する上での"デザインの方針"を定めました。どのような方針で、具体的にどういう工夫をしたのかについてここからはお話します。
入力量に圧倒されないように
ウィジェット型からインライン型にすることによって入力や編集の行き来がしやすくなる一方、画面内の情報量が増えます。元のUIをそのままインライン型に変更すると、画像のような文字量の多い入力フォームになり、ユーザーが画面を開いたときに「うっ、大変そう...」とレシピを書くハードルを高く感じてしまう危険性があるためこの方針を定めました。

具体的に行ったことをいくつか紹介します。
入力エリア、見出し、プレイスホルダーの同居

各項目の要素は入力エリア、見出し、プレイスホルダーの3つです。自分が今何を入力しているのかわかるように見出しは入力中も表示しておく必要があり、プレイスホルダーは「こういうものを書けばいいんだ」と理解するための手助けになります。ただ、これら3つを常に同時に表示しておく必要はないと考え、初めは入力エリアに重ねる形で見出しのみ表示し、フォーカス時に見出しを上側に移動させプレイスホルダーを表示するようにしました。これにより画面全体の文字量や高さを抑え圧迫感を減らすだけでなく、フォーカス前と後の状態をアニメーションでシームレスに繋ぐことで視覚的な負荷も軽減させました。
スケーラブルな入力エリア

レシピの紹介文やコツポイントといった長めの文章を書く箇所は、入力したテキストの行数に合わせて高さが変わるようにしました。高さを固定させる場合は、決めである程度の領域を確保しなければならず、テキストをあまり書かない人にとっては余分なスペースに、たくさん書く人にとっては狭いスペースになるのに対し、入力量に合わせて変化させることで必要十分な領域にすることができました。
入力中の項目に集中できるように
どこにもフォーカスしてないときは、入力されたテキスト以外は全体的に薄いグレーの配色で、最低限項目を認識できる存在感にし(入力可能な項目だとわかるように見出しの横に鉛筆アイコンを置いています)フォーカスした箇所のみをオレンジ色で強調し対象に集中しやすくしました。

元のUIをそのままインライン型にしたものと比べて画面全体の圧迫感が軽減しました。
自分の手で書き上げているように
入力のアシスト機能は便利になり得るものですが、タイミングや見せ方次第でユーザーの作業の妨げにもなりかねません。レシピを書く一連の流れに溶け込み余計な混乱を招かず、あくまでユーザー自身がアシスト機能を使いこなしながら「自分の手で書き上げた実感」を得られるようにとこの方針を定めました。
自動入力されたものをハイライト

作り方から自動入力された材料には背景色が付き、材料にフォーカスするか分量を入れるかすることで色が消えます。作り方はユーザー自身が書くものでもあり予測の精度はある程度高いためサジェストではなく自動入力という形で表示しているのですが、このような見せ方にすることで「自動で入力されたものだけど最終的にそれを採用するのは自分」だと思えます。
タイトルから材料のサジェストのタイミング
材料予測の通信が行われるのはタイトルを入力したときですが、このタイミングではサジェストせず、ユーザーが材料を入力する際に視界に入る位置に置いています。
| タイトル入力直後にサジェスト(不採用) | 材料欄の上でサジェスト(採用) |
|---|---|
 |
 |
タイトル入力直後のサジェストは、自分のアクションに対するフィードバックが明確で驚きが生まれやすい一方、サジェストされた材料を追加したらそのまま足りない材料の入力へ移りたくなります。これはユーザーのエディタの使い方を制限することになっていて、レシピをタイトルから書き始める人もいれば作り方から書き始める人、材料から書き始める人、全部を一気に書いて最後に微調整する人など様々な人がいます。どのような書き方の人でもエディタの使い方を制限されることのないように、材料欄の上でサジェストするUIを採用しました。材料より先に作り方を書く人も上述の補完の恩恵を受けやすくなります。

また「使っている材料はこちらですか?」という投げかけのテキストと顔アイコンを置き、クックパッド側が提案してる風にすることで、ユーザーがサジェストの棄却をしやすいようにしました。合っている材料を追加したあとは右上の×ボタンからサジェスト自体を閉じることができます。
投稿にかかった時間11%減
今回、エディタの「簡素化」という目的に対し「レシピを書き上げるまでにかかった時間」を指標の一つとして置きました。ここまでの改善を行いリリースした結果、リニューアル前のエディタと比べて平均11%の減少率が見られました。画面全体の構成の変更やアシスト機能の追加によって、リニューアル前のエディタに比べて手間が少なくサクサクレシピを書き上げることができるようになったと言えます。
まとめ
具体的なUIを設計していく際に、目的を最大限達成するために何が重要なのか、ユーザーにどう感じてもらうのが良いのかを「デザインの方針」として言語化しておくことで、狙いから逸れることなくUIを設計できました。個人的にUIを作っている最中はついあれもこれもと横道に逸れがちなのですが、あらかじめ方針を定めておくことで、なぜやってるのか、何を狙っているのかでブレることなくUIの案出しや判断がしやすくなります。
最後に、クックパッドでは「より良い体験をユーザーに届けていきたい!」というメンバーを募集中です。興味を持っていただけた方は採用ページをご覧ください。



