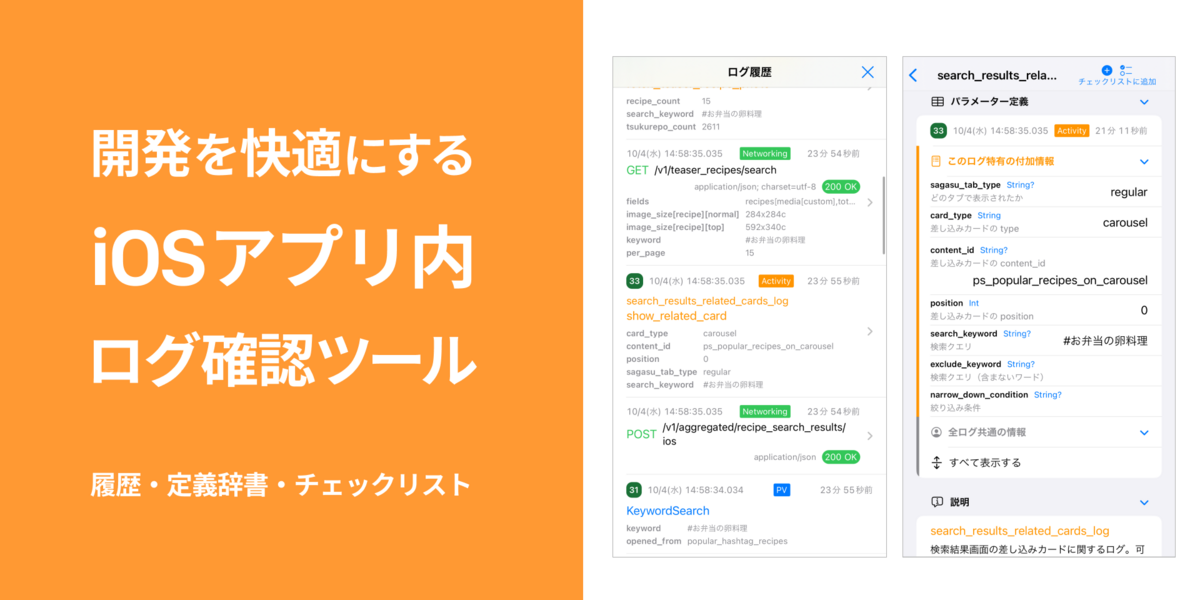
こんにちは!レシピ事業部の藤坂(@yujif_) です。
クックパッドiOSアプリの開発者用機能として「ログ確認ツール」を作ってみました。社内で1年以上運用して好評なので、その経緯や学びをまとめてみます。
iOSDC Japan 2022 では「モバイルアプリの行動ログの『仕込み』を快適にする」と題して関連した内容を発表しています。こちらの資料も合わせてご覧ください。
アプリ内ログ確認ツールとは
クックパッドiOSアプリに内蔵された、ログ関連の開発者用ツール*1です。 「ログ履歴」「ログ定義辞書」「ログ送信チェックリスト」の3つの機能があります。
1. ログ履歴


ユーザーの行動ログ(例:ボタンのタップ、特定の要素の表示など)やAPIサーバーとの通信ログを、クックパッドiOSアプリの中ですぐに確認できます。

このツールはデバイスのシェイク(Simulatorでは ⌃ ⌘ Z control + command + Z)でも表示でき、どの画面からでも気軽に使えます。
ログの内容確認が楽になる
必要な情報だけに絞り、種類別に色分けすることで、パッと見て把握しやすくしています。
これまでもロガーからの出力は Xcode 内のコンソール*3や Console.app などで確認できました。

しかし、関係のない情報もたくさん流れてくるし、見た目もJSONそのままだったり、差分も分かりづらかったりと、人間にとっては疲れるものでした。
行動ログの構成要素
- そのログ特有の付加情報
- 例:対象リソースID、検索キーワード など
- 全ログ共通で付加されている情報
- 例:ユーザーID、端末OSバージョン、アプリバージョン など
1行のログには様々な情報が含まれますが、全てのプロパティを常に見たいわけではありません。固有の情報だけに絞って、内容の確認に集中しやすくしました。
2. ログ定義辞書

送信されたログだけでなく、いま定義されている全てのログについても辞書のように調べられます。
知らないログの意味が分かる
ログ定義ドキュメントの活用
クックパッドでは、Markdown形式のログ定義をもとに型安全なログ実装用コードを生成する仕組みを3年以上運用しています。
この仕組みのおかげで、ログ定義一つ一つに必ず説明文が用意されています。何のために導入されたログなのか、パラメータにはどのような値が入るのか、注意点は何か、当時のログ設計者が記したドキュメントから把握できます。
担当領域外にも目を向けやすく
そんな便利なログ定義Markdownですが、沢山の .md ファイルがただ置いてあるだけでは活用されません。
自分の担当領域のログは詳しくても、他の誰かが入れたログは何かきっかけがないとなかなか見ないものです。
アプリ内で見やすくなることで、触っているうちに自然と「こんなのあったんだ!こういうときに使えそう💡」といった境界を越えた発見が生まれるのを狙った部分もあります。
ログを業務に活かしやすくなる

ログを見にきた人は何かを調査・分析したい人のはずなので、それを手助けするリンクを用意しています。
集計・分析へのショートカット
例えばバナーの表示やタップのログであれば、集計SQLを書いて施策の効果検証をしそうです。
クックパッドでは、データ分析SQLを共有できる社内Webサービス「Bdash Server」がよく使われています。そこで、各ログ定義に関するSQL例をBdash Serverですぐに検索できるボタンをつけました(上図)。
「この結果が気になるけど、SQLを書くのがちょっと……」という人も、もしすでに誰かが作った結果で事足りるなら即解決できますし、少し違うとしても参考にできるSQLがあるだけで書きやすくなります。
溜まっている知見をなめらかに使えるようにして、全社での生産性向上を狙っています。
3. ログ送信チェックリスト

各ログ定義をチェックリストに登録しておけば、ログ送信時に自動でチェックされ、そのログが送信済み*4かどうかを一瞬で確認できます。
ログが送られていない!?
新機能をリリースしていざ分析しようとしたら、必要なログの一部が送れていないことに気づき、「オァー!実装が漏れてました 💦」と焦る、そんな失敗が実際にありました。
例:「定期便」機能を新たにリリースする場合
- 見たい指標
- 定期便初回登録時のファネル
- キャンペーンごとの効果
- 定期便解除数
- 定期便ユーザーのLTV など
施策に関する意思決定者と「最終的に何を知りたいのか」の認識を揃えることで、必要なログが洗い出せます。指標によっては、サーバー側のデータで事足りるものもあれば、モバイルアプリ側での行動ログが必要不可欠な場合もあります。
- 必要なログ
- 定期便の商品詳細画面の表示
- 定期便登録ボタンのタップ(≒定期便登録確認画面の表示)
- キャンペーンバナーの表示
- キャンペーンバナーのタップ
- 定期便解除ボタンのタップ
- …… などなど
ややこしいのは、ユーザー状態次第では送らないログもあることです。例えば、定期便の初回ユーザー限定のバナーの表示ログは、一度でも定期便登録をしたユーザーからは送られないはずです。他にも、無料会員と有料会員の差、キャンペーンの流入経路ごとの差など、組み合わせ次第でどんどん複雑化していきます。
仕様が複雑になるとミスもしやすいですし、品質保証のテストも手間がかかります。必要なログを漏れなくすべて送るのは結構大変です。チェックリスト機能はこの対策のために作ってみました。
QA作業でログの実装漏れもわかる

まず分析に必要なログ定義を一通りチェックリストに入れます。次に、想定されるユーザーと同様の流れでアプリを操作します。
操作を終えたとき「すべて送信済み」となっているなら問題ありません。アプリをリリースしてOKです。もし「未送信あり」なら、ログ送信の実装漏れがどこかにあるということです。
このチェックリスト機能を使えば、品質保証(QA)の手動テストの時間で、ついでにログの実装漏れも検出できます。
実装担当者以外でも分担できる
アプリ単体で完結するので、Xcodeなどの開発環境も必要なく誰でも実施できます。複数パターンの検証も、エンジニアに限らずチームで分担して一気に進められるのはうれしい点です。
実装方法
アプリ内ログ確認ツールを実現するには、どうすればよいでしょうか?
まず、送信済みログを読み出せること。次に、それらをログ定義ドキュメントとうまく紐付けて扱えること。この2つが必要です。

送信済みログを端末内で保持するなら、ファイルへの出力、インメモリでの保持などいくつか方法が考えられます。 今回は、iOSの統合ロギングシステム(以下、OSログ)を活用することにしました。
Logging | Apple Developer Documentation
1. 送信済みログを読み出せるようにする
クックパッドiOSアプリでは、ログ収集ライブラリとして Puree-Swift を使っています。
os.Logger で書き込む
以下のようなコードで、簡単にOSログに出力できます。
import os // ログの出自がわかるように subsystem と category を指定 let logger = Logger( subsystem: Bundle.main.bundleIdentifier!, category: "ActivityLog"// 行動ログの場合の例 ) let logDataString = """ { "user_id": 1234567890, "event_category": "recipe_detail", "event_name": "tap_save_button", "recipe_id": 123456 } """ // ログを書き込む logger.notice("\(logDataString)")
例えば、以下のように OSログ出力用の Puree-Swift のOutputを定義してConfiguration に加えると、ログサーバーへ送信されるログと同じ内容が、端末内のOSログにも出力されます。
より詳細なPuree-Swift の Output 実装例はこちら
import Foundation import os import Puree final class OSLogOutput: InstantiatableOutput { let tagPattern: TagPattern private let logger: os.Logger // iOS 14+ で利用可能 required init(logStore: LogStore, tagPattern: TagPattern, options: OutputOptions?) { self.tagPattern = tagPattern logger = Logger( subsystem: Bundle.main.bundleIdentifier!, category: "ActivityLog" // 行動ログの場合の例 ) } func emit(log: LogEntry) { guard let userData = log.userData else { assertionFailure("logEntry must have userData") return } guard let payload = try? JSONSerialization.jsonObject(with: userData, options: []) as? [String: Any] else { assertionFailure("Cannot decode userData as JSONObject.") return } if let logDataString = prettyJSONString(payload) { logger.notice("\(logDataString, privacy: .public)") // デフォルトでは情報がマスクされるが、開発版ビルドのみなので、`.public` にしている } } private func prettyJSONString(_ object: Any) -> String? { guard let data = try? JSONSerialization.data(withJSONObject: object, options: [.prettyPrinted, .sortedKeys, .withoutEscapingSlashes]) else { return nil } return String(data: data, encoding: .utf8) } }
この os フレームワークの Logger ですが、以下のような特徴があります。
- 非常に効率的で、アプリの動作遅延なく使える*5
- Console.app や Xcode のコンソールでログを確認できる
- センシティブな情報はマスクできる(指定して公開もできる)
OSLogStore で読み出す
アプリ内ログ確認ツールで利用する際は、OSLogStore を使ってOSログから読み出しています。これは iOS 15以降で利用できます。
OSLogStore | Apple Developer Documentation
import OSLog protocol OSLogEntriesDataStoreProtocol: AnyObject { func fetchEntries() async throws -> [OSLogEntry] } final class OSLogEntriesDataStore: OSLogEntriesDataStoreProtocol { func fetchEntries() async throws -> [OSLogEntry] { let store = try OSLogStore(scope: .currentProcessIdentifier) let predicate = NSPredicate(format: "subsystem == %@", Bundle.main.bundleIdentifier!) return try store.getEntries(matching: predicate) .reversed() // Workaround: `store.getEntries(with: .reverse, matching: predicate)` で降順(新しいログが先)に返されるはずだが、iOS 16時点では機能しないため、ここで逆順にしている。 // ※追記:iOS 17で直っていました! } }
2. ログ確認ツールで扱いやすいデータに変換する
OSLogEntry のメッセージをデコードする
読み出した OSLogEntry の composedMessage には行動ログの中身が入っていますが、この時点ではただのJSON文字列です。以下のようなコードで中身をデコードしてアプリ内ログ確認ツールで扱いやすくします。
OSLogEntry のままでは category *6 (先ほどの例では "ActivityLog" という値)を参照できないので、OSLogEntryWithPayload にダウンキャストします。
import OSLog struct LogEntryResolver { /// OSLogEntryから必要な情報を取りだして、アプリ内ログ確認ツールで扱いやすいモデルに変換します static func resolve(entry: OSLogEntry) -> CookpadLogEntry? { guard let entryWithPayload = entry as? OSLogEntryWithPayload else { return nil } guard let payload = decode(message: entry.composedMessage, category: entryWithPayload.category) else { return nil } return CookpadLogEntry(id: UUID().uuidString, date: entry.date, payload: payload) } }
行動ログの定義ドキュメントとの紐付け
クックパッドでは、Markdown形式のログ定義から型安全なログ実装用コードを生成するために daifuku *7 というライブラリを使っています。
今回はその仕組みを応用し、アプリ内ログ確認ツールからログ定義ごとの解説情報を参照できるコードを自動生成するようにしました。*8
ログ定義ごとの解説情報の用意
例えば、下記のように解説情報のためのstructを定義します。
struct ActivityLogDefinition: Hashable { /// ログイベントカテゴリ(例: `sagasu` ) var category: Category /// ログイベント(例:`show_content`) var event: Event struct Event: Hashable { /// ログイベント名(例:`show_content`) var name: String /// ログイベントの解説文(例:`さがすタブのコンテンツが画面に表示された時に送信されます。`) var description: String /// ログイベントに付加されるパラメーター var parameterNotes: [ParameterNote] /// 各ログに付加されるパラメーターについての解説 struct ParameterNote: Hashable { /// パラメーターのキー名(例:`hashtag_ids`) var name: String /// パラメーターの解説文(例:`表示されたハッシュタグID`) var description: String /// パラメーターのSwiftでの型名(例: `String?` ) var swiftType: String } } }
適当にRuby スクリプトを書いて、daifukuを使ってログ定義Markdownの情報を扱い、テンプレートをもとにログ解説情報を Swift の enum として自動生成します。
Markdown からログ定義の enum を生成するRubyスクリプトの例 https://github.com/cookpad/daifuku/blob/e3cbfd1066fd7704b8210696aa90d5546ff6857d/example/iOS/generate-log-classes.rb
自動生成用のテンプレートファイル (.erb) の例
// This file is automatically generated by generate-log-classes. extension ActivityLogDefinition { enum Category: String, Hashable, CaseIterable { <%- categories.each do |category| -%> case <%= category.variable_name %> = "<%= category.name %>" <%- end -%> } } extension ActivityLogDefinition.Category { var description: String { switch self { <%- categories.each do |category| -%> case .<%= category.variable_name %>: return """ <%- category.descriptions.flat_map(&:lines).each do |description_line| -%> <%= description_line.strip %> <%- end -%> """ <%- end -%> } } var events: [ActivityLogDefinition.Event] { switch self { <%- categories.each do |category| -%> case .<%= category.variable_name %>: <%- if category.available_events.empty? -%> return [] <%- else -%> return [ <%- category.available_events.each do |event| -%> .init( name: "<%= event.name %>", description: """ <%- event.descriptions.flat_map(&:lines).each do |description_line| -%> <%= description_line.strip %> <%- end -%> """, parameterNotes: [ <%- event.columns.each do |column| -%> .init( name: "<%= column.original_name %>", description: """ <%- column.descriptions.flat_map(&:lines).each do |description_line| -%> <%= description_line.strip %> <%- end -%> """, swiftType: "<%= column.swift_type %>" ), <%- end -%> ] ), <%- end -%> ] <%- end -%> <%- end -%> } } }
こうして用意した解説情報を、送信済みログと紐付けます。
送信済みログとの紐付け
送信済みログの中身に含まれる eventCategory と eventName の値から、どのログ定義かは一意に定まります。下記のように、送信済みログのペイロードからログ定義解説情報を参照できるようにしました。
extension ActivityLogPayload.DefinitionKey { /// 行動ログの定義ごとの解説情報 var definition: ActivityLogDefinition { guard let category = ActivityLogDefinition.Category(rawValue: eventCategory), let event = category.events.first(where: { $0.name == eventName }) else { fatalError("ログ定義が見つかりませんでした") } return ActivityLogDefinition(category: category, event: event) } }
3. 便利な機能を色々実装する
あとは「扱いやすくした送信済みログ」と「解説情報」を材料として、自由に料理して好みの画面をつくるだけです。ここでは雑多にいくつかのトピックをご紹介します。
チェックリスト機能
チェックリスト機能は、次のような単純な実装です。
- チェックリストに登録したログ定義のキーを UserDefaults で保持しておく。
- 送信済みログの中に、そのキーと一致するログが1つでもあれば、チェックリスト上でそのログ定義を「送信済み」にする。
ネットワーク通信のログにも対応
行動ログだけでなく、ネットワーク通信のログも見られるようにしています。実際にアプリを操作しながら、どのAPIエンドポイントがどのタイミングで使われているのか、すぐに確認できるのは便利です。


Charles や Proxyman などのサードパーティーアプリのほうが高機能ですし網羅性も高い*10ですが、常に起動しているとも限らないですし、いざ使いたいときにちょっと手間がかかります。

例えば、特定の画面がエラーになるといった障害が発生したとき、アプリ単体でも素早く調査できたのは便利でした。発生条件の特定や原因の切り分けがスムーズにできると、より焦らずに対応できます。
なお、ネットワーク通信のログについては OSログには送らず、メモリ上に保持しています。 *11
実装に関して調査しやすくする

行動ログの集計・分析ショートカットと同様に、ネットワーク通信のログを見にきた人はAPIや実装に関して色々調査をしたいはずだということで、以下の社内Webサービスへのリンクを用意しています。
- APIサーバーに対して実際のリクエストを手軽に試せる「API3 Console」
- APIサーバーのスキーマ定義からドキュメントを提供する「Garage Playground*12」
- ソースコードやタスク、プロジェクトの管理をしている「GitHub Enterprise」
例えば 「実装箇所を GitHub Enterprise(GHE)で表示する」ボタンは、レポジトリ内のSwiftコードの検索結果のURLを開くだけですが、秒で利用箇所が見つかるのは思っている以上に便利です。
小ネタですが、次のような工夫も入れています。
// recipeID, userID などを含むURLは、GHE検索時にヒットせず不便なので * に変換している // (例: `/v1/recipes/:id`, `/v1/users/:id/visited_recipes` など) let query = request.url.path.replacingOccurrences(of: "/([0-9]+)(/|$)", with: "/*$2", options: .regularExpression)
SimulatorではURLコピーに

さらに小ネタですが、iOS Simulatorで開発中にこのボタンを使うと、Simulator内のSafariが開いてしまい不便*13だったので、こんな対策をしました。 Simulator実行時は URLをクリップボードにコピーするので macOS側 ですぐ開けます。iPhone/iPadの実機では実機のブラウザが開きます。
// リンクボタンの実装例 var body: some View { #if targetEnvironment(simulator) buttonForSimulator(targetURL) #else buttonForRealDevice(targetURL) #endif } private func buttonForSimulator(_ targetURL: URL) -> some View { CopyTextButton( stringToCopy: targetURL.absoluteString, labelTitleForCopied: "URLをコピーしました(Simulator内のSafariで開くと不便なので)" ) { label } } private func buttonForRealDevice(_ targetURL: URL) -> some View { Link(destination: targetURL) { label } .contextMenu { // 実機でも長押しメニューから一応コピーできるようにしている CopyTextButton(stringToCopy: targetURL.absoluteString) { Label("URLをコピー", systemImage: "doc.on.doc") } } }
import SwiftUI struct CopyTextButton<Content: View>: View { var stringToCopy: String var labelTitleForCopied: String @ViewBuilder var content: Content init(stringToCopy: String, labelTitleForCopied: String = "コピーしました!", @ViewBuilder content: () -> Content) { self.stringToCopy = stringToCopy self.labelTitleForCopied = labelTitleForCopied self.content = content() } @State private var isCopied = false var body: some View { Button { UIPasteboard.general.string = stringToCopy print("[LogChecker] Copied to the pasteboard: \(stringToCopy)") Task { defer { isCopied = false } isCopied = true try? await Task.sleep(for: .seconds(3)) } } label: { if isCopied { Label(labelTitleForCopied, systemImage: "doc.on.doc") .font(.callout) .foregroundColor(.secondary) .imageScale(.small) } else { content } } } }
振り返って
よかったこと
このログ確認ツールは、色んな面で開発を楽しくできました。
ログの実装・確認がつらくなくなる
「大事だけど正直面倒な作業」とも感じていたログの実装や確認を幾分か快適にできたと思います。個人的にはアプリ内ログ確認ツールを使いはじめてからは「ちょっと楽しいまである」という気持ちに変化していました。同僚からもSlackなどで「すごい見やすくなってる!」「はちゃめちゃに助かっている」「課金したい」といったポジティブな反応をもらえています。
自由に実験できる環境で遊べる
Viewについては、すべてSwiftUIで実装しました。
普段、一般ユーザー向けに開発している画面は SwiftUI (場合によっては UIKit)を採用していますが、全体的には VIPER アーキテクチャで、画面遷移も UINavigationController をベースに使っています。
今回は開発者用ツールということもあって、サポートOSバージョンや不具合などはそこまで気にしなくても済む状況でした。むしろ、こういう機会に積極的に新しい技術を試して、知見を貯めるほうが望ましいでしょう。
チームで合意をとり、ログ確認ツールに関しては @available(iOS 16.0, *) (今なら iOS 17)をつけて、最新のSwiftやSwiftUIの機能を使い放題にしました。制約なく技術を楽しめるエンジニアにとってのオアシスのような場所です。
例えば NavigationStack や NavigationSplitView など、普段使っていないSwiftUIの画面遷移関連も試しています。
正規表現を使う箇所では、RegexBuilder も試しました。
「ViewThatFitsを使えば、簡単に解決できてすごく便利だ」「この書き方、iOS 17から deprecated になるのか!」「これ便利だけど、この挙動は気を付けないと不具合を生み出しそうだ……」
このように自由に実践して得られた知見や肌感覚は、ただ楽しいだけではなく、近い将来のユーザー向け機能の開発をスムーズにして、とても役立ちます。
欲しいものを作れると楽しい
あったらいいなを次々と実現するのが純粋に楽しかったです。 *14

開発者向けツールはユーザーが自分でもあるので、ニーズの理解も、真に解決できているのかの実感もすぐできます。 作ってみて、試しに使って、新たな発見があってまた作る、この改善が爆速で進められます。
業務にしっかり役立つ「仕事」ではあるものの、楽しくてついやってしまう「趣味」でもあり、「趣味の仕事」という言葉が社内で流行していました。このアプリ内ログ確認ツールも趣味の仕事の一例です。
改善したいこと
ログの読み込みを速くしたい
OSログは書き込みは良いですが、読み込みは遅いようです。
os.signpost と Instruments を使って計測してみると、.getEntries*15 の1行だけで圧倒的に時間がかかっています。
動作環境によって大きく差があり、気にならない程度のときもあれば10秒近くかかってさすがに使いづらいと感じるときもあります。Simulatorと実機の差、OSログに溜まった量の差などいくつか要因がありそうな気もしつつ、詳しくはまだ調べられていません。
画面表示毎に更新すると読み込みで待ちすぎるので、今はキャッシュ層を挟んで更新頻度を下げています。
まとめ
今回は、アプリ内ログ確認ツールの機能や実装方法、分かったことについてご紹介しました。
まだ改善の余地はありますが、ちょっとした工夫の積み重ねによって開発を快適にする目的は一定達成できたと感じています。
日々のサービス開発をより良くするために、この記事が何か少しでも参考になったら幸いです。
*1:このツールは開発版ビルドのみに含まれており、App Store版では利用できません。
*2:SwiftUIで作られた画面なので .blur(radius:) を適当につけるだけで簡単にぼかせて、こういうGIFをつくるときに便利です。
*3:なお、Xcode 15 では Debug Console が強化され、重要度やログの種類ごとにフィルタリングできるなど便利になりました。https://developer.apple.com/videos/play/wwdc2023/10226/
*4:ここでの「送信済み」とは、アプリの起動から終了までの間での話です。アプリを再起動すると、すべて「未送信」に戻ります。
*5:https://developer.apple.com/videos/play/wwdc2020/10168/ より
*6:https://developer.apple.com/documentation/oslog/oslogentrywithpayload/3366053-category
*7:ちなみに daifuku の由来は「大福帳」から。クックパッドでは、2020年頃に新しいログの仕組み、通称「大統一アクティビティログ」を導入した際に、すべてのカラムが1つのテーブルに横長に存在する非正規化された「大福帳型テーブル」に行動ログを集積するようになりました。https://techlife.cookpad.com/entry/2020/12/29/004145
*8:ここでは詳細を省いていますが、デモアプリを後々公開できればと思っています。
*9:このJSONの表示部分は、同僚のNiaさんの SwiftUI で JSON を表示する View を使わせてもらいました。https://gist.github.com/niaeashes/e2c927c8d5ddac3b161e2dbe6f0e75b8
*10:アプリ内ログ確認ツールでは、自社のAPIクライアントを経由する通信のみに対応しています。例えば、 Firebase などサードパーティーライブラリの通信は対象外です。
*11:元々はURLとステータスコード程度の簡素な情報だけだったのでOSログに入れていましたが、同僚のVincent さん が response body も含める対応や、GraphQL の POST request への対応をしてくれました。APIクライアントに interceptor として追加し、一定量までメモリ上に保持するようになっています。
*12:クックパッドでは Garage と呼ばれるRESTful Web API 開発を楽にするライブラリが標準的に使われています。https://techlife.cookpad.com/search?q=Garage
*13:Simulator内のMobile Safariでも使えることは使えますが、ログインが必要で「うーーーん」となってしまいました。macOS側で開けるほうが快適そうです。
*14:Cookpad TechConf 2022のLTでも「めちゃくちゃ楽しかった仕事の話をさせてほしい〜iOSアプリのログ編〜」として発表しています。動画: https://youtu.be/2HitJxXXzwY?t=1325
*15:https://developer.apple.com/documentation/oslog/oslogstore/3204125-getentries