技術部の笹田(ko1)と遠藤(mame)です。クックパッドで Ruby (MRI: Matz Ruby Implementation、いわゆる ruby コマンド) の開発をしています。お金をもらって Ruby を開発しているのでプロの Ruby コミッタです。
本日 12/25 に、ついに Ruby 3.1.0 がリリースされました(Ruby 3.1.0 リリース )。今年も Ruby 3.1 の NEWS.md ファイルの解説をします。NEWS ファイルとは何か、は以前の記事を見てください。
- プロと読み解く Ruby 2.6 NEWS ファイル - クックパッド開発者ブログ
- プロと読み解くRuby 2.7 NEWS - クックパッド開発者ブログ
- プロと読み解くRuby 3.0 NEWS - クックパッド開発者ブログ
本記事は新機能を解説することもさることながら、変更が入った背景や苦労などの裏話も記憶の範囲で書いているところが特徴です。
今回リリースする Ruby 3.1 は総論として、Ruby 3.0との互換性を重視したリリースとなっています。 つまり、あまり大きな非互換はありません。 比較的アップグレードしやすいと思いますので、みなさん是非試してみてください。
ちなみに、Ruby 2.6はあと4ヶ月でEOL(サポート終了)で、Ruby 2系列最後の2.7も1年4ヶ月でEOLになると思われます。 月日が立つのは早いですね。
Ruby 3.1 の目玉として、次のようなものがあげられています。
- ハッシュリテラルやキーワード引数の省略記法の導入
- 新しいJITコンパイラであるYJITの導入による性能向上
- 開発環境の向上
- デバッガの刷新
- エラー箇所に下線をひく
error_highlightの導入 - IRB のオートコンプリートとドキュメント表示
本記事では、これらを含めて NEWS ファイルにあるものをだいたい紹介していきます。
■言語の変更
ハッシュやキーワードの省略記法が導入された
- Values in Hash literals and keyword arguments can be omitted. [Feature #14579]
{ x: x, y: y } の省略記法として { x:, y: } と書けるようになりました。
x = 1 y = 2 # h = { x: x, y: y } と同じ意味 h = { x:, y: } p h #=> {:x=>1, :y=>2}
また、キーワード引数でも同様の省略ができるようになりました。
def foo(a:) p a end a = 1 # foo(a: a) と同じ意味 foo(a:)
この機能の導入には実に6年の歳月がかかりました。
最初は、JavaScript(ECMAScript 6)の { x, y } と同じものが Ruby にも欲しい、という提案でした(Feature #11105)。
しかし、この記法は数学の集合にしか見えない(実際、Pythonではこの記法でSetが作られます)ということで、却下されました。
それから2年ほど経ち、{ x:, y: }という記法が提案されました(Feature #14579)。
これはコロンが入っているので、数学の集合の表記と誤解することはありません。
また、必須キーワード引数を受け取る記法 def foo(x:, y:) と似ているので、既存の記法との親和性も一応ありました。
しかしながら、JavaScript と異なる記法で導入して良いのか確信が持てないことや、記法の必要性に確信が持てなかったことなどから、一旦却下されました。
しかしその後、複数の人達から、同様の提案が断続的に送られてきました。 これにより、記法の需要が確からしいことがわかってきました。 そして、RubyKaigi Takeout 2021の延長戦でこの記法の話が上がり、ついにmatzが承認するに至り、この度無事に導入されました。
提案および実装をしたshugoさんの記事も合わせてご覧ください。
(mame)
ブロックを移譲する記法が導入された
- The block argument can now be anonymous if the block will only be passed to another method. [Feature #11256]
def foo(&) bar(&) end
ブロックを受ける引数を無名にして渡すことができるようになりました。意味的には、次のように引数の名前をつけたものとほぼ同じです。
def foo(&b) bar(&b) end
元々の提案では、& で受けて & で渡せば Proc オブジェクトにしなくても良いから速いよね、というものでしたが、Ruby 2.5 で Lazy Proc Allocation が導入されたので、性能の利点はなくなりました。単に、無名で Procを受け、渡すことができる、というものです。名前を考えるのが面倒なときに便利です。&_ でいいじゃん、という気もしますが、若干気軽、なのかな?
受け取った引数をすべて受け渡したいということであれば、Ruby 2.7で導入されたArgument forwardingを使えばよいのですが、ブロックを受ける引数だけ、特別扱いしたい、というのは時々あるので、専用の構文が導入されました。
ちなみに、括弧を書かずにこの構文を使うと、次の行に変数名があると解釈されます。
def foo & a #=> def foo(&a) と解釈される p a #=> #<Proc...> end foo{}
ただ、似たような話である [Bug #18396] は、改行で引数の解釈を止めちゃってもいいかな、という議論もあるので、これも改行で引数の解釈を止める(上記例だとdef foo(&) と解釈される)ように変わるかもしれませんね。
というわけで、今のところ括弧をつけて利用するのが良いと思います。
この提案のもう少し先の話ですが、「ブロックを使わないメソッド」にブロックを渡したら警告したい、という話があります。例えば、Kernel#pはブロックを受け取りませんが、p{raise}はブロックを無視して動いてしまいます。うっかり「ブロックを取るだろう」と思っているメソッドにブロックを渡すバグって、時々ありますよね。あれを防ぎたい。
一度、これができないか試してみたことがあるんですが([Feature #15554]。ブロックを受けないProc.newが禁止された一つの理由)、意図的にブロックを無視するような書き方が若干あって、できなかったんですよね。今回、無名のブロックを受ける引数が入ったので、意図的ならこれ(&)を1個書いておいて、って言いやすくなるかもしれません。
(ko1)
パターンマッチの改善
パターンマッチが正式な言語機能になった
- One-line pattern matching is no longer experimental.
一行パターンマッチのexperimentalが外れました。つまりRubyの正式な言語機能になりました。
ary = [1, 2, 3] # 一行パターンマッチ(右代入の形式) ary => [x, y, z] p x #=> 1 p y #=> 2 p z #=> 3
一行パターンマッチには上記の右代入の形式(マッチ失敗したら例外になる)だけでなく、in演算子の形式(マッチの成否を真偽値として返す)があり、こちらも正式になりました。
ary = [1, 2, 3] # 一行パターンマッチ(in演算子の形式) if ary in 1, 2, z p z #=> 3 end
Ruby 3.0ではこれらの構文を使うと「experimentalである」という警告が出ていましたが、Ruby 3.1では出ません。
(mame)
一行パターンマッチのカッコが省略できるようになった
- Parentheses can be omitted in one-line pattern matching. Feature #16182
一行パターンマッチで、カッコが省略できるようになりました。 右代入での多重代入っぽい記法が、より多重代入っぽく書けます。
ary = [1, 2, 3] # カッコ省略した一行パターンマッチ ary => x, y, z # ary => [x, y, z] と同じ意味
配列パターンだけでなく、ハッシュパターンでもカッコが省略できます。
h = { a: 1, b: 2, c: 3, d: 4 }
h => a:, b:, c:
# h => { a:, b:, c: } と同じ意味
p a #=> 1
p b #=> 2
p c #=> 3
上記は右代入の形式ですが、in演算子でも同様に省略できます。
ちなみに1行パターンマッチは、普通の式として使えない式になっています。 これはパーサの技術的な制限によるのですが、次の例を考えると、何がむずかしいのかがわかるのではないかと思います。
# これは SyntaxError になる foo(ary in x, y, z) # foo((ary in x), y, z) なのか、 # foo((ary in x, y), z) なのか、 # foo((ary in x, y, z)) なのかが決まらない
まあ、右代入の形式は文として、in演算子はif文の条件式としてのみ使うようにするのが無難だと思います。
(mame)
パターンマッチのピン演算子に任意の式が書けるようになった
- Pin operator now takes an expression. [Feature #17411]
- Pin operator now supports instance, class, and global variables. [Feature #17724]
パターンの中に式を書けるピン演算子が導入されました。
ary = [1, 2, 3] # ^ がピン演算子 if ary in [x, ^(1 + 1), z] p x #=> 1 p z #=> 3 end
このif文はif ary in [x, 2, z]と同じ意味になります。
つまり、^(1 + 1)のところは、2にマッチするパターンとなります。
正確に言うと、式のところがローカル変数であるピン演算子はRuby 3.0でも許されていました。 Ruby 3.1からは、その位置に任意の式を書けるようになりました。ただしかっこが必要です。
ary = [1, 2, 3] val = 2 # Ruby 3.0でも3.1でも動く in ary in [x, ^val, z] p x #=> 1 p z #=> 3 end # Ruby 3.1から書ける(かっこが必要) in ary in [x, ^(1 + 1), z] p x #=> 1 p z #=> 3 end # すでにマッチした変数パターン`x`を参照することもできる in ary in [x, ^(x + 1), z] p x #=> 1 p z #=> 3 end
なお、インスタンス変数、クラス変数、グローバル変数はかっこなしでピン演算子に書けます。
ピン演算子のカッコの中に副作用のある式(^(p(1))とか)を書くこともできてしまいますが、書かないようにしましょう。
(mame)
多重代入の評価順序が変更された
- Multiple assignment evaluation order has been made consistent with single assignment evaluation order. (略) [Bug #4443]
多重代入の評価順が微妙に変更されました。次の例で説明します。
foo[0], bar[1] = a, b
Ruby 3.0までは、次の順で評価されていました。
abfoobar(fooの評価結果)[0] = (aの評価結果)(barの評価結果)[1] = (bの評価結果)
aやbが、fooやbarより前に評価されていることに注意してください。
Rubyの評価は原則として「左から右」なのですが、この評価順序は微妙にこの原則に反しています。
似た代入式である foo[0] = a は、次のように原則通りの順序で評価されます。
fooa(fooの評価結果)[0] = (aの評価結果)
つまり、多重代入のときだけ評価順序が逆転するという問題がありました。 Ruby 3.1ではこれが修正され、原則通り、次の順序で評価されるようになります。
foobarab(fooの評価結果)[0] = (aの評価結果)(barの評価結果)[1] = (bの評価結果)
ちなみにこれは11年前に私が報告したのですが、いろいろあって忘れられていた問題でした。 今回、Jeremy Evansというコミッタがチケットを発掘し、修正してくれました。
Jeremyは近年、放置されているチケットをcloseしていく活動を続けてくれています。 聞くところでは、数千以上あったopen状態のバグ報告チケットが、最近では350程度にまでなったそうです。すごい。
(mame)
main Ractor 以外でも、クラスとモジュールのインスタンス変数を参照することができるようになった
- Non main-Ractors can get instance variables (ivars) of classes/modules if ivars refer to shareable objects. [Feature #17592]
これまで、あらゆるインスタンス変数は main Ractor(起動時に自動的に生成される Ractor、ふつうは意識することは無い)しか読み書きできなかったのですが、これを他の Ractor でも、格納されている値が shareable であれば、読めるようになりました。
class C @a = 1 def self.a = @a end Ractor.new do p C.a #=> 1 end.take
この変更で、プロセスグローバルな設定を、クラスやモジュールのインスタンス変数に格納することができるようになりました。
個人的にはこの変更は、レースコンディションが生まれてしまうため、反対でした。例えば、@a、@bというアトミックに扱わなければならない2変数があるとき、main が片方を変更中にほかの Ractor が両方を読んでしまうと、中途半端な @a、@bのペアを読むことになってしまいます。
このようなことがないように、Transactional Memory などが提案されているんですが、去年提案しても入らなかったし、現実的に問題は生まれなさそうだし(2つ以上のアトミックに扱わなければならないデータってそもそもそんななさそう)、しょうがないかと思って観念しました。
というわけで、これを利用する場合は、問題が起こらないように、
- 初期化時にしかセットしない(ほかのRactorがいなければ問題ない)
- 複数のアトミックに扱わなければならないインスタンス変数は使わない(必要なら配列やハッシュにする)
などを心がけていただければと思います。
(ko1)
一行メソッド定義でカッコなしメソッド呼び出しが書けるようになった
- A command syntax is allowed in endless method definitions, i.e., you can now write
def foo = puts "Hello". Note thatprivate def foo = puts "Hello"does not parse. [Feature #17398]
次のとおりです。
# Ruby 3.0でも書けた def foo = puts("Hello") # Ruby 3.1で書けるようになった def foo = puts "Hello"
ただ、パーサの技術的な制約により、次のコードは書けません。
# private をつけたら SyntaxError private def foo = puts "Hello"
(mame)
■コマンドライン引数の変更
--disable-gemsis now explicitly declared as "just for debugging". Never use it in any real-world codebase. [Feature #17684]
RubyGemsを無効化するオプションはデバッグ専用以外に使うべきでないと宣言されました。
$ ruby --help ...(略)... Features: gems rubygems (only for debugging, default: enabled)
RubyGemsはRuby 1.9のころに標準装備となりましたが、当時はまだRubyGemsを使わないユーザも少なくなかったので、このオプションが導入されました。
しかし現代ではRubyGemsを使わないことが珍しくなり、このオプションの意義が薄くなっていました。
一方で、「--disable-gemsの下でgemが動くようにしてほしい」というバグ報告がたびたび観測されるようになり、逆に非生産的になっているということで、--disable-gemsが事実上廃止となりました。
なお、完全に削除されなかったのは、Rubyインタプリタの開発者がデバッグ時にこのオプションを使うことがあるためです。 よって、普通のコードではもう使わないでください。
(mame)
--jit,--mjit,--yjit
JIT関連のオプションが変わりました。あとでまとめて紹介します。
(ko1)
■組み込みクラスのアップデート
共通要素の有無を判定するArray#intersect?が導入された
- Array
- Array#intersect? is added. [Feature #15198]
2つの配列に共通の要素があるかどうかを調べるメソッド Array#intersect? が導入されました。
# 2 が共通しているので true になる [1, 2, 3].intersect?([0, 2, 4]) #=> true # 共通の要素がないので false になる [1, 2, 3].intersect?([4, 5, 6]) #=> false
(mame)
子クラスの一覧を得るClass#subclassesが導入された
- Class
- Class#subclasses, which returns an array of classes directly inheriting from the receiver, not including singleton classes. [Feature #18273]
クラスから子クラスの一覧を得るClass#subclassesが導入されました。
class A; end class B < A; end p A.subclasses #=> [B]
Railsの中でしばしば必要になっているということで導入されました。
Class#inherited を定義して子クラスの一覧を自力で把握するコードを書いたことがある人はそこそこいるのではないでしょうか。
これは一見かんたんに見える機能でしたが、実装を安定させるのが意外と大変でした。
というのも、子クラスへの参照は弱参照(weak reference)なんですよね。
Rubyではクラスはオブジェクトなので、定数などに代入されていない無名クラスはGCに回収されてしまいます。
現在の実装では、各クラスは子クラスのリストを管理しているのですが、Class#subclassesがそのリストをたどっている最中にGCが発生した場合、現在たどっていた位置のリストノードがfreeされてしまい、segmentation faultが起きていました。
Railsのテストで実際に発生するので、3.1.0-preview1のリリース前後で泣きながら直していました。
なお、subclassesが返すのは直属の子クラスのみです。
class A; end class B < A; end class C < B; end # 直接の子クラスは B のみ(C は含まない) p A.subclasses #=> [B]
Ruby 3.1リリース直前まで、子孫クラスすべての一覧を返すClass#descendantsも導入予定だったのですが、モジュールの扱いをどうするべきか検討が必要などの理由でリリース1週間前に見送りとなりました。
(mame)
なお、Class#descendantsが Ruby 3.1 に入るという想定で Rails 7.0.0 がリリースされたのですが、入らなかったので Rails 7.0.0 は Ruby 3.1.0 に対応していません(やってみるとエラーが出ます)。すでに開発版では対応されているので(Remove feature checking for Class#descendants ・ rails/rails@bc07139 )、Rails 7.0.1 に期待ですね。
(ko1)
nilを取り除くEnumerable#compactが導入された
- Enumerable
- Enumerable#compact is added. [Feature #17312]
- Enumerator::Lazy
- Enumerator::Lazy#compact is added. [Feature #17312]
Enumerableの要素からnilを取り除いた配列を返すEnumerable#compactが導入されました。
class Foo include Enumerable def each yield 1 yield 2 yield nil yield 3 end end p Foo.new.to_a #=> [1, 2, nil, 3] p Foo.new.compact #=> [1, 2, 3]
Array#compactをEnumerableでもできるようにしたということですね。
また、これのlazy版であるEnumerable::Lazy#compactも導入されました。
[1, 2, nil, 3].lazy.compact.each {|x| p x } #=> 1, 2, 3
これはcompactの時点では配列を作らないので、要素数が非常に多いときには効率的になります。
(mame)
Enumerable#tallyがハッシュを受け取るようになった
- Enumerable
- Enumerable#tally now accepts an optional hash to count. [Feature #17744]
要素数をカウントするEnumerable#tallyに、カウント結果を格納・蓄積するハッシュを指定できるようになりました。
ary = ["A", "B", "C"] # これは従来どおりの挙動 p ary.tally #=> {"A"=>1, "B"=>1, "C"=>1} # 空のハッシュを渡すと、そのハッシュを使ってカウントする h = {} ary.tally(h) p h #=> {"A"=>1, "B"=>1, "C"=>1} # そのハッシュを再度tallyに渡すと、カウント結果を加算してくれる ["A"].tally(h) p h #=> {"A"=>2, "B"=>1, "C"=>1}
最後の実行結果で "A" のカウント数が 2 になってるところがポイントです。
これにより、カウントしたい要素の列があらかじめ揃っていなくても、続きからカウントを再開できるようになりました。
卜部さんが見つけたベンチマークプログラムがきっかけで導入された機能です。
これRubyもうちょいなんとかならんのですか https://t.co/2siYra5LHm
— 7594591200220899443 (@shyouhei) March 16, 2021
(mame)
Enumerable#each_consとeach_sliceがselfを返すようになった
- Enumerable
- Enumerable#each_cons and each_slice to return a receiver. [GH-1509]
Array#eachなど多くのeach系メソッドはselfを返すのですが、なぜかeach_consとeach_sliceはnilを返していました。
これが修正されました。
[1, 2, 3].each_cons(2){} # 3.0 => nil # 3.1 => [1, 2, 3] [1, 2, 3].each_slice(2){} # 3.0 => nil # 3.1 => [1, 2, 3]
(mame)
File.dirname(name, level)で、ディレクトリのレベルを指定することができるようになった
- File.dirname now accepts an optional argument for the level to strip path components. [Feature #12194]
パス名を受け取り、ファイル部分を削除してディレクトリ名を返すメソッドである File.dirname に、親ディレクトリを何個たどって返すかを指定する第二引数 level が追加されました。
こんな感じです。
p File.dirname('/home/ko1/foo.txt') #=> "/home/ko1" p File.dirname('/home/ko1/foo.txt', 0) #=> "/home/ko1/foo.txt" p File.dirname('/home/ko1/foo.txt', 1) #=> "/home/ko1" p File.dirname('/home/ko1/foo.txt', 2) #=> "/home" p File.dirname('/home/ko1/foo.txt', 3) #=> "/" p File.dirname('/home/ko1/foo.txt', 4) #=> "/"
(ko1)
GCの実行時間を計測する新しい方法が追加された
- "GC.measure_total_time = true" enables the measurement of GC. Measurement can introduce overhead. It is enabled by default. GC.measure_total_time returns the current setting. GC.stat[:time] or GC.stat(:time) returns measured time in milli-soconds.
- GC.total_time returns measured time in nano-seconds. Feature #10917
GCの時間を計測する新しい方法 GC.stat(:time)(ミリ秒で返る)、および GC.total_time(ナノ秒で返る)を追加しました。
ただ、GCの時間を正確に計測しようとすると、時間を測るためのオーバヘッドがかかってしまうため、GC.measure_total_time = trueのように、on/off の制御ができるようになっています。デフォルトは on です。つまり、遅くなります! が、ここのオーバヘッドが現実に効くようなケースは滅多にないだろうと思ってデフォルト on になっています。
これまでも、GC::Profilerを使う方法がありましたが、Sweepの時間などを計測しないなど、問題がありました。そこで、その辺正確に測るための仕組みを入れました。GC.stat(:time)がミリ秒なのは、JRubyなどですでに同じフィールドがミリ秒で返しているらしく、そのことの互換性を要求されたためです。
(ko1)
Integer.try_convertが導入された
- Integer
- Integer.try_convert is added. [Feature #15211]
to_intを使って引数のInteger化を試みるInteger.try_convertが導入されました。
# Integerならそのまま p Integer.try_convert(1) #=> 1 # FloatにはFloat#to_intがあるので変換される p Integer.try_convert(1.0) #=> 1 # String#to_intはないのでnilが返される p Integer.try_convert("1") #=> nil
String.try_convertやArray.try_convertなどとの対称性のためのようです。
(mame)
Kernel#loadの第二引数で任意のモジュールを指定できるようになった
- Kernel#load now accepts a module as the second argument, and will load the file using the given module as the top-level module. [Feature #6210]
Kernel#load(file) は、require のようにファイルを読み込み、Ruby プログラムとして評価するメソッドです。
# x.rb def foo = p(:foo)
# main.rb load(File.join(__dir__, 'x.rb')) foo() #=> :foo
この例では、x.rb に定義されてあるメソッド foo が、トップレベルに定義されています。
ただ、メソッドや定数(クラスやモジュール定義含む)をトップレベルに定義されると困ることがあるかもしれません。そこで、Kernel#load(file, true)と第二引数にtrueを与えると、匿名のモジュールの中で定義され、実行されます。
load(File.join(__dir__, 'x.rb'), true) foo() #=> undefined method `foo'
このとき、x.rbは、
Module.new do # ここに x.rb の中身が入る def foo = p(foo) # ここまで end
こんな感じで実行されます。厳密には self が違ったり、実はそのモジュール自体を extend していたり、いろいろ違うんですが、まぁ大雑把にはこんな感じです。ちなみに、ロードされるファイル(x.rb)でModule.nestingなどでその無名モジュールを見ることができます。
この第2引数に、true/falseではなく、モジュールを直接与えて、自動的に無名モジュールを作るのではなく、利用するモジュールを指定できるようになりました。
module M; end load(File.join(__dir__, 'x.rb'), M) # M#foo が定義される # foo() #=> undefined method `foo' include M foo() #=> :foo
DSL に使える、のかなぁ?
(ko1)
Marshal.load(data, freeze: true) で frozen object としてロードできるようになった
- Marshal.load now accepts a
freeze: trueoption. All returned objects are frozen except forClassandModuleinstances. Strings are deduplicated. [Feature #18148]
data = Marshal.dump(obj) とすると、シリアライズされたデータを取り出せます。これを、Marshal.load(data) とすることで、Ruby オブジェクトに戻すことができますが、このときfreeze: trueというキーワード引数を加えることで、戻した Ruby オブジェクトを freeze することができるようなりました。
Marshalは、deep copyに利用することができることが知られていますが(文字列の配列の配列、みたいな場合、その文字列と配列を全部コピーするのがdeep copy)、この deep copy 時についでに全部 freeze してまわることができます。
ちなみに、文字列をMarshal.loadで戻す場合は、文字列リテラルでのfreeze("foo".freeze)のように、重複排除が行われます。つまり、同じ文字列は同じオブジェクトが返るようになります(frozen でないと、別の文字列オブジェクトにしなければならない)。
ary1 = ["hello", "hello"] ary2 = Marshal.load(Marshal.dump(ary1)) p ary2[0].object_id == ary2[1].object_id #=> false ary3 = Marshal.load(Marshal.dump(ary1), freeze: true) p ary3[0].object_id == ary3[1].object_id #=> true
(ko1)
正規表現でキャプチャした部分文字列を返すMatchData#matchが追加された
- MatchData
- MatchData#match is added [Feature #18172]
正規表現のマッチ結果から、キャプチャされた部分文字列を返すメソッドが追加されました。
"abcdefg" =~ /(...)(....)/ p $~.match(1) #=> "abc" # $~[1]や$1と同じ p $~.match(2) #=> "defg" # $~[2]や$2と同じ
といっても、MatchData#[]とほとんど同じです。
強いて言うと、Rangeは受け取れないようです($~[1..2]は書けるけど$~.match(1..2)は書けない)。
(mame)
正規表現でキャプチャした部分文字列の長さを返すMatchData#match_lengthが追加された
- MatchData
- MatchData#match_length is added [Feature #18172]
正規表現でキャプチャされた部分文字列の長さを返すメソッドが追加されました。
"abcdefg" =~ /(...)(....)/ $~.match_length(1) #=> 3 # $1.lengthと同じ $~.match_length(2) #=> 4 # $2.lengthと同じ
$1.lengthだと一旦文字列オブジェクトを作ってしまうので、それを避けるために導入されました。
こういう細かい最適化のためにメソッド追加するのではなく、処理系側の改善でどうにかなってほしいなあ。
(mame)
メソッドの可視性をチェックするメソッドが追加された
- Method#public?, Method#private?, Method#protected?, UnboundMethod#public?, UnboundMethod#private?, UnboundMethod#protected? have been added. [Feature #11689]
まぁ見ての通りなのですが、MethodとUnboundMethodにpublic?などの可視性を確認するメソッドが追加されました。
def foo = :foo p method(:foo).public? #=> false p method(:foo).private? #=> true
チケットには pry とかで情報を表示するときに便利、ってありますね。自分は使うことあるかなぁ。
(ko1)
include済みのモジュールに対するprependが継承ツリーに反映されるようになった
- Module#prepend now modifies the ancestor chain if the receiver already includes the argument. Module#prepend still does not modify the ancestor chain if the receiver has already prepended the argument. [Bug #17423]
include と prepend が混ざると混乱するんですが、これはそんな話です。
すでにクラス C に include されたモジュール M が別のモジュール P を prepend しても、Ruby 3.0 までは、C の継承ツリーに P は出てきませんでした。Ruby 3.1 からは、include されたモジュールに対しても P が出現するようになっています。
module P; end module M; end class C include M end M.prepend P p C.ancestors #=> Ruby 3.0: [C, M, Object, Kernel, BasicObject] #=> Ruby 3.1: [C, P, M, Object, Kernel, BasicObject] C.prepend P p C.ancestors #=> Ruby 3.0: [P, C, M, Object, Kernel, BasicObject] #=> Ruby 3.1: [P, C, P, M, Object, Kernel, BasicObject]
まぁ、難しいのであんまり多用しないほうがいいと思います。
(ko1)
privateやpublicなどのメソッドがシンボルなどを返値を返すようになった
- Module#private, #public, #protected, and #module_function will now return their arguments. If a single argument is given, it is returned. If no arguments are given, nil is returned. If multiple arguments are given, they are returned as an array. [Feature #12495]
メソッドの可視性を制御するprivateやpublicなどのメソッドは、従来はselfを返していました(トップレベルではObject)。これを、指定したメソッドのシンボル(や、シンボルの配列)を返すように変更されました。対象が指定されない場合は nil が返ります。
class C p private(def foo; end) #=> Ruby 3.0: C #=> Ruby 3.1: :foo def bar; end p private(:foo, :bar) #=> Ruby 3.0: C #=> Ruby 3.1: [:foo, :bar] p private #=> Ruby 3.0: C #=> Ruby 3.1: nil end
さらにメタプログラミングやっちゃうんですかね。
(ko1)
forkイベントをフックするためのProcess._forkが追加された
- Process
- Process._fork is added. This is a core method for fork(2). Do not call this method directly; it is called by existing fork methods: Kernel.#fork, Process.fork, and IO.popen("-"). Application monitoring libraries can overwrite this method to hook fork events. [Feature #17795]
Process._forkというメソッドが追加されました。
が、普通のコードで使うものではないので、忘れてください。
以下、物好きな人のための解説と裏話です。
一言でいうと、これは、Rubyがforkする瞬間をフックするライブラリのために導入されたメソッドです。
たとえばDataDogのようなアプリケーションモニタは、Rubyプログラム内にスレッドを立ててプログラムの状態を観測します。
しかしスレッドは、forkで作られた子プロセスには継承されません。
そういうライブラリは、forkシステムコールが呼ばれたとき、子プロセス側で速やかに新たな観測スレッドを立ち上げ直す必要があります。
しかし「forkシステムコールが呼ばれたとき」をフックするのは意外とむずかしいことでした。
なぜかというと、Rubyには、forkシステムコールを呼ぶ方法がいくつもあるのです。
Kernel#forkが代表的ですが、Process.forkもあります。
また、Kernel.forkという書き方も稀に使われています。
さらに、ほとんど知られていなかった極秘機能ですが、IO.popen("-")でもforkが可能です。
ActiveSupportにForkTrackerという、forkイベントを追跡するためのモジュールがあるのですが、これらをすべてを適切にフックするのはなかなか大変でした(IO.popen("-")なんかは気づいてなかったようです)。
そこで今回、Rubyがforkシステムコールを呼ぶメソッドをProcess._forkメソッドに一本化しました。
Kernel#forkやProcess.forkやIO.popen("-")たちはすべてProcess._forkを呼びます。
これで、forkイベントをフックしたいライブラリは、Process._forkをオーバーライドするだけでできるようになります。
結論から見るとかんたんな話に見るかもしれませんが、これも提案から導入まで10年かかってます。
当初はfork前後で実行されるブロックを登録するat_forkとして提案されましたが、
- 複数の人が思い思いのユースケースを語っているが、具体的に何が、どうして必要なのか整理されていない
- fork前、fork後(親プロセス側)、fork後(子プロセス側)の3つのフックポイントがあり、どれが実際に必要なのかわからない
- 完全にプロユースの API だが
at_forkはカジュアル感がありすぎる - 複数のライブラリが
at_forkしたとき、何個目のフックが呼ばれているのかがわからない(運悪くフックの処理内容が競合していると例外が起きるかもしれないが、バックトレースを見てもわからない) - Ruby のどこでどのように fork が使われているか把握しきれていない
- すでに自力で
Kernel#forkなどを再定義してフックしているライブラリといい感じに共存できるかわからない
などなど非常に多数の課題があり、停滞していました。
今回、気合を出して交通整理をし、要求と要件をまとめて提案チケットを作り直してもらい、開発者会議で議論を重ねて、「ライブラリにProcess._forkというメソッドをオーバーライドさせる」という形で一応決着させることができました。
(なお、方針が決定してからも、_forkメソッドに一本化する実装が地味に大変だったり、_forkという名前で決まるまでにも2ヶ月くらいかかったり、いろいろ大変でした)
(mame)
Structがkeyword_initされたかどうかを知るメソッドが追加された
- StructClass#keyword_init? is added [Feature #18008]
Structがkeyword_init: trueで定義されているかどうかを返すメソッドが導入されました。
Foo = Struct.new(:foo, :bar, keyword_init: true) p Foo.keyword_init? #=> true
keyword_init: false の場合は false 、未指定の場合は nil を返します。
Bar = Struct.new(:foo, :bar, keyword_init: false) p Bar.keyword_init? #=> false Baz = Struct.new(:foo, :bar) p Baz.keyword_init? #=> nil
なお、将来的には keyword_init キーワード引数は不要にしていく方向です。
詳しくは次の項目を見てください。
(mame)
Structの最初のメンバをキーワード引数で初期化するのがdeprecateされた
Struct
- Passing only keyword arguments to Struct#initialize is warned. You need to use a Hash literal to set a Hash to a first member. [Feature #16806]
Struct#initializeのメンバをハッシュで初期化するとき、ちゃんとハッシュを渡さないとダメになりました。
Foo = Struct.new(:foo) # Ruby 3.0: ハッシュを渡したように動く # Ruby 3.1: Ruby 3.0と同じ(ただし警告が出る) # Ruby 3.2: エラーになる予定 p Foo.new(a: 1, b: 2) # ちゃんとハッシュを渡せばOK(Ruby 3.1で警告は出ず、Ruby 3.2でも動く予定) p Foo.new({ a: 1, b: 2 }) #=> #<struct Foo foo={:a=>1, :b=>2}>
これは何を狙っているかと言うと、明示的なkeyword_initを不要にすることです。 つまりRuby 3.2では次のように書けるようになる見込みです。
Foo = Struct.new(:foo, :bar) # 明示的な keyword_init: true を書かない # Ruby 3.2 では次のように初期化できる予定 p Foo.new(foo: 1, bar: 2) #=> #<struct Foo foo=1, bar=2>
このコードは、Ruby 3.0ではキーワード引数から通常引数への暗黙的変換により Foo.new({foo: 1, bar: 2}, nil) のように解釈されてしまいます。
こういうコードを修正してもらうために、Ruby 3.1では移行措置として、動作自体は維持しつつ、警告を出すようになりました。
Foo.new(foo: 1, bar: 2) #=> warning: Passing only keyword arguments to Struct#initialize will behave differently from Ruby 3.2. Please use a Hash literal like .new({k: v}) instead of .new(k: v).
(mame)
Unicode 13.0.0 が導入された
- Update Unicode version to 13.0.0 [Feature #17750] and Emoji version to 13.0 [Feature #18029]
タイトルの通りなんですが、絵文字もどんどん増えますねえ(Emoji Version 13.0 List)。
(ko1)
String#unpackにoffsetを渡せるようになった
- String
- String#unpack and String#unpack1 now accept an
offset:keyword argument to start the unpacking after an arbitrary number of bytes have been skipped. Ifoffsetis outside of the string boundsArgumentErroris raised. [Feature #18254]
- String#unpack and String#unpack1 now accept an
String#unpack で読み取りを始めるオフセットを指定できるようになりました。
# 65 は "A" の ASCII コード "fooA".unpack("C", offset: 3) #=> [65]
要素をひとつだけ返すString#unpack1も同様に拡張されています。
バイナリデータのパースで便利なこともあるかもしれません。
(mame)
Queueの初期化時に初期値をセットできるようになった
- Thread::Queue#initialize now accepts an Enumerable of initial values. [Feature #17327]
Thread::Queueの初期化時に#to_aメソッドを持っているオブジェクトを指定して初期化できるようになりました。
q = Thread::Queue.new(5.times) 5.times{p q.pop} #=> 0 1 2 3 4
(ko1)
Thread#native_thread_idが追加された
- Thread#native_thread_id is added. [Feature #17853]
ログに表示するために、Rubyのスレッドが現在使っているシステムのスレッドのIDが欲しい、というリクエストに応えるために追加されました。
p Thread.current.native_thread_id #=> 19192
が、そもそも「システムのスレッドID」という概念がなかなか難しいのです。
Rubyのスレッドはシステムが提供するスレッドをどう使うか、理論的にはいろんな方法がありえるわけです。例えば、Ruby 1.8までは、1つのシステムスレッドしか使っていませんでした(その場合、native_thread_id は1つの値しか返さないのでしょう)。現在は1つのRubyスレッドに対して1つのシステムが提供するスレッドを使う実装になっていますが、今後それが変わるかもしれません。そもそも、「システムが提供するスレッド」も、Linux が提供するものだったり、Linux 上で実装されたユーザーレベルスレッドであるかもしれなくて、まぁいろいろです。
というわけで、この値はあるRubyスレッドごとに唯一の固定値が返るわけではない(今はそうだけど)みたいなことを、この辺に興味ある人は覚えておくと良いかと思います。
元々のリクエストは、外部のモニタリングツールで得られた native thread id と Ruby のスレッドとの関連みたいなのが確認したいみたいなので、とりあえずはこれでいいのだと思います。
(ko1)
--backtrace-limitに指定された値を読み出すメソッドが追加された
Thread::Backtrace
- Thread::Backtrace.limit, which returns the value to limit backtrace length set by
--backtrace-limitcommand line option, is added. [Feature #17479]
- Thread::Backtrace.limit, which returns the value to limit backtrace length set by
バックトレースの長さを指定する --backtrace-limit というコマンドライン引数があるのですが、これに渡された値を読み出すメソッド Thread::Backtrace.limit が追加されました。
$ ruby --backtrace-limit 42 -e 'p Thread::Backtrace.limit' 42
エラーメッセージの文字列を模倣して作るライブラリがこれの情報を必要とするとのことでした。
(mame)
Time.new(in: timezone) でタイムゾーンがキーワード引数で指定できるようになった
- Time.new now accepts optional
in:keyword argument for the timezone, as well asTime.atandTime.now, so that is now you can omit minor arguments toTime.new. [Feature #17485]
これまで、タイムゾーンを指定した Time オブジェクトの生成は、
p Time.new(2021, 1, 1, 0, 0, 0, "+09:00") #=> ok: 2021-01-01 00:00:00 +0900
こんなふうにオプショナル引数を全部指定した最後に渡してあげないといけなかったようです。
# チケットに書いてある期待に反する例 Time.new(2021, 1, 1, "+09:00") #=> bad: 2021-01-01 09:00:00 +0900 Time.new(2021, 1, "+09:00") #=> bad: 2021-01-09 00:00:00 +0900 Time.new(2021, "+09:00") #=> ArgumentError (mon out of range)
これを、:in キーワードを受けるようにして、書きやすくしました。
# チケットに書いてある利用例 Time.new(2021, 1, 1, in: "+09:00") #=> ok: 2021-01-01 00:00:00 +0900 Time.new(2021, in: "+09:00") #=> ok: 2021-01-01 00:00:00 +0900
Time.nowやTime.atでも同様にin:キーワードを受けるようになったそうです。
Time.newの引数チェックが厳しくなった
- At the same time, time component strings are converted to integers more strictly now.
というわけで、これまではなんとなく(多分、意図とは異なるように)動いていた次のようなケースでエラーが出るようになりました。
p Time.new(2021, 12, 25, "+07:00") #=> Ruby 3.0: 2021-12-25 07:00:00 +0900 #=> Ruby 3.1: invalid value for Integer(): "+07:00" (ArgumentError)
(ko1)
この変更の背景は、次の Ruby 3.0 の挙動を見るとわかりやすいです。
# Ruby 3.0 Time.new("2021-12-25") #=> 2021-01-01 00:00:00 +0900
直感に反して、1月1日になっていることに注意してください。"2021-12-25".to_i した結果が年として使われ、月日は無指定なのでデフォルトで1として解釈されていました。
このように、明らかに意図と異なると思われるコードが散見されたので、Ruby 3.1 からは引数が文字列の場合にもうちょっと厳しくチェックされるようになりました。
# Ruby 3.1 Time.new("2021-12-25") #=> invalid value for Integer(): "2021-12-25" (ArgumentError)
(mame)
Time#strftimeがRFC 3339 UTCのunknown offset local timeに対応した
- Time#strftime supports RFC 3339 UTC for unknown offset local time,
-0000, as%-z. [Feature #17544]
Time#strftimeが、"%-z"といったフォーマットに対応したようです。Time わからな過ぎてこれ以上書けません。
# テストから抜粋 assert_equal("+0000", t2000.strftime("%z")) assert_equal("-0000", t2000.strftime("%-z")) assert_equal("-00:00", t2000.strftime("%-:z")) assert_equal("-00:00:00", t2000.strftime("%-::z"))
(ko1)
再入を許す TracePoint#allow_reentry が追加された
- TracePoint.allow_reentry is added to allow reenter while TracePoint callback. [Feature #15912]
TracePointは、何かイベントが起こると、指定したコールバックを実行するための仕組みですが、そのコールバックを実行中にTracePointイベントが起こると、どんどんコールバックが再帰してしまって書きづらいです。そのため、これまではコールバックを実行中は、コールバックを許さないようにしていました。
TracePoint.allow_reentry do ... endを使うことで、ブロックの実行中はコールバックを許す、という指定をできるようにしました。使い方を間違えるとすぐに無限再帰してしまうので、注意して使ってください。
というか、正しい制御をするのは多分むっちゃ難しいので使わない方がいいです。
TracePoint.new(:line){|tp| p tp # ここでは reentrance ではない TracePoint.allow_reentry{ # ここは reentrance、なので、またこの callback が呼ばれて無限再帰 p :reentry } }.enable a = 1
デバッガなどでTracePoint機能を利用してプログラムを止めているとき、そこでユーザーが指定するプログラムを評価する、という機能がありますが、そのプログラム中でTracePointのclassイベントが発火してくれないとZeitwerkが困る、というのが一番わかりやすい要求だったんですが、それ以外にもそういう実行の際でのブレイクポイントが効かなくなる、といった話もありました。
まだこれ使ってデバッガを拡張していないんですが、実装しないとなぁ。大変そうだなぁ。
(ko1)
$LOAD_PATH.resolve_feature_pathが失敗時にnilを返すようになった
$LOAD_PATH
- $LOAD_PATH.resolve_feature_path does not raise. [Feature #16043]
$LOAD_PATH.resolve_feature_path はライブラリが見つからなかったときに例外を投げていましたが、nil を返して欲しいという要望があったので変わりました。
p $LOAD_PATH.resolve_feature_path("not-found") #=> nil
(mame)
Fiber scheduler の対応が広がった
- Add support for
Addrinfo.getaddrinfousingaddress_resolvehook. [Feature #17370] - Introduce non-blocking
Timeout.timeoutusingtimeout_afterhook. [Feature #17470] - Introduce new scheduler hooks
io_readandio_writealong with a low levelIO::Bufferfor zero-copy read/write. [Feature #18020]
Fiber scheduler は、ブロックしてしまう処理があるとスケジューリングができなくなるのですが、Addrinfo.getaddrinfoなどにフックを呼ぶようにするような対応が入りました(多分...)。
また、IO::BufferというIOを直接使うために便利な仕組みが導入されました。
- IO hooks
io_wait,io_read,io_write, receive the original IO object where possible. [Bug #18003]
これらのメソッドでは、これまで fd がやってきた(のかな?)のが、IOオブジェクトを直接渡してくれるようになりました。
- Make
Monitorfiber-safe. [Bug #17827]
Monitorが Fiber ごとに効くようになりました。
- Replace copy coroutine with pthread implementation. [Feature #18015]
スタックのコピーで行っていたコルーチン(のための primitive)の実装が、pthread を用いたものに置き換わりました。Ruby 1.8 以前の伝統のスタックコピーによるコンテキスト切り替えが、これでなくなることになります(あれ、まだ callcc のために残ってるかな?)。
(ko1)
Refinement クラスが導入された
- New class which represents a module created by Module#refine.
includeandprependare deprecated, andimport_methodsis added instead. [Bug #17429]
Module#refineはこれまで無名のモジュールを作っていたのですが、これをRefinementという専用クラスで作るようになりました。
module M refine Integer do p self #=> #<refinement:Integer@M> p self.class #=> Ruby 3.0: Module #=> Ruby 3.1: Refinement end end
Refinementでは、includeやprependは非推奨になり、多分将来は使えなくなるのではないかと思います。
その代わり、import_methodsという別の拡張の仕組みが導入されました。
module Div def /(o) Rational(self, o) end end module M refine Integer do import_methods Div end end using M p 1/2
includeと似ていますが、その時点のスナップショットをとってくる、という点が異なります。つまり、include M の場合、Mに変更があると、その変更がincludeしたクラスなどに影響しますが、import_methods Mではその時点のメソッド定義をもってくるので、Mが変わっても影響をうけません。
(ko1)
標準ライブラリの更新
- The following default gem are updated.
- RubyGems 3.3.3
- base64 0.1.1
- benchmark 0.2.0
- bigdecimal 3.1.1
- bundler 2.3.3
- cgi 0.3.1
- csv 3.2.2
- date 3.2.2
- did_you_mean 1.6.1
- digest 3.1.0
- drb 2.1.0
- erb 2.2.3
- error_highlight 0.3.0
- etc 1.3.0
- fcntl 1.0.1
- fiddle 1.1.0
- fileutils 1.6.0
- find 0.1.1
- io-console 0.5.10
- io-wait 0.2.1
- ipaddr 1.2.3
- irb 1.4.0
- json 2.6.1
- logger 1.5.0
- net-http 0.2.0
- net-protocol 0.1.2
- nkf 0.1.1
- open-uri 0.2.0
- openssl 3.0.0
- optparse 0.2.0
- ostruct 0.5.2
- pathname 0.2.0
- pp 0.3.0
- prettyprint 0.1.1
- psych 4.0.3
- racc 1.6.0
- rdoc 6.4.0
- readline 0.0.3
- readline-ext 0.1.4
- reline 0.2.8.pre.11
- resolv 0.2.1
- rinda 0.1.1
- ruby2_keywords 0.0.5
- securerandom 0.1.1
- set 1.0.2
- stringio 3.0.1
- strscan 3.0.1
- tempfile 0.1.2
- time 0.2.0
- timeout 0.2.0
- tmpdir 0.1.2
- un 0.2.0
- uri 0.11.0
- yaml 0.2.0
- zlib 2.1.1
これらのライブラリのバージョンアップがありました。
- The following bundled gems are updated.
- minitest 5.15.0
- power_assert 2.0.1
- rake 13.0.6
- test-unit 3.5.3
- rexml 3.2.5
- rbs 2.0.0
- typeprof 0.21.1
これらの bundled gems のアップデートがありました。
- The following default gems are now bundled gems.
- net-ftp 0.1.3
- net-imap 0.2.2
- net-pop 0.1.1
- net-smtp 0.3.1
- matrix 0.4.2
- prime 0.1.2
- debug 1.4.0
これらは bundled gems になりました。Bundler とともに利用するときは Gemfile に書くのを忘れないようにしてください。
(ko1)
カバレッジライブラリが測定を一時停止・再開できるようになった
- Coverage measurement now supports suspension. You can use
Coverage.suspendto stop the measurement temporarily, andCoverage.resumeto restart it. See [Feature #18176] in detail.
カバレッジの測定を一時停止できるようになりました。
oneshot coverage と組み合わせることで、特定のエンドポイントの処理に使われるコードを把握でき、Rails モノリスの分割の一助になるのでは? という構想で入りました。
カバレッジ測定の一時停止は昔からときどき要望が来ていた機能だったのですが、カバレッジライブラリの作者である自分がユースケースを理解できなかったため、導入を見送り続けてきました。
今回、クックパッド社内でも同様の需要があることがわかったので、雇い主の要望ならしょうがないですよね 実際に困っている人から詳しく話が聞けて納得できたので、ついに導入することにしました。
oneshot coverage が導入されたことで、昔よりもユースケースに妥当性が増したこともあります。
Ruby 3.1 の新機能なのでさすがにすぐにサービス投入にはならないのですが、そのうち記事や発表ができるといいなあ。
(mame)
Random::Formatter が random/formatter.rb に移された
- Random::Formatter is moved to random/formatter.rb, so that you can use
Random#hex,Random#base64, and so on without SecureRandom. [Feature #18190]
これまでは securerandomをrequireするとRandom#base64、Random#hexというメソッドが付け加わったようなのですが、本質的にSecureRandomとは無関係なので、これを'random/formatter'というライブラリに分けました。
# Ruby 3.0 (and works on 3.1) require 'securerandom' p Random.base64 #=> "cHn6rPPl75CwaTxNOL36tA=="
# Ruby 3.1 require 'random/formatter' p Random.base64 #=> "mczNU8TeKq+ihK3p2e2hzw=="
(ko1)
■非互換
rb_io_wait_readable,rb_io_wait_writableandrb_wait_for_single_fdare deprecated in favour ofrb_io_maybe_wait_readable,rb_io_maybe_wait_writableandrb_io_maybe_waitrespectively.rb_thread_wait_fdandrb_thread_fd_writableare deprecated. [Bug #18003]
これらの関数は deprecated になったようです。
(ko1)
■標準ライブラリの非互換
ERB.newの引数がキーワード引数のみになった
ERB#initializewarnssafe_leveland later arguments even without -w. [Feature #14256]
ERB.newに普通の引数を渡すと、廃止予告の警告が出るようになりました。
# Ruby 3.1では警告が出る ERB.new("src", nil, "%") #=> -e:1: warning: Passing safe_level with the 2nd argument of ERB.new is deprecated. Do not use it, and specify other arguments as keyword arguments. # -e:1: warning: Passing trim_mode with the 3rd argument of ERB.new is deprecated. Use keyword argument like ERB.new(str, trim_mode: ...) instead. # キーワード引数渡しなら警告が出ない ERB.new("src", trim_mode: "%")
より正確に言うと、Ruby 3.0でも-wコマンドラインオプションを渡すと警告が出ていました。
Ruby 3.1からはこの警告がデフォルトで出るようになりました。
歴史的に、ERB.new("src", nil, "%")という呼び出し方が長らく使われていたと思うのですが、おそらく次のバージョンくらいでエラーになると思われます。
これからは上記のようにキーワード引数で渡すようにしてください。
ちなみに第2引数はsafe_levelでしたが、safe_levelはすでにRuby 3.0からサポートされていないので、対応するキーワードはありません。
(mame)
古い debug.rb が debug.gem に変わった
lib/debug.rbis replaced withdebug.gem
実装もインターフェースも、完全に別のものに変わりました。万が一古いほうを使いたいときは、debug.gem のv0.2を使ってください。debug.gem については、あとで紹介します。
(ko1)
Kernel#ppの表示がデフォルトでターミナルの幅に合わせるようになった
Kernel#ppinlib/pp.rbuses the width ofIO#winsizeby default. This means that the output width is automatically changed depending on your terminal size. [Feature #12913]
オブジェクトをいい感じにフォーマットして出力するKernel#ppが、ターミナルの幅を考慮してフォーマットするようになりました。
画面幅が十分にあるときは一行で表示します。

画面幅を狭めて同じコードを実行すると、勝手に折りたたみます。

(mame)
Psych.loadのデフォルトの挙動が安全になった
- Psych 4.0 changes
Psych.loadassafe_loadby the default. You may need to use Psych 3.3.2 for migrating to this behavior. Bug #17866
Psychが3から4にメジャーバージョンアップしました。
Psych.loadが任意オブジェクトの読み込みをデフォルトで無効化したという、大きめの非互換があります。
少し詳しく説明します。
PsychはYAMLの読み書きをするライブラリです。
通常YAMLは、文字列や配列など、基本的なデータ構造を書くものですが、アプリケーションごとに拡張が可能になっています。
Psychはこの拡張を利用して、任意のRubyオブジェクトを表現することを許しています。
たとえば次のYAMLをPsych 3のPsych.loadで読み込むと、クラスFooのインスタンスが生成されていました。
--- !ruby/object:Foo {}
この挙動はしばしばセキュリティ問題につながることが知られています。
アプリケーションが信頼できないYAMLをロードすることで、変なオブジェクトが作られてしまい、そこから任意コード実行などいろいろなことに繋がる可能性があります。
任意オブジェクトの読み込みを無効化したPsych.safe_loadも提供されていたのですが、慣習的にPsych.loadが使われ続けているので、問題はなかなか止まりませんでした。
そこで今回、Psych.loadのデフォルトの挙動をPsych.safe_loadにしてしまうという変更がPsych 4でされました。
これによって、脆弱性問題は起きなくなります。
必然的に、YAMLの任意オブジェクトの読み込みに依存していたアプリケーションは動かなくなります。
Psych.loadをPsych.unsafe_loadに置き換えれば以前通りの挙動になりますが、脆弱性問題が復活する可能性があるので、それよりはpermitted_classesキーワード引数を使って必要なクラスのみを明示的に許可するほうがおすすめです。
class Foo; end p Psych.load("--- !ruby/object:Foo {}", permitted_classes: [Foo]) #=> #<Foo:0x00007f7e095b4530>
ちなみに、任意オブジェクトの読み込み以外にも、データ内のエイリアスも同様に無効化されました。
Psych.load(str, aliases: true)で有効化できます。
(mame)
■C API の更新
- Documented. [GH-4815]
C API についての Doxygen のドキュメントが大量に追加されました。
(ko1)
rb_gc_force_recycleis deprecated and has been changed to a no-op. [Feature #18290]
「このオブジェクト、もう要らんわ」というときに rb_gc_force_recycle(obj) と指定することで早めに解放を指示することができました。が、実はこの関数で要らんと言われても、長らく「何も触れないオブジェクト」として特別扱いしていました(次の sweep を待つ必要があった)。GC を実装しているといろいろ邪魔なので、いっそのこと何もしない関数にして、将来的には消したいね、としました(消すのはでも当分先かも)。
細かい話はこちらに詳しいです: rb_gc_force_recycle is deprecated in Ruby 3.1 - Peter Zhu
(ko1)
■実装の改善
クラス変数の読み込みにインラインキャッシュがついた
- Inline cache mechanism is introduced for reading class variables. [Feature #17763]
クラス変数の読み込み時にインラインキャッシュを使うことで、読み込みを高速化するようになりました。
クラス変数を更新するとき、具体的にどのクラス変数を使うのか、というのは実はソコソコ面倒な処理が入ります(仕様、もう覚えていないくらい面倒くさい)。つまり、遅いです。そこで、「以前この場所でクラス変数をあるクラスで読んだなら、同じクラスに対するクラス変数なら、きっと同じ場所のクラス変数を読むだろう」というのは自然な発想です。というわけで、そういう実装が入りました。
クラス変数は仕様が微妙だなぁ、と思って、目を向けないようにしていたんですが、Rails ではよく使うから、ということで入りました。ますます仕様と実装が複雑になって嫌だなぁ。多分、クラスやモジュールのインスタンス変数を使った方がわかりやすいと思うんだよなぁ。
(ko1)
instance_eval/exec で特異クラスの生成を遅延した
instance_evalandinstance_execnow only allocate a singleton class when required, avoiding extra objects and improving performance. [GH-5146]
obj.instance_eval{ ... } のブロックでメソッドを定義したら、どこに定義されるか知ってますか? 実は、obj.singleton_class に定義されます。
o = Object.new o.instance_eval do def foo = :foo end p o.foo() #=> :foo p foo() #=> undefined method `foo' for main:Object
これを実現するために、instance_eval を実行する前に毎回 singleton class を準備していたんですが、メソッド定義することって稀ですよね、だいたい self 差し替えたいだけですよね、という知見から、本当に必要なときまで singleton class の生成を遅延するようになりました。メソッド定義を行わない場合に、instance_eval/exec がすごく速くなったらしいですよ。
(ko1)
Struct のアクセサを高速化した
- The performance of
Structaccessors is improved. [GH-5131]
Structのメンバーへのアクセスが妙に遅かったので、だいたいインスタンス変数アクセス程度の性能になるくらいに速くしておきました。前からやりたかったんですよね。ついに重い腰を上げました。これで、匿名Struct(Feature #16986: Anonymous Struct literal)があれば、もっと便利に使えるんだけどなあ。
(ko1)
必須引数のみのメソッドを記述できるようにした(MRI 実装用)
mandatory_only?builtin special form to improve performance on builtin methods. [GH-5112]
いままでCで書いていたメソッドをRubyで書き直すって話をちょっとずつ進めているんですが、オプショナル引数を取るメソッドなどで、C に性能的に勝てないことがありました(オプショナル引数を代入したり、そこから取り出す Ruby のコードが動いてしまうため)。一番よく使われるのはオプショナル引数がない場合なので、そのときの性能をなんとかあげたい、ということで考えたのが必須引数しかうけない場合の特殊化したメソッドの定義方法を作りました。特殊化した場合と、一般的な場合の2つのメソッドを1つのメソッドに同居させています。
現状、これが必要になるのはだいぶ稀なので(メソッドの実体の実行時間が十分小さい場合に限る)、ちょっとずつ使って行こうと思います。
リリース直前にこれに絡む大きな設計ミスに気づいて修正にだいぶ時間がかかって、この原稿書くのがだいぶ遅れました。
ちなみにこれ、いわゆるオーバーロードを実装する話です。将来的には、もう少し Ruby の internal で活用していければと思っています。Ruby の言語仕様に出てくるかは微妙(多分、出てこない)。
(ko1)
可変長オブジェクトに対応したGC拡張が導入された(デフォルトではオフ)
- Experimental feature Variable Width Allocation in the garbage collector. This feature is turned off by default and can be enabled by compiling Ruby with flag
USE_RVARGC=1set. [Feature #18045] [Feature #18239]
新しい GC の拡張が入りました。といっても、まだデフォルトには有効になっておらず、Ruby をビルドするときにUSE_RVARGC=1 と指定する必要があります(例えば configure だとcppflags=-DUSE_RVARGC=1を追加)。
これまで、Rubyのオブジェクトを確保すると、40バイト(64bit CPUの場合、ポインタ長 8 バイトの5倍)の固定長のメモリを確保していました。このメモリをRVALUEといいます。GCの対象となるのは、このRVALUEです。Rubyオブジェクトは、もちろんこれよりも大きなメモリが必要になるので、どうするかというとmalloc()などで外部メモリを保持しておき、そこへのポインタを保持していました。外部メモリを持っている場合は、解放時にfree()などします。
これを、Variable Width Allocation(略してVWA)では、このRVALUEが40バイト固定長の制限をとって、必要に応じて大き目のメモリサイズを確保できるようにしたものです。なお、RVALUEに確保できるメモリサイズには制限があるので、それ以上確保したいとき(例えば、大きな文字列を確保するとき)は、これまで通り外部メモリを確保します。ある意味、GCのある言語処理系が用いる「ふつう」の方法です。
この方法の利点と欠点は次の通りです。
- 利点
- 外部メモリを確保しなくてよいので、RVALUE内に必要な情報がそろうことになり、メモリの局所性があがり、キャッシュヒット率が高くなり、性能向上が期待できる。
- オブジェクト解放時、外部メモリを解放する必要がなくなる(ことが多い)ため、解放処理のオーバヘッドが下がる。
- 欠点
- 確保するサイズごとにメモリ領域を作るので、フラグメンテーションが問題になる(コンパクションによって解決可能)。
- 今は40, 80, 160, ... と大雑把なメモリサイズでしか確保しないので、例えば84バイト確保しようとすると、160バイトのメモリ領域を確保するため、無駄が多い(より詳細なチューニングで解決可能)。
これまでは、フラグメンテーションの問題が気になって、なかなか導入を躊躇っていたんですが、ここ数年の compaction 実装の向上で、問題なくなった、のかなぁ。うまくいくといいですね。
そんなわけで、Ruby 3.1 で有効にするのは怖かったので、Ruby 3.2 で有効にできるように、Ruby 3.1 リリース後にはデフォルトで有効になる予定です(固定長で確保する方法をなくす予定)。
この拡張はShopifyの皆様の提案なのですが、すでにShopifyの一部で使っても問題なかった、という報告も受けています。今は、固定長のRVALUEという制限のもとでRubyインタプリタが構成されているので、この機能を有効にしてもいまいち性能は変わらないのですが、今後このデータ構造にあわせてインタプリタの抜本的な修正が入りそうなので、今後期待できそうですね。
(ko1)
■JIT
- Rename Ruby 3.0's
--jitto--mjit, and alias--jitto--yjiton non-Windows x86-64 platforms and to--mjiton others.
これまで、--jit というオプションは MJIT を有効にするオプションでしたが、Ruby 3.1 からは可能ならYJIT、そうでなければMJITを有効にするオプションとなりました。YJIT は Windows 以外での x86-64 プラットフォームで(多分)利用可能です。
(ko1)
MJIT
- The default
--mjit-max-cacheis changed from 100 to 10000.
これまで、デフォルトでは100メソッド(など)しかコンパイル結果を残していませんでしたが、この上限を10,000まで上げました。
- JIT-ed code is no longer cancelled when a TracePoint for class events is enabled.
class イベントをフックするための TracePoint では、コンパイルをキャンセルしなくなりました。
- The JIT compiler no longer skips compilation of methods longer than 1000 instructions.
1,000命令以上あるメソッド(など)を、スキップしなくなりました。
--mjit-verboseand--mjit-warningoutput "JIT cancel" when JIT-ed code is disabled because TracePoint or GC.compact is used.
--mjit-verbose と --mjit-warning で、JITしたコードが TracePoint や GC.compact で無効となったとき、"JIT cancel"と出力されるようになりました。
(ko1)
YJIT: New experimental in-process JIT compiler
New JIT compiler available as an experimental feature. [Feature #18229] See this blog post introducing the project.
- Disabled by default, use
--yjitcommand-line option to enable YJIT. - Performance improvements on most real-world software, up to 22% on railsbench, 39% on liquid-render.
- Fast warm-up times.
- Limited to macOS & Linux on x86-64 platforms for now.
Ruby 3.1 の目玉である YJIT です。実際に利用されているRailsのコードなどが高速化されるそうです。詳しい結果は開発した Shopify の皆さんの YJIT: Building a New JIT Compiler for CRuby — Development (2021) という記事をご覧ください。
YJITは、Ruby用JITコンパイラで、MJITと違いx86-64ネイティブコードを直接生成するJITコンパイラです。ある意味、ふつうのJITコンパイラですね。生成時には、Basic Block Versioning (BBV) というテクニックが利用されており、本当に必要な部分だけ、ネイティブコードに変換します。
例えば、次のようなプログラムについて考えます。
def foo a if a a + 1 else nil end end
メソッドfooが10回呼ばれると、これはよく利用されるメソッドだと確認してYJITがネイティブコードに「変換しながら実行します」。変換しながら実行、というのがキモです。これによって、「今実行している値」を確認しながら、コンパイルができるからです。他のJITコンパイラでは、パラメータの統計情報などをとっておき、それに応じてバックグラウンドでコンパイルする、とすることもありますが、YJITではコンパイル時にたまたま使った値を素直に利用します。そして、「ちょっとずつ」コンパイルしていきます。
さて、foo(10)という呼び出し時にコンパイルするとしましょう。このとき、aは10なので、if文はthen節を通ります。そして、aはFixnum(小さな数値)です。そこで、次のような機械語列を生成します。
- (1) もし a が falsy ならコンパイルをやりなおす
- (2) もし a が Fixnum(小さな数値)じゃなければ素直に
a.+(1)メソッドを呼び出し、メソッドの返値とする - (3) a (Fixnum) + 1 の計算を行い、メソッドの返値とする
具体的には、こんなコードが生成されました。
元のバイトコード: local table (size: 1, argc: 1 [opts: 0, rest: -1, post: 0, block: -1, kw: -1@-1, kwrest: -1]) [ 1] a@0<Arg> 0000 getlocal_WC_0 a@0 ( 2)[LiCa] 0002 branchunless 10 0004 getlocal_WC_0 a@0 ( 3)[Li] 0006 putobject_INT2FIX_1_ 0007 opt_plus <calldata!mid:+, argc:1, ARGS_SIMPLE>[CcCr] 0009 leave ( 7)[Re] 0010 putnil ( 3) 0011 leave ( 7)[Re] 生成された機械語: == BLOCK 1/3: 24 BYTES, ISEQ RANGE [0,4) ======================================= 5603dcbcd131: mov rax, qword ptr [r13 + 0x20] 5603dcbcd135: mov rax, qword ptr [rax - 0x18] 5603dcbcd139: mov qword ptr [rbx], rax 5603dcbcd13c: test qword ptr [rbx], -9 5603dcbcd143: je 0x5603e4bcd0a6 == BLOCK 2/3: 19 BYTES, ISEQ RANGE [4,9) ======================================= 5603dcbcd149: mov rax, qword ptr [r13 + 0x20] 5603dcbcd14d: mov rax, qword ptr [rax - 0x18] 5603dcbcd151: mov qword ptr [rbx], rax 5603dcbcd154: mov qword ptr [rbx + 8], 3 == BLOCK 3/3: 74 BYTES, ISEQ RANGE [7,10) ====================================== 5603dcbcd15c: test byte ptr [rbx], 1 5603dcbcd15f: je 0x5603e4bcd0f1 5603dcbcd165: mov rax, qword ptr [rbx] 5603dcbcd168: sub rax, 1 5603dcbcd16c: add rax, qword ptr [rbx + 8] 5603dcbcd170: jo 0x5603e4bcd0f1 5603dcbcd176: mov qword ptr [rbx], rax 5603dcbcd179: mov rcx, qword ptr [r13 + 0x20] 5603dcbcd17d: mov eax, dword ptr [r12 + 0x24] 5603dcbcd182: not eax 5603dcbcd184: test dword ptr [r12 + 0x20], eax 5603dcbcd189: jne 0x5603e4bcd112 5603dcbcd18f: mov rax, qword ptr [rbx] 5603dcbcd192: add r13, 0x40 5603dcbcd196: mov qword ptr [r12 + 0x10], r13 5603dcbcd19b: mov rbx, qword ptr [r13 + 8] 5603dcbcd19f: mov qword ptr [rbx], rax 5603dcbcd1a2: jmp qword ptr [r13 - 8]
ここで生成されるコードは、a が 10 の時(Fixnumのとき)の特別なコードです。そのため、a が falsy だと、「コンパイルをやり直す」ということが起きます。アセンブラ中の je 0x5603e4bcd0a6、とか je 0x5603e4bcd0f1 がそれにあたります(やり直すぞ、というところにジャンプしています)。
試しに、この後でfoo(nil)と呼んでみます。
== BLOCK 1/5: 24 BYTES, ISEQ RANGE [0,4) ======================================= 55c00fbaf131: mov rax, qword ptr [r13 + 0x20] 55c00fbaf135: mov rax, qword ptr [rax - 0x18] 55c00fbaf139: mov qword ptr [rbx], rax 55c00fbaf13c: test qword ptr [rbx], -9 55c00fbaf143: je 0x55c017baf0a6 == BLOCK 2/5: 19 BYTES, ISEQ RANGE [4,9) ======================================= 55c00fbaf149: mov rax, qword ptr [r13 + 0x20] 55c00fbaf14d: mov rax, qword ptr [rax - 0x18] 55c00fbaf151: mov qword ptr [rbx], rax 55c00fbaf154: mov qword ptr [rbx + 8], 3 == BLOCK 3/5: 74 BYTES, ISEQ RANGE [7,10) ====================================== 55c00fbaf15c: test byte ptr [rbx], 1 55c00fbaf15f: je 0x55c017baf0f1 55c00fbaf165: mov rax, qword ptr [rbx] 55c00fbaf168: sub rax, 1 55c00fbaf16c: add rax, qword ptr [rbx + 8] 55c00fbaf170: jo 0x55c017baf0f1 55c00fbaf176: mov qword ptr [rbx], rax 55c00fbaf179: mov rcx, qword ptr [r13 + 0x20] 55c00fbaf17d: mov eax, dword ptr [r12 + 0x24] 55c00fbaf182: not eax 55c00fbaf184: test dword ptr [r12 + 0x20], eax 55c00fbaf189: jne 0x55c017baf112 55c00fbaf18f: mov rax, qword ptr [rbx] 55c00fbaf192: add r13, 0x40 55c00fbaf196: mov qword ptr [r12 + 0x10], r13 55c00fbaf19b: mov rbx, qword ptr [r13 + 8] 55c00fbaf19f: mov qword ptr [rbx], rax 55c00fbaf1a2: jmp qword ptr [r13 - 8] == BLOCK 4/5: 24 BYTES, ISEQ RANGE [0,4) ======================================= 55c00fbafa9d: mov rax, qword ptr [r13 + 0x20] 55c00fbafaa1: mov rax, qword ptr [rax - 0x18] 55c00fbafaa5: mov qword ptr [rbx], rax 55c00fbafaa8: test qword ptr [rbx], -9 55c00fbafaaf: jne 0x55c00fbaf149 == BLOCK 5/5: 52 BYTES, ISEQ RANGE [10,12) ===================================== 55c00fbafab5: mov qword ptr [rbx], 8 55c00fbafabc: mov rcx, qword ptr [r13 + 0x20] 55c00fbafac0: mov eax, dword ptr [r12 + 0x24] 55c00fbafac5: not eax 55c00fbafac7: test dword ptr [r12 + 0x20], eax 55c00fbafacc: jne 0x55c017baf7b8 55c00fbafad2: mov rax, qword ptr [rbx] 55c00fbafad5: add r13, 0x40 55c00fbafad9: mov qword ptr [r12 + 0x10], r13 55c00fbafade: mov rbx, qword ptr [r13 + 8] 55c00fbafae2: mov qword ptr [rbx], rax 55c00fbafae5: jmp qword ptr [r13 - 8]
これまで通ってこなかったパスが増えたので、再度コンパイルされました(既存の機械語列に追加されました)。ブロック 4/5 とブロック 5/5 が増えたのがわかるでしょうか。ちょっと中身をよく知らないんですが、これは 4/5 が代わりにエントリーポイントになり、a が truthy だったら 2/5 にジャンプ、となっているのかな。そんな気がします。つまり、1/5 が 4/5 にバージョンアップしてるわけですね。
ちなみに、各ブロックは必ずしも隣り合ったメモリに存在するわけではありません。新しいバージョンが生成されると、可能なら既存のコードへジャンプするようなコードが生成されます。この配置するメモリ領域は、Rubyインタプリタ起動時にドーンと確保されます。--yjit-exec-mem-size という起動オプションで制御でき、デフォルトは 256MB です。
詳しい人は読むとわかると思いますが、最適化の余地がまだまだ死ぬほどあるので、今はほぼテンプレートベースの置き換えですが、さらに性能向上を進めることができるような気がします。また、ARM の対応もすると言ってました。楽しみですね。
なお、この機械語の表示を確かめるには、次のようなプログラムで行うことができます。ただし、Ruby のビルド時に(configure 時に)libcapstone-dev という、逆アセンブルを行うライブラリが必要です(Ubuntu なら apt install libcapstone-dev で入りました)。
def foo a if a a + 1 else nil end end 20.times{|i| p foo(i) asm = RubyVM::YJIT.disasm(method(:foo)) if asm puts asm break end } p foo(nil) puts RubyVM::YJIT.disasm(method(:foo))
RubyVM::YJIT.disasm(method(:foo)) が、どのような機械語でコンパイルされているか、という結果が返ります。10回目にコンパイルされるので、それまでは nil が返ります。
ネイティブコードに直接コンパイルするため、一般的にメンテナンスが困難になります。Shopify の皆様なら、きっと継続してメンテナンスしてくれるだろうという期待もあって、今回 YJIT が導入されました。
この辺を弄ってた人間としてはいろいろ考えることはあるのですが、余白が少なすぎるようです。とりあえず、速さは正義。
(ko1)
■静的解析
RBS
Rubyコードの型を表現する言語RBSが拡張されました。 ジェネリクスのbounded型が導入されこと、ジェネリックな型エイリアスが書けるようになったこと、の2点です。 ただ、まだTypeProfもSteepもこの新記法に対応していないので、現時点で使う意味はありません。今後の布石です。
- rbs collection has been introduced to manage gems’ RBSs.
rbs collectionという機能が追加されました。 メジャーなgemに対するRBSを集めたリポジトリgem_rbs_collectionから自分のプロジェクトで必要なRBSファイルをフェッチする機能(正確に言うと、現在の実装ではリポジトリ全体をcloneした上で必要なファイルのみをコピーする)や、Gemfileで表現されていないdefault gemへの依存を表現する機能などがあります。 詳しくは作者のpockeさんの解説記事をご覧ください。
- Many signatures for built-in and standard libraries have been added/updated.
- It includes many bug fixes and performance improvements too.
他にも、多くの組み込みライブラリの型が追加・改善された、高速化のためにパーサがC言語で書き直された、など、さまざまな改善がされています。
(mame)
TypeProf
- Experimental IDE support has been implemented.
- Many bug fixes and performance improvements since Ruby 3.0.0.
TypeProfは、TypeProf for IDEという実験的なIDEサポートが導入されました。
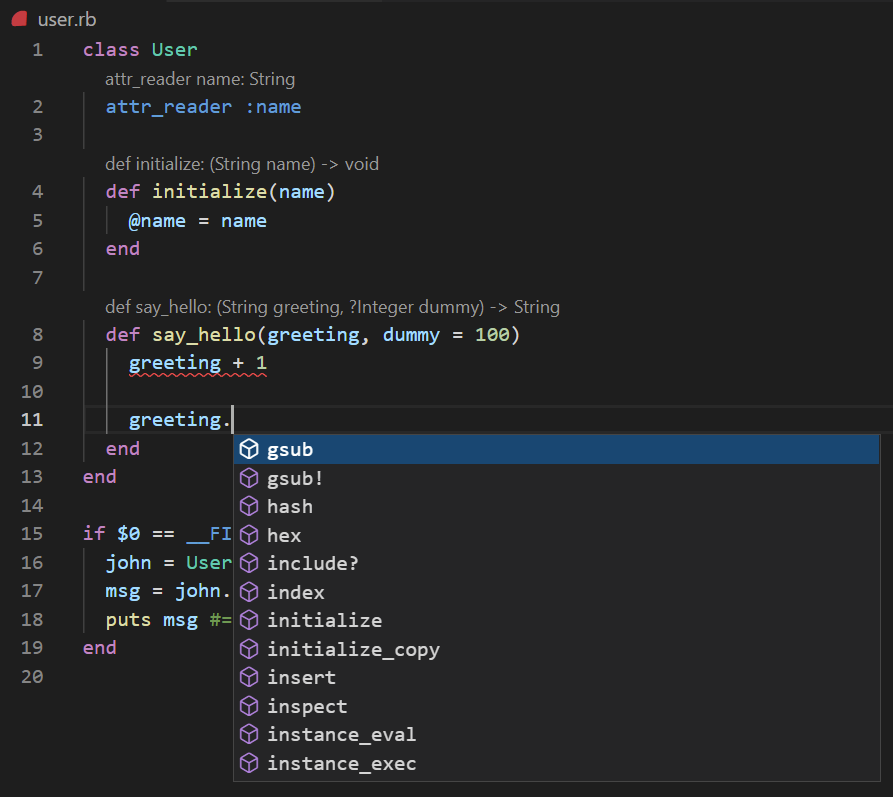
メソッド定義の上に推定された型シグネチャのRBSで灰色で表示されます。 また、型エラーに赤線が出たり、補完が出たりしている様子もわかると思います。
詳しくはRubyKaigi Takeout 2021のキーノートで話したので、そちらの動画や資料をご覧ください。
(mame)
■デバッガ
- A new debugger debug.gem is bundled. debug.gem is a fast debugger implementation, and it provides many features like remote debugging, colorful REPL, IDE (VSCode) integration, and more. It replaces
lib/debug.rbstandard library. rdbgcommand is also installed intobin/directory to start and control debugging execution.
debug.gem という、Ruby 用デバッガを書き直しました。2021年は、笹田はこの仕事しかやっていないってくらい時間を使って実装しました。ちょっと時間を使いすぎた。
(2021/12/27 追記:もう少し詳しい紹介記事を書きました)
細かい話は GitHub のドキュメントを読んでいただくとして、他のデバッガに比べて次のようなメリットがあります。
- 速い: 行ブレイクポイントを設定しても、速度低下は一切ありません。
- リモートデバッグにネイティブに対応しています。
- UNIX domain socket
- TCP/IP
- 標準で IDE などリッチなフロントエンドにつながります。
- VSCode/DAP (VSCode rdbg Ruby Debugger - Visual Studio Marketplace)
- Chrome DevTools/CDP
- 柔軟にデバッガを実行できます
- rdbg を利用:
rdbg target.rb ruby -r:ruby -r debug/start target.rb- require:
require 'debug/start'とかいろいろ
- rdbg を利用:
- その他
- マルチプロセスプログラミング(fork追跡)に対応(多分)
- Threadプログラミングのデバッグに対応(多分、だいたい)
- Ractorプログラミングのデバッグに対応、したい(まだできていない)
- Control+C で任意の場所でプログラムを停止
- バックトレースに引数を表示
- レコーディング&リプレイ機能とか、なんか面白い機能いろいろ


発表資料など:
- The Art of Execution Control for Ruby's Debugger by Koichi Sasada - RubyKaigi Takeout 2021
- Sessions | RubyConf 2021
- GinzaRails での発表動画
Rubyのデバッガって「いざというときのツール」という感じで、あんまり使われていない印象をもっているんですが、気軽なコードリーディングとかでも使ってもらえるように、進化させていきたいなぁと思っています。
もともとは、既存のデバッガのアーキテクチャではRactor対応できないなー、デバッガないと並列プログラミング厳しいよなぁ、と思って作り始めたんですが、結局まだ Ractor 対応できていないんですよねぇ。
ちなみに、rdbg コマンドがインストールされます(リモートデバッガのクライアントなどに使います)。gdb みたいに rdb って名前にしたかったんですが、あまりに RDB (Relational Database) に近いだろうってことで却下されました。
(ko1)
■error_highlight
- A built-in gem called error_highlight has been introduced. It shows fine-grained error locations in the backtrace. (略)
NameErrorが起きたときに、その例外が起きた位置をエラーメッセージで表示するようになりました。

詳しくは別の記事で解説しているので、そちらもご覧ください。
(mame)
■IRBに自動補完とドキュメント表示が実装された
- The IRB now has an autocomplete feature, where you can just type in the code, and the completion candidates dialog will appear. You can use Tab and Shift+Tab to move up and down.
- If documents are installed when you select a completion candidate, the documentation dialog will appear next to the completion candidates dialog, showing part of the content. You can read the full document by pressing Alt+d.
IRBに自動補完やドキュメント表示の機能が実装されました。"Hello". と入力するだけで、String のメソッドが候補として表示されます。
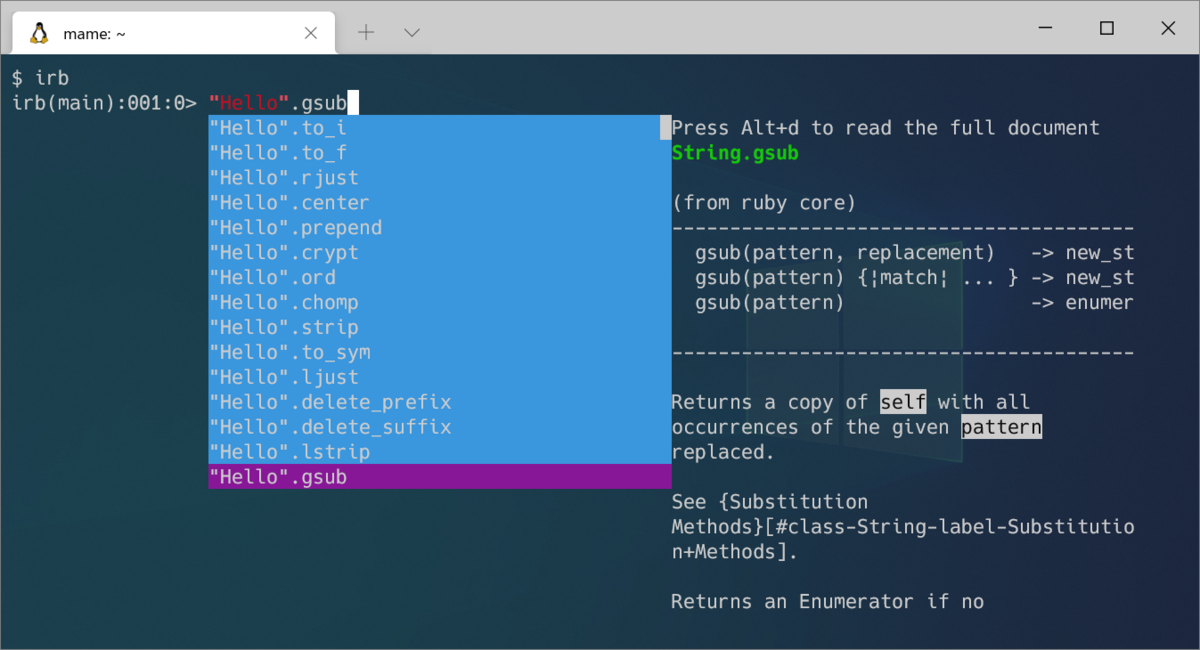
補完自体はこれまでもあったのですが、タブキーを押さないと候補が出てこないので「半自動補完」みたいな感じでした。今回からは、"Hello".と入力するだけでポップアップっぽく出てきます。
タブキーとShift+タブキーで候補を選び、エンターキーで補完を決定します。また、選択中の候補について、ドキュメントがあれば右側に表示するようにもなっています(上の画面参照)。
なお、まだ少し荒削りなので、いじっていると画面が壊れることもあるかもしれません。irb --noautocomplete と起動すれば、自動補完を無効にできます。
(mame)
■その他の変更
objspace/traceライブラリの追加
- lib/objspace/trace.rb is added, which is a tool for tracing the object allocation. Just by requiring this file, tracing is started immediately. Just by
Kernel#p, you can investigate where an object was created. Note that just requiring this file brings a large performance overhead. This is only for debugging purposes. Do not use this in production. [Feature #17762]
Rubyで込み入ったバグを追っているとき、「このオブジェクトが確保された場所が知りたい」ということがときどきあると思います。 それを可能にする便利ライブラリが追加されました。
require "objspace/trace" #=> objspace/trace is enabled # objを4行目で確保する obj = Object.new p obj #=> #<Object:0x00007f2063126a80> @ test.rb:4
require "objspace/trace"によってオブジェクト生成の追跡を有効化します(有効化されたという警告も出ます)。
その上で、4行目でObject.newによって作ったオブジェクトをKernel#pに渡すと、@ test.rb:4という表示が出ているのがわかると思います。
注意点としては、require "objspace/trace"を呼ぶ前のオブジェクトの確保位置は特定できません。
また、このオブジェクト生成の追跡はそれなりに遅いし、メモリも消費します。
デバッグ専用のものなので、基本的にプロダクションでは使わないでください。
実は、この機能自体は昔からあります。
追跡を有効化するのはObjectSpace.trace_object_allocations_startで、オブジェクトを確保した位置のファイル名を得るのがObjectSpace.allocation_sourcefile(obj)、行番号を得るのがObjectSpace.allocation_sourceline(obj)です。
これらのAPI名が極端に長いのは意図的でした。
Rubyには「気楽に使うべきでないAPI名は長くして気楽に使わせないようにする」という不文律があり、それに従っています。
ただ、デバッグ用途のものであることを考えるとあまりに不便すぎたので、objspace/traceを導入しました。
ko1注: これらの長い API は、自分で便利メソッドを定義して使ってね、という意図でこういう名前にしていました。
反動で、極端に短く使えるようになっています。
require "objspace/trace"をしてpを呼ぶだけで位置が表示されます。
ただ、pの意味を変えるのはやりすぎという声もあり、リリース後ももし評判が悪ければ変更するかもしれません(あくまでデバッグ用なので、互換性はそれほど重要でないと考えています)。
なお、require "objspace/trace"を書いたままうっかりコミットしてしまうリスクがあるということで、requireしただけで警告が出るようにしました。
(mame)
ファイナライザ内で警告が起きたらバックトレースを表示するようになった
- Now exceptions raised in finalizers will be printed to
STDERR, unless$VERBOSEisnil. [Feature #17798]
オブジェクトのファイナライザの内で補足されない例外が投げられた場合、バックトレースが表示されるようになりました。
obj = Object.new # オブジェクトにファイナライザを登録する ObjectSpace.define_finalizer(obj, proc { # 例外を投げる raise }) # ファイナライザを登録したオブジェクトへの参照を消す obj = nil # GCを起こす(注:オブジェクトが必ず回収されるとは限らない) GC.start #=> <internal:gc>:34: warning: Exception in finalizer #<Proc:0x00007f46a527a4a0 test.rb:4> # test.rb:6:in `block in <main>': unhandled exception # from <internal:gc>:34:in `start' # from test.rb:13:in `<main> # エラーは表示されるけれど実行はそのまま続く puts "Hello" #=> Hello
バックトレースが表示されるだけで、実行自体は続くことに注意してください。
あくまで、エラーが出力されるだけです。Thread.report_on_exception = true と同じようなものと考えてください。
これまでは、ファイナライザ内で例外が投げられても黙殺されていました。 なので、もしその挙動に依存しているコードがどこかにあると、GCが走るときに何か出力されるという変化があるかもしれません。 ファイナライザなんか使わないのがオススメです。
(mame)
ruby -run -e httpd が URL を表示するようになった
ruby -run -e httpddisplays URLs to access. [Feature #17847]
簡易HTTPサーバであるruby -run -e httpdコマンドを実行すると、https://127.0.0.1:8080のようなループバックURLが出力されるようになりました。
$ ruby -run -e httpd [2021-12-21 20:25:28] INFO WEBrick 1.7.0 [2021-12-21 20:25:28] INFO ruby 3.1.0 (2021-11-17) [x86_64-linux] [2021-12-21 20:25:28] INFO WEBrick::HTTPServer#start: pid=105322 port=8080 [2021-12-21 20:25:28] INFO To access this server, open this URL in a browser: [2021-12-21 20:25:28] INFO http://127.0.0.1:8080 [2021-12-21 20:25:28] INFO http://[::1]:8080
何かと便利ですね。
(mame)
ruby -run -e colorize でターミナル上での Ruby コードの色つけ表示ができるようになった
- Add
ruby -run -e colorizeto colorize Ruby code usingIRB::Color.colorize_code.
irb の色つけ機能を使って、Ruby コードに色を付けて表示するだけのちょっとした機能が追加されました。

(mame)
■おわりに
Ruby 3.1の非互換や新機能を紹介してきました。ここで紹介した以外でも、バグの修正や細かな改善が行われています。お手元の Ruby アプリケーションでご確認いただければと思います。
Ruby 3.1では、冒頭で述べた通り、互換性を最大限に考慮するため、あまり大きな変更はありませんでしたが、Ruby 3.2では(3.1で我慢した分もふくめて)、いろいろと変更される予定です。これからも進化し続ける Ruby にご期待ください。
なにはともあれ、まずは新しい Ruby を楽しんでください。ハッピーホリデー!